

 免费时代到来!价格战带领AI大模型走出商业化困局?
免费时代到来!价格战带领AI大模型走出商业化困局?
描述
电子发烧友网报道(文/梁浩斌)大模型厂商彻底疯狂!电商618大促刚刚开始,大模型厂商就开始轮番疯狂降价。每千Tokens的价格,从过去几分钱,再下降一个数量级至几厘,甚至还有直接开放大模型全面免费试用。
大模型进入免费时代
5月21日,阿里云宣布通义千问4款商业化模型和5款开源模型大降价,其中GPT-4级别的主力模型Qwen-Long价格直降97%,从此前API输入0.02元/千Tokens,降价至0.0005元/千Tokens;API输出从0.02元/千Tokens,也降了90%到0.002元/千Tokens。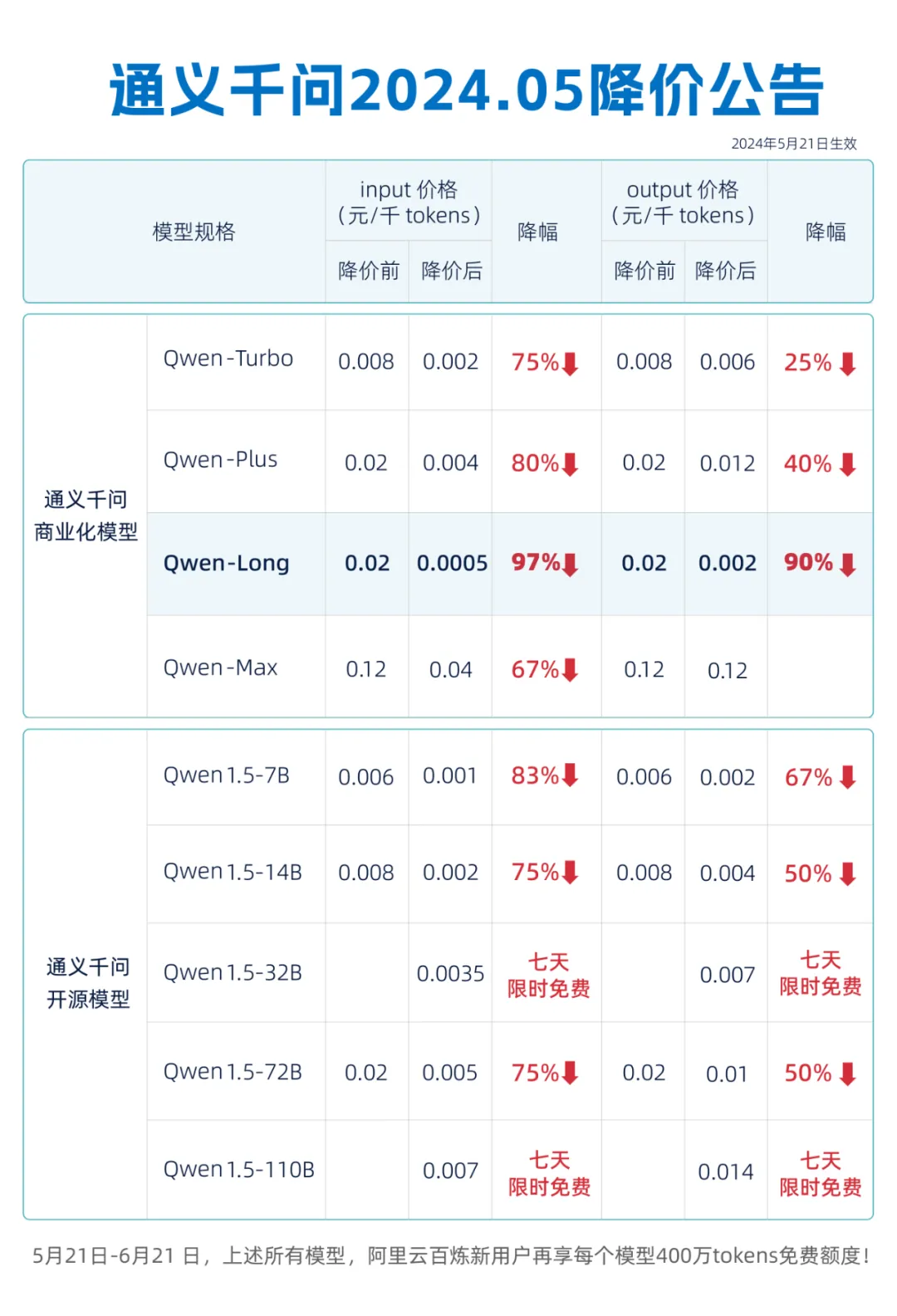
Token在自然语言处理中是指文本被分割成的最小单元或标记,通常1个中文词语、英文单词、数字、符号计为 1 个Token,由于不同模型采用的分词器不同,同一段文字可能分成不同数量的Tokens,比如在某个模型中,“使用者”被分为一个Tokens,但“大模型”就被分为“大”和“模型”两个Tokens。粗略估算,1Tokens可以理解为相当于1.5个中文汉字。
然而就在上午通义千问降价之后,下午百度言简意赅,在公众号上发文宣布:文心大模型两大主力模型全面免费,立即生效!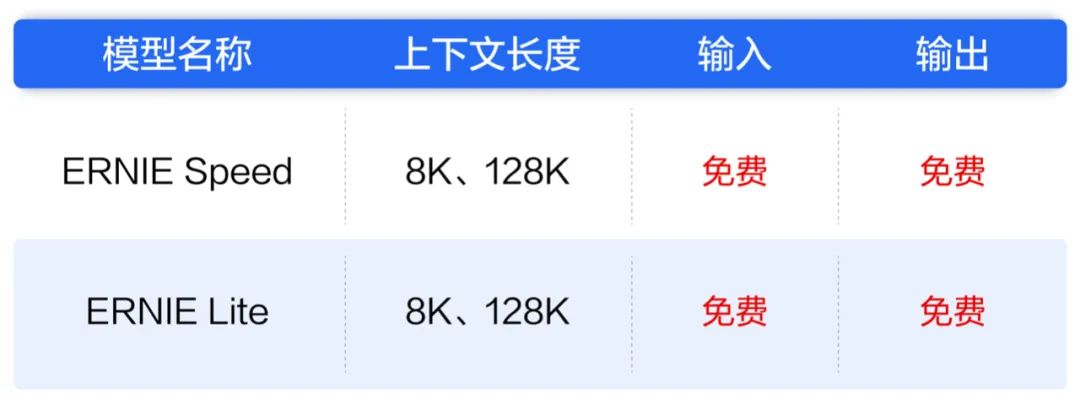
这次免费的两大主力模型分别是ERNIE Speed和ERNIE Lite,上下文长度均支持8K、128K,均为轻量级大模型。其中ERNIE Speed适用于自然语言处理任务中的多种场景,如文本分类、命名实体识别、语义匹配等,在智能客服、搜索引擎、智能推荐等领域的应用表现突出,在阅读理解、close-book问答、创作与续写等复杂任务上,也能达到甚至超越千亿大模型的效果。
而ERNIE Lite则适合搭载在低算力的AI加速卡上处理推理任务,应用于检索、推荐、意图识别等高并发、低延时等场景。
在文心大模型之后,5月22日,科大讯飞也宣布旗下讯飞星火Lite API永久免费开放,此前该模型版本价格为0.018元/千Tokens。Spark Lite同样是轻量级大语言模型,支持在线联网搜索功能,适用于低算力推理与模型精调等定制化场景。

除了轻量级大模型之外,在顶配的Spark 3.5 Max版本上,价格也降到0.21-0.3元/万Tokens,即0.021-0.03元/千Tokens,这个价格相比文心一言和通义千问同级别大模型也要更低。比如文心一言的ERNIE-4.0输入、输出均为0.12元/千Tokens;通义千问Qwen-Max输入0.04元/千Tokens,输出0.12元/千Tokens。
这一轮大模型降价,可以追溯到5月初。幻方量化旗下深度求索(DeepSeek)在5月6日正式开源第二代MoE模型DeepSeek-V2,而其API的定价为输入1元/百万Tokens,输出2元/百万Tokens,算下来大概是0.001-0.002元/千Tokens,价格几乎是GPT-4-Turbo的百分之一。
5月11日,智谱大模型官宣降价,其中个人版 GLM-3Turbo模型产品的API调用价格从0.005元/千Tokens,降至0.001元/千Tokens;最顶配的GLM-4和GLM-4V价格也来到0.1元/千Tokens。
字节跳动旗下的云服务平台火山引擎,在5月15日推出了豆包大模型家族,其中豆包主力模型的推理输入定价仅为0.0008元/千Tokens,当时火山引擎表示,这个价格要比行业便宜99.3%。
但大模型内卷的趋势,并不是“中国特色”,5月13日,OpenAI推出了新一代的大模型GPT-4o,除了性能上的大幅提升之外,更重磅的消息是该新模型将全部功能免费使用。
此前OpenAI仅免费开放GPT-3.5供用户使用,而GPT-4是要付费使用的。但在GPT-4o发布后,不仅性能上超越GPT-4,而且还免注册开放使用。当然,免费用户使用GPT-4o只能每三小时使用十次,超过10次将自动降级至GPT-3.5。
与此同时,商业用户方面,GPT-4o的API调用价格也相比GPT-4 Turbo全面下降50%。
所以,大模型的全面降价,甚至是免费,已经成为目前全球AI行业的趋势。
价格战是“良药”还是“双输”?
在互联网行业,疯狂烧钱的零和博弈打法已经司空见惯,从电商到外卖、再到共享单车,在行业发展初期都依靠低价打开市场规模。
零一万物创始人兼CEO李开复认为,大模型降价对整个行业来说是好消息,行业每年降低10倍推理成本是可以期待的,而且也应该是必然发生的,但同时他也表示价格战是一个“双输”的打法,大模型公司不会这样不理智。
“当其团队认定自己的技术值得的时候,就会坚持一个合适的价格,而绝不会靠贴钱、赔钱去做生意。”
AI大模型的商业化,一直以来都是行业的头号难题。首先是大模型训练成本居高不下,比如李飞飞团队分析报告显示,Google此前发布的Gemini Ultra训练成本高达近2亿美元,OpenAI 的 GPT-4训练成本也预计高达7800万美元,并且随着时间的推移,新推出的大模型训练成本还在不断提高。
而在C端应用中,用户留存和活跃度也正在面临很大挑战,即使是ChatGPT, 自从去年六月开始流量就开始出现下降,大多数用户使用ChatGPT还是基于尝鲜的性质,而无法成为一个日常应用。
根据QuestMobile的数据,AICG的运营数据活跃率均在20%以下,3日留存均在50%以下,卸载率更是在50%以上。
所以,这也反映出目前类ChatGPT的大模型应用,并不是目前大模型的最终表现形式。
而面向B端的API降价,则能够推动AI应用的开发。近一年里,大模型的技术能力提升速度极快,尤其是国内的众多玩家入局后,大模型的能力突飞猛进。
5月21日李开复公布了零一万物团队在国际测评榜单中的新成绩, Yi-Large在 LMSYS 盲测竞技场总榜排名世界第七,中国大模型中第一;其中在中文分榜中与GPT-4o并列世界第一。
他也表示在近一年时间里,中美大模型的差距从7到10年,已经缩短到6个月左右。
因此,在当前大模型技术发展迅速的时间节点,在投入大量资本去创造大模型的同时,如何让大模型商业落地是整个行业共同希望解决的难题。毕竟只有将大模型商业化变现,才能回收训练支出的高昂成本。
所以大模型降价,一定程度上能够吸引更多的企业尝试使用大模型开发AI应用,通过AI应用去创造更广泛的使用场景,以实现“AI普及”。
当然,大模型降价也不是盲目的。火山引擎在发布会上表示,其在技术上有很多优化手段可以降低大模型训练成本,而在工程上可通过分布式推理的形式提高算力利用率等。
另一方面,大模型价格战,对于背靠互联网业务的大厂来说,由于资金压力较小,在市场推广上更有优势。但对于一些大模型初创公司,市场的价格战毫无疑问是加速了优胜劣汰的节奏。
小结:
对于当前商业模式还未走通的大模型行业来说,尝试总是好事。但重走互联网时代的“零和博弈”路线,到底能否复现过去的成功,还要看后续的发展。
-
IT爱学堂-咕泡-第六期-AI大模型零基础到商业实战全栈课2026-06-25 149
-
知学堂知乎AI大模型应用开发实战训练营第22期2026-07-02 116
-
高玮-AI产品经理课11期- 网盘资源2026-07-04 36
-
百家制造商涌入电子书市场:价格战提前到来2009-12-25 1032
-
京苏价格战涉嫌虚假宣传?2012-08-17 1367
-
国内AI商业化元年:三大应用场景亟需落地2017-07-03 815
-
LED芯片价格战愈演愈烈,华灿光电如何摆脱困局?2019-05-10 5818
-
LED屏行业价格战频发 组合促销与拓宽渠道助力企业打好价格战2019-07-05 1926
-
空调库存压力巨大 价格战已开启2019-08-30 1496
-
AI商业化落地如何去促进实现2019-12-20 1747
-
持续数年的激光器价格战或将在今年分化,产业进入“平价时代”2021-01-15 4574
-
人工智能医疗面临的商业化困局2021-02-01 1379
-
微软携手法国AI初创企业Mistral推动AI模型商业化2024-02-28 1447
-
不要被价格战迷乱双眼,大模型竞争的关键在于生态2024-06-07 297
-
芯片代工价格战会来吗?2026-01-30 534
全部0条评论

快来发表一下你的评论吧 !
