

 不懂代码?有口就行!百度发布三大AI开发工具,李彦宏:人人都是开发者
不懂代码?有口就行!百度发布三大AI开发工具,李彦宏:人人都是开发者
描述
电子发烧友网报道(文/梁浩斌)只要会说话,就能成为开发者?在4月16日的Create 2024百度AI开发者大会上,百度创始人、董事长兼首席执行官李彦宏提出了一个观点:“未来,自然语言将成为新的通用编程语言,你只要会说话,就可以成为一名开发者,用自己的创造力改变世界。”
那么要如何实现“人人都是开发者”的世界?李彦宏在大会上也给出了他的答案。
大模型和生成式AI将彻底改变开发者群体
以往,开发者的门槛都普遍较高,需要学习计算机编程语言,才能通过代码来创造一个应用。而在AI大模型的发展下,计算机能够理解自然语言,并将其转换成对应的代码而构建一个应用。
于是,在强大的AI大模型基础下,自然语言就将成为新的通用编程语言。开发者不需要具备写代码能力、不需要编程能力,只需要将应用需求用自然语言表达出来,就能创造一个应用。开发门槛降低的同时,也就大幅提高了生产力。
而这并不是未来,在今天AI就已经开始帮助企业开发者进行工作。基于文心大模型的智能代码助手Comate,不仅支持100多种语言和所有主流IDE平台,可以推荐代码、生成代码注释、查找代码缺陷、给出优化方案。此外,它还可以深度解读代码库、关联私域知识生成新的代码。

李彦宏透露,在推出一年多的时间里,Comate已经走入了喜马拉雅、三菱电梯、软通动力等上万家企业。它的生成的代码采纳率达到了46%,百度每天新增的代码中,已经有27%是由Comate生成的。
就如同短视频的兴起,其中也得益于视频制作的便利性,短视频平台提供了丰富的视频制作工具,摆脱了以往视频制作需要专业软件的门槛,让每个人都能成为视频创作者。
如今生成式AI,也为应用开发带来了革命性的变化,开发应用不再需要代码、编程等能力,在AI的帮助下开发应用就像拍短视频一样简单,只需要创意和灵感,每个人都能成为开发者。
未来AI原生应用发展趋势:MoE、小模型、智能体
“大语言模型本身并不直接创造价值,基于大模型开发出来的AI应用,才是能够真正满足市场需求的东西”。
关于AI原生应用,李彦宏分享了基于百度过去一年的实践,总结出的基于大模型开发AI原生应用的具体思路和工具。

首先,李彦宏认为,未来大型的AI原生应用基本都是MoE架构。MoE是指大小模型混用,未来AI应用不会依赖单一模型来解决所有问题,但其中的难点在于,什么时候调用小模型、什么时候调用大模型、什么时候不调用模型,这些策略都需要针对应用的不同场景做匹配。
其次,另一个趋势是小模型。“小模型推理成本低,响应速度快,在一些特定场景中,经过SFT精调后的小模型,它的使用效果可以媲美大模型。”
据介绍,百度通过大模型,压缩蒸馏出来一个基础模型,然后再用数据去训练,这要比基于开源模型训练出的模型效果更好、速度更快、成本更低。而百度也为此推出了Speed,Lite、Tiny三个轻量模型。
第三个趋势是智能体,智能体的机制包括理解、规划、反思和进化,令机器像人一样思考和行动,完成自我迭代和进化,不断催生出大量的新应用。
三大AI原生应用开发工具“开箱即用”
在AI原生应用MoE、小模型、智能体的趋势下,百度就提供了智能体开发工具AgentBuilder、AI原生应用开发工具AppBuilder和各种尺寸的模型定制工具ModelBuilder,来为AI原生应用提供完备的工具。

其中,AgentBuilder是一款面向所有人的开发工具,用户只需在设定中明确智能体所需具备的能力,系统就能自动完成其余工作。如果要让智能体更加专业,则需要将资料添加到知识库,让智能体自动进行更新;或是添加一些第三方的服务工具,让智能体具备更全面的功能。
AppBuilder作为AI原生应用开发工具,为了降低开发门槛,百度在AppBuilder中提前封装和预置了开发AI原生应用所需的各种组件和框架,通过自然语言开发AI原生应用,开发步骤最快被压缩到三步。
比如在华北电力大学的AI助理应用中,利用AppBuilder创建的第一步是为应用设置名称、简介、头像等基本信息;第二步是通过自然语言在角色令中描述具体要求,包括任务、组件能力、要求与限制;第三步是插入自定义的图书借阅查询、课表查询、学生成绩查询等组件,再加入开场白就完成了应用的构建。
而ModelBuilder则是一款面向专业开发者的工具,可以根据开发者的需求定制任意尺寸的模型。同时,根据细分场景对模型进一步精调SFT,掌握模型精调方法也是用好大模型的关键。
ModelBuilder可以基于文心大模型,根据需求裁剪出适合不同场景的小模型,同时支持精调和post pretrain。而ModelBuilder预置了包括ERNIE3.5和ERNIE4.0的大模型,以及ERNIE Speed、Lite、Tiny三个轻量级大模型,另外还有两个垂直场景的模型:适合角色扮演的ERNIE Character,以及适合对话或问答场景中的外部工具使用和业务函数调用的ERNIE Functions。甚至还支持国内外多达77个第三方主流模型,是国内拥有大模型数量最多的开发平台。
前面也提到,通过大模型压缩出的小模型,效果要比基于开源模型训练出的模型更好。
李彦宏在这里也提出了一个观点:“大家以前用开源觉得开源便宜,其实在大模型场景下,开源是最贵的。所以开源模型将会越来越落后。”
文心大模型推理成本下降99%
文心一言自去年3月发布以来,就成为国产大语言模型应用的代表之一。据介绍,截至目前文心一言的用户数突破了2亿,API日均调用量也突破了2亿,服务的客户数达到了8.5万,利用千帆平台开发的AI原生应用数超过了19万。
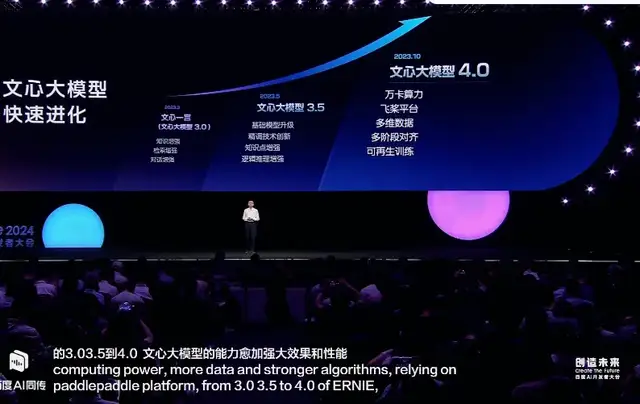
作为文心一言背后的支撑,文心大模型在过去一年里经历了从3.0版本到3.5,再到4.0的进化。而近几个月来,文心大模型在代码生成、代码解释、代码优化等通用能力方面实现了进一步的显著提升,达到国际领先水平。
在这次开发者大会上,百度还正式推出了文心大模型4.0的工具版。所谓工具版,即提供了文档问答、数据分析、代码执行等功能,通过自然语言交互就能实现对复杂数据和文件的处理和分析。
同时,相比文心大模型3.0,目前4.0版本的算法训练效率提升到了原来的5.1倍,周均训练有效率达到98.8%,推理性能提升了105倍,推理的成本降到了原来的1%,也就是成本下降了99%。
据称,成本的下降,得益于百度在芯片、框架、模型、应用这四层架构上有着全栈的布局,通过端到端优化,来降低大模型的使用成本。
视觉大模型的最大应用场景是自动驾驶
大语言模型之外,多模态大模型,比如文字、图片、语音、视频等多模态的融合,是基础模型的长期发展方向,是通往AGI的必经之路。李彦宏判断,其中视觉大模型最大的应用场景将会是自动驾驶。
在自动驾驶方面,百度实际上也是国内最早布局的厂商之一。基于超过1亿公里的、中国复杂城市道路测试里程数据,百度训练出来了Apollo视觉感知大模型。它具备检测、跟踪、理解、建图四大基础能力。这让百度拥有了更智能、适应性更强、更安全的自动驾驶方案。
而在商业落地上,百度旗下的自动驾驶出行平台萝卜快跑已经在北京、上海、广州、深圳、重庆、武汉等多个城市开放运营Robotaxi,部分还已经实现无安全员运行。
今年春节后,萝卜快跑将武汉的服务区域从长江北岸延伸到了南岸,在武汉的部分区域,萝卜快跑已经实现了7X24小时的全天候运营,还计划年内在武汉部署1000台无人驾驶车辆。

“这是自动驾驶走向真正商业化的一个标志性事件,它不再仅仅是区域性的示范,而是进入到了城市级应用示范的新阶段。萝卜快跑在武汉覆盖了3000多平方公里、770万人口,是全球范围内最大规模的自动驾驶运营区域。”
写在最后
AI被认为是未来人类生产力提升的关键技术,从开发者的角度,百度文心大模型系列以及这次推出的三个开发工具,大大降低了应用开发的门槛,真正实现了“人人都能成为开发者”的愿景。而通过更多人的想象力和创造力,通过AI开发的应用,也将很大程度上提升各行各业的生产力。
正如李彦宏所说:“今天,人人都可以成为开发者。而未来,也必将是一个由开发者一起创造出来的未来!”
-
百度何俊杰发表《智能体:创造AI原生未来》主题演讲2024-04-18 1686
-
Create 2024百度AI开发者大会 带来了哪些新技术?2024-04-17 2055
-
2024百度Create AI开发者大会:李彦宏将展示“开箱即用”的三大神器2024-04-11 1953
-
AI应用落地反馈驱动科技创新,技术创新驱动行业增长——百度Create AI开发者大会2023-01-12 4802
-
百度CreateAI开发者大会2023-01-10 1988
-
百度AI开发者大会:持续探索元宇宙2021-12-29 2402
-
百度ai开发者大会2021:携手NVIDIA持续探索元宇宙2021-12-28 2352
-
百度AI大会,李彦宏演讲遭观众泼水后淡定继续演讲2019-08-07 3395
-
新闻 百度AI大会李彦宏被泼水 抖音海外版TikTok正接受调查2019-07-04 3714
-
百度AI开发者大会,看百度AI是如何修成正果2018-07-05 1464
-
百度AI开发者大会—2017最伟大的AI宣言2017-07-07 1386
-
2017百度AI开发者大会大彩蛋,李彦宏乘坐自动驾驶汽车,后来交警来了!2017-07-06 3240
全部0条评论

快来发表一下你的评论吧 !
