

 集成32GB HBM2e内存,AMD Alveo V80加速卡助力传感器处理、存储压缩等
集成32GB HBM2e内存,AMD Alveo V80加速卡助力传感器处理、存储压缩等
描述
电子发烧友网报道(文/黄晶晶)日前,AMD推出Alveo V80加速卡,Versal FPGA自适应SoC搭配HBM,可处理计算以及内存密集型的工作负载,用于高性能计算、数据分析、金融科技、存储压缩等等。

突破网络访问和内存的瓶颈
此次Alveo V80为何采用HBM高速内存,AMD 自适应和嵌入式计算事业部( AECG )高级产品线经理Shyam Chander分析,在传统的处理器架构中,无论是存储器还是网络访问都容易形成瓶颈。网络接口只支持25G、100G,内存采用DDR而FPGA的带宽远高于内存提供的带宽。
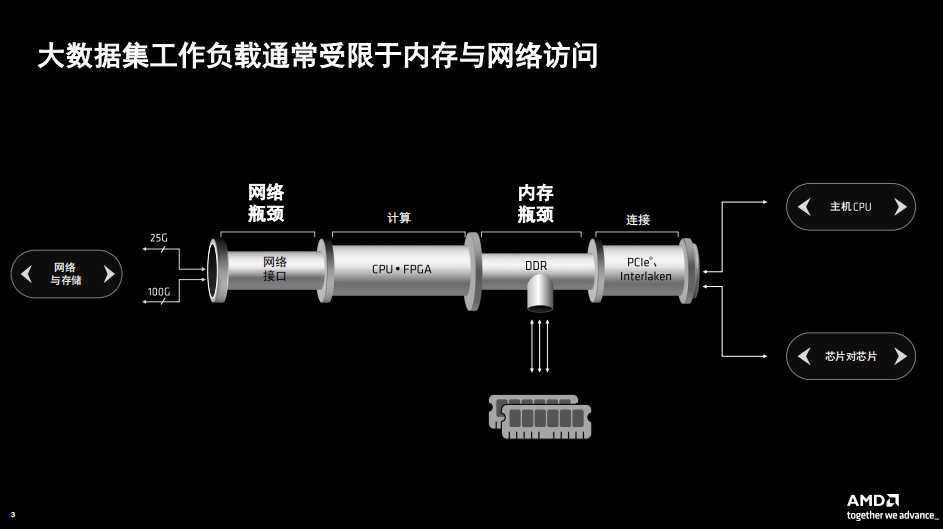
那么Alveo V80针对于这两个问题进行了优化,带来显著的性能提升。内存采用高带宽存储器HBM2e,提供820 GB/s 的存储器带宽,容量达32GB。网络访问上采用QSFP56光纤模块可以支持从10G到800G的带宽,支持4X200G,以及4X10G/25G/40G/50G等不同工作模式。

这款加速卡采用全高、3/4 长( FH¾L )尺寸规格,由 AMD Versal HBM 自适应 SoC 提供支持,具备 2,600,000 个 LUT 逻辑单元的 FPGA 架构、10,848 个 DSP 计算逻辑片以及 820 GB/s 的存储器带宽。

与前代产品 AMD Alveo U55C 计算加速卡相比,Alveo V80 的逻辑密度至高翻倍、存储器带宽至高翻倍且网络带宽可高至 4 倍,可以实现强大的计算集群,同时还能优化卡、服务器数量以及机架空间。
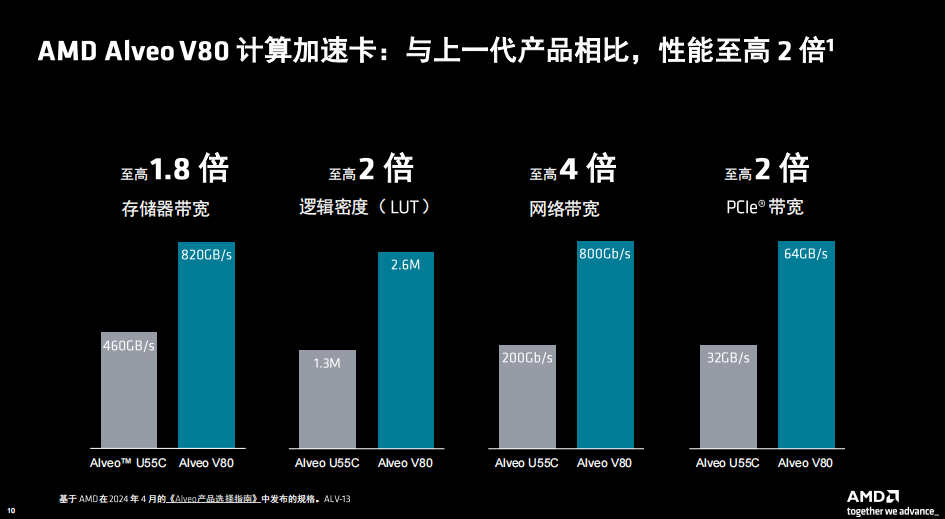
Alveo V80还配有32GB DDR DIMM扩展插槽,MCIO扩展端口可直连NVMe驱动器,实现存储卡的连接。系统连接总线支持PCIe 5.0接口,可达64GB/秒传输速率。整卡功率300W,采用被动散热,总热设计功耗TDP则取决于器件和服务器。
V80集成高带宽网络核心600G以太网和400G加密引擎,硬化基础设施连接包括DDR控制器、支持DMA的PCIe 5.0、可编程片上网络。Shyam Chander表示,基于这些硬化的功能,用户没有必要使用软性的IP进行部署。

通常来说,传统的加速卡(如GPU)要与CPU进行连接,这会限制能够使用的加速卡的数量。但是V80能够避开CPU到加速卡的PCle瓶颈、低时延处理传入的网络数据,消除分立式网络接口卡、实现每服务器的卡数和计算密度最大化。同时,按照需求以网络限速的方式管理传入的数据,包括在线加密、数据包监控、传感器处理等等。
传统架构是固定的缓存层次用于数据的读取和写入,不规则的访问模式会降低效率。而V80的自适应计算,拥有灵活的架构,在计算附近分配内存,从而降低延迟和低功耗,并可以灵活适应自定义的数据类型和数据迁移。
AMD同时提供设计示例AVED,可在GitHub上获取,以及用户可继续使用 Vivado设计套件,从而硬件开发者能够更快地上手,助其缩短开发上市时间。
大规模加速内存密集型工作负载
Alveo V80加速卡可以应对很多大数据工作负载,包括高性能计算,包括基因组学和传感器处理、数据分析(像欺诈检测);金融科技,包括风险分析和算法交易;还有网络安全,像数据包监控;存储压缩,这是一个非常关键的工作负载。另外在AI计算领域,包括推荐引擎和大语言模型等等。因此可以帮助客户大规模加速以上工作负载,可以加快数据处理的速度,同时还能够进行实时的洞见和分析。

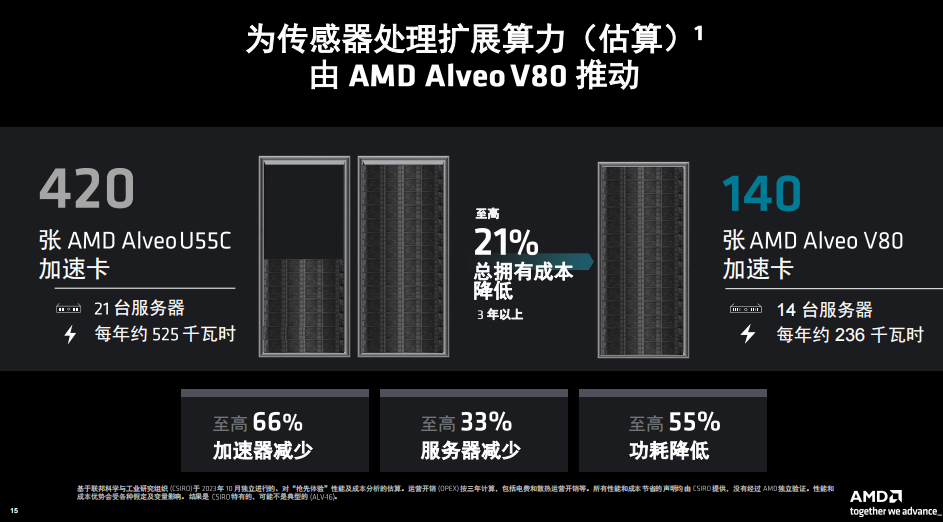
以传感器处理为例,联邦科学与工业研究组织( CSIRO )是澳大利亚的国立研究组织,其参与建造了世界上最大的射电天文学天线阵列,该天线阵列目前包含 420 张 Alveo U55C 加速器卡用于处理无线电波,以研究早期宇宙并探索星系演化。
CSIRO计划借助 Alveo V80 加速卡缩减占板面积与成本,并将所需加速卡的数量精简多达 66%,同时应对来自望远镜 131,000 个天线的新信号处理任务。考虑到卡、服务器、机架空间和功耗的潜在减少,每卡算力的跃升预计可带来至高 20% 总拥有成本( TCO )下降。
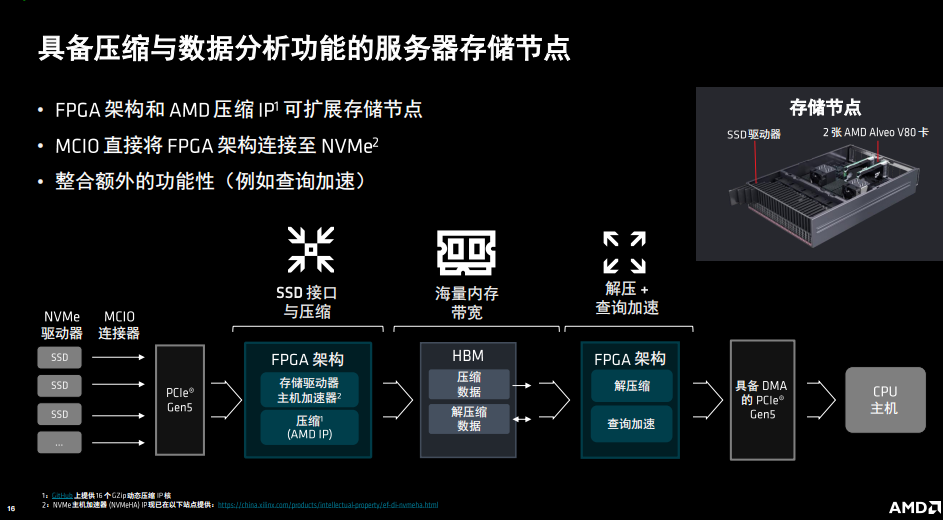
还有具备压缩与数据分析功能的服务器存储节点的例子,通过Alveo V80进行压缩,利用FPGA架构和AMD压缩IP可扩展存储节点,并可解压缩,查询加速等。
从总拥有成本的角度来分析,比如10Pb数据存储,没有压缩时需要55台服务器,1303个SSD驱动器,每年约427千瓦时的功耗。如果进行压缩,同样10Pb数据,只需要21台服务器,504个SSD驱动器,每年约233千瓦时,使用42张AMD Alveo V80卡进行压缩,总拥有成本三年以上至高可以达到56%的降低,而且服务器的数量、服务器成本以及功耗也都有非常显著的降低。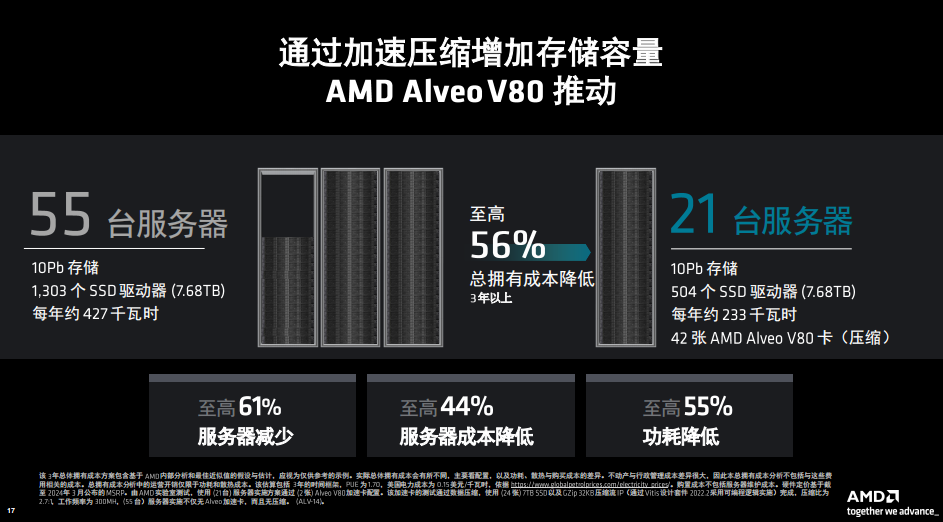
小结:
市面上加速卡也有GPU、ASIC等,但这些加速卡各有所长。Shyam Chander表示,相较而言GPU擅长浮点、并联、定点,FPGA擅长线上访问的实时处理,而且低时延、灵活应变,有非常丰富的存储器架构资源。AMD Alveo系列产品主要针对内联网络、实时处理比如传感器的实时处理、金融科技的需求,他们的诉求点在于低时延和灵活应变,FPGA的自适应SoC就是极好的解决方案。
另外,HBM的价格虽然高于DDR,但是如果能够正确地配置FPGA资源,最终就能实现高性价比的竞争优势。在产品路线上,全面看待工作负载方面的要求,也在考虑引入HBM3等存储。
-
选择AMD Alveo V80加速卡的五大理由2026-04-10 458
-
AMD Alveo V80计算加速器网络研讨会2024-11-08 1172
-
AMD 以全球极快的纤薄尺寸电子交易加速卡扩展 Alveo 产品组合,助力广泛且具性价比的服务器部署2024-10-16 619
-
贸泽开售适用于高性能计算应用的AMD Alveo V80加速器卡2024-09-27 682
-
AMD Alveo V80计算加速卡实现量产2024-05-16 1327
-
AMD正式量产Alveo V80计算加速卡,优化大数据集中的内存瓶颈问题2024-05-15 1553
-
AMD 为超低时延电子交易推出 Alveo UL3524 加速卡2023-10-11 1835
-
还没用上HBM2E?HBM3要来了2021-08-23 2597
-
最强A卡刚发布 NV就出大招:80GB HBM2e、性能提升200%2020-11-17 3404
-
SK Hynix宣布HBM2E标准存储器已投入量产2020-09-10 3128
-
SK海力士宣布将要推出新型HBM2E存储器2019-09-09 1487
全部0条评论

快来发表一下你的评论吧 !
