
资料下载


Uber为什么从Postgres迁移到MySQL
分享资料个
导论
Uber的早期架构由一个单体后端应用程序构成,该应用由Python编写,Python使用Postgres以实现数据持久化。自那时起,Uber架构已发生巨变,逐步转化为微服务模式和新的数据平台。特别是在之前一些使用Postgres的案例中,现在则改用Schemaless(一个基于MySQL的全新数据库分片)。本文将探索Postgres的缺陷,解释迁移到MySQL的基础上构建Schemaless和其它后端服务的原因。
Postgres的架构
Postgres有很多局限性:
写入架构低效数据复制低效表损坏的问题糟糕的从库MVCC支持新版本更新难度升级
下文将分析Postgres的表表示法和磁盘上的索引数据,重点对比MySQL通过其InnoDB存储引擎呈现相同数据的方法,以探索上述缺陷。注意:本文涉及的分析主要基于旧版Postgres 9.2系列。 众所周知,本文论述的内部架构在新发布的Postgres中没有太大变更。事实上,至少自Postgres 8.3的发布开始(距今近十年),Postgres 9.2中磁盘上表示法的基础设计就一直没有做出显著调整。
磁盘上的数据格式
关系数据库必须执行下列关键任务:
支持插入/更新/删除功能支持schema变更功能实现一个多版本并发控制(MVCC)机制,促使不同的连接对其所处理的数据生成一致性的事务视图
思考其所有特性如何协同运作是设计数据库在磁盘上呈现数据的基础。
Postgres的一项核心设计是行数据固定。该固定行在Postgres用语中又名“元组(tuple)”。在Postgres中,元组又通过ctid获得唯一标识。从概念上讲,ctid代表元组在磁盘上的位置(例如物理磁盘偏移)。多个ctid可能能够描述一个单行(例如多个行版本为了MVCC的目的而存在时,或是旧版本行未经autovacuum进程回收时)。一组元组的组织集合构成表,表本身包含索引,索引经组合构成数据结构(通常是B-tree结构),从而将索引字段映射到ctid的有效载荷。
通常情况下,这些ctid是面向用户透明的,但了解其运行方式有助于理解Postgres表在磁盘上的表架构。若要查看行的当前ctid,则可向WHERE子句中的栏目列表中添加“ctid”:
uber@[local] uber=》 SELECTctid, * FROM my_table LIMIT 1; -[ RECORD1]--------+------------------------------ctid | (0,1) 。。.other fields here.。。
为求布局细节,先以一个简单的用户表为例。Uber针对每个用户设置了自动递增的用户ID主键、用户姓名和出生年份。同时Uber还设置了一个基于用户全名(包括名和姓)的复合二级索引,和另一个基于用户出生年份的二级索引。用以创建该表的DDL如下:
CREATETABLEusers ( id SERIAL, firstTEXT, lastTEXT, birth_year INTEGER, PRIMARYKEY(id) );CREATEINDEX ix_users_first_last ONusers (first, last);CREATEINDEX ix_users_birth_year ONusers (birth_year);
注意该定义中的三个索引:主键索引和两个二级索引。
为求例证,将以下面的表格数据展开论述,表中数据均由历史上颇具影响力的数学家构成:
id
first
last
birth_year
1 Blaise Pascal 1623
2 Gottfried Leibniz 1646
3 Emmy Noether 1882
4 Muhammad al-Khwārizmī 780
5 Alan Turing 1912
6 Srinivasa Ramanujan 1887
7 Ada Lovelace 1815
8 Henri Poincaré 1854
如前所述,表中每一行隐含一个唯一且不公开的ctid。因此,表的内部表示如下:
ctid
id
first
last
birth_year
A 1 Blaise Pascal 1623
B 2 Gottfried Leibniz 1646
C 3 Emmy Noether 1882
D 4 Muhammad al-Khwārizmī 780
E 5 Alan Turing 1912
F 6 Srinivasa Ramanujan 1887
G 7 Ada Lovelace 1815
H 8 Henri Poincaré 1854
设置主键索引(映射ID到ctid):
id
cti
1 A
2 B
3 C
4 D
5 E
6 F
7 G
8 H
B-tree结构的设置基于id字段,且其每个节点都保存ctid值。在这个案例中需要注意的是,由于使用自动递增id,B-tree中的字段顺序有时会和表中顺序相同,但是也不一定如此。
二级索引彼此都很相似;主要差异在于字段存储顺序,而字段在B-tree中必须以字典顺序排布。(first,last)索引从名开始按字母表顺序自上而下排列。
first
last
ctid
Ada Lovelace G
Alan Turing E
Blaise Pascal A
Emmy Noether C
Gottfried Leibniz B
Henri Poincaré H
Muhammad al-Khwārizmī D
Srinivasa Ramanujan F
同样,birth_year(出生年份)聚集索引以升序排列:
birth_year
ctid
780 D
1623 A
1646 B
1815 G
1854 H
1887 F
1882 C
1912 E
综上所述,不同于自动递增主键的案例,在上面的情境下,各个二级索引中的ctid字段都不是按字母表顺序升序排布的。
假设需要更新一条表记录,比如将al-Khwārizmī的出生年份字段更新为另一个预估值770CE。如前所述,行元组是固定的,因此,为了更新记录,需要向表中添加一个新元组。该新元组有一个新的非公开ctid,称之为I。Postgres需要能够区分I上的新元组和D上的旧元组。在内部,Postgres将一个版本字段和指向前一个元组(如果有的话)的指针存于各个元组。据此,表的新结构如下:
ctid
prev
id
first
last
birth_year
A null 1 Blaise Pascal 1623
B null 2 Gottfried Leibniz 1646
C null 3 Emmy Noether 1882
D null 4 Muhammad al-Khwārizmī 780
E null 5 Alan Turing 1912
F null 6 Srinivasa Ramanujan 1887
G null 7 Ada Lovelace 1815
H null 8 Henri Poincaré 1854
I D 4 Muhammad al-Khwārizmī 770
只要al-Khwārizmī存在两个行版本,则索引必须包含这两个行的条目。为求简洁,Uber此处删除了主键索引,只显示二级索引:
first
last
ctid
Ada Lovelace G
Alan Turing E
Blaise Pascal A
Emmy Noether C
Gottfried Leibniz B
Henri Poincaré H
Muhammad al-Khwārizmī D
Muhammad al-Khwārizmī I
Srinivasa Ramanujan F
birth_year
ctid
770 I
780 D
1623 A
1646 B
1815 G
1854 H
1887 F
1882 C
1912 E
此处将旧版显示为红色,新版为绿色。在内部,Postgre通过另一个字段保存行版本,以判定哪一个是最新元组。该新增字段帮助数据库决定让哪一个行元组服务于一个事务,该事务可能不被允许查看最新行版本。
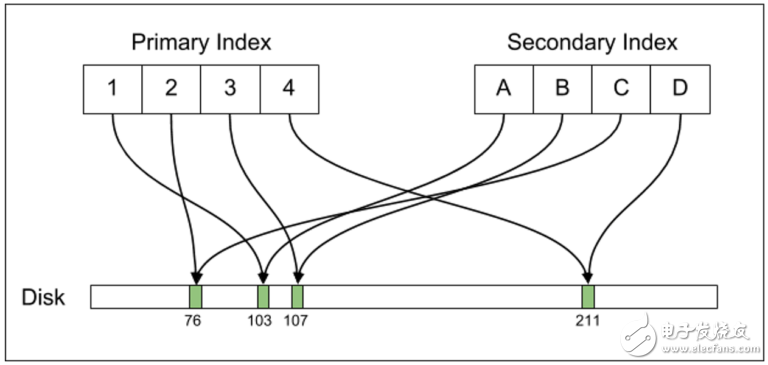
Postgres下,主索引和二级索引都直指磁盘上的元组偏移。若一个元组的位置发生改变,则必须更新全部索引。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章



下载排行榜
- 暂无相关数据

