
资料下载


×
Spring数据框架在数据处理以及微服务方面的进步
消耗积分:1 |
格式:rar |
大小:0.4 MB |
2017-10-11
分享资料个
导言:本文讲述了Spring数据框架在数据处理以及微服务方面的进化史。
定量分析能否成功,在很大程度上要依赖于其收集、存储与处理数据的能力。如果企业决策者能获得及时、可靠的见解分析,那么大数据项目的成功几率就会有所提高。
如今,想要为数据处理搭建合适的架构,需要付出颇为可观的努力。数据处理的类型主要集中在三个方面:
批处理:多用于处理大量具有可扩展性与分布性的静态数据。 实时处理:主要用于处理流式数据(连续不断的无限数据流),这类数据具有分布性与高速率特质。 混合计算模式:这种模式是批处理与实时处理的结合,可处理大容量的高速率数据。
大数据工程很花时间,同时要求工程师具备数据采集与数据处理的相关技巧,在大多解决方案中,时间与技能这两点都必不可少。Pivotal公司发布的Spring XD和Spring Cloud Dataflow这两款产品,都是用于减少大数据工程中开销的。本文会对Spring XD做以简单的介绍,并对其最新版,也就是Spring Cloud Data Flow进行更为详尽的介绍。
Spring XD
第一轮创新的结果造就了Spring XD(eXtreme Data,极限数据),这项技术为解决大数据处理的相关任务提供了易于使用的解决方案。Spring XD建立在成熟的Spring技术之上,为数据获取、迁移、处理、深度分析、流处理以及批处理任务提供支持。
Spring XD提供的框架可用于实时处理及批处理任务,该框架具有复杂性、稳定性及可扩展性。有了Spring XD,无论是收集数据,还是将数据从不同的数据源迁移到目标上,都变得更为简单。
Spring XD架构已广泛用于传统的企业ETL中、实时分析中与数据科学项目的工作台的创建中。
基于Spring XD的架构:
这种架构在下图中有所表现,在下列模块协助下,我们能够创建、运行、部署、撤销数据流通道(data pipeline),在框架中执行任意类型的数据处理任务。
SpringXD的主要组件是Admin和Container。
Admin UI向服务器发送需要处理的请求,而服务器通过执行任务的相关模块来处理请求。在这里,一个模块就是创建Spring应用前后关系(application context)的一个组件。
所有模块都需要XD容器才能运行和执行任务。
下面是Spring XD架构的关键模块。
Source:数据流的创建总是始于source模块。Source可以使用轮询机制或事件驱动机制,并且只会输出一个结果。 Processor:接受信息输入,并对输入的信息执行某种类型的处理,然后再输出信息。 Sink:顾名思义这个模块是负责终止数据流的,然后将输出结果发送到HDFS之类的外部资源中。 Job:这个模块负责执行批处理任务。
Spring Cloud Data Flow的需求
在Spring XD中,本质上不断变更的应用与需求之间还存在着缺口,需要我们在新一轮创新中解决。下面是推动新框架需求最为关键的要求:
在云技术的推动下,平台级别的操作与非功能需求都能很容易的实现。至于应用级别的非功能需求,仍是很有挑战性的。
我们对系统分阶段交付、执行动态资源分配、具有扩展能力以及在分布式环境中追踪的能力,都有着越来越大的需求。
如今,人们对于平台的需求从功能性转向选择云供应商。基于微服务的云架构更适合这一目标,但Spring XD并不能直接支持微服务架构。
Spring XD支持大数据场景,但仍有很大一部分项目无需Hadoop提供数据存储与处理服务。
Spring Cloud Data Flow
在第二轮的创新中,Pivotal公司推出了Spring Cloud Data Flow,作为Spring XD的替代产品。Spring Cloud Data Flow继承了Spring XD的优点,并提供了更有扩展性的解决方案——利用云技术的原生方式。Spring Cloud Data Flow是一个混合计算模型,结合了流数据与批量数据的处理方式。开发者可以通过Spring Cloud Data Flow,在诸如数据获取、实时分析、批处理等常见用例中执行数据流的创建与编排。Spring Cloud Data Flow的目标就是为了方便数据工程师,让他们能专注于分析工作和具体的问题。Spring Cloud Data Flow仅提供了管理服务的模型。
Spring Cloud Data Flow的架构
Spring Cloud Data Flow是Spring XD的修订版,在功能的构成方式上,还有如何协助原生云架构扩展应用方面,都做出了根本性的改变。
Spring Cloud Data Flow不再使用传统基于组件的架构了,而是采用了信息驱动的微服务架构,这种架构更适合原生云应用平台的原生应用。Spring XD的模块现在被部署到云上的微服务取代。
主要变化出现在下面这些领域中:
Spring Cloud Data Flow利用原生云平台引进了新的服务提供商接口(SPI),取代Spring XD原有的运行层。
虽然类似Admin REST API、shell层和UI层之类的用户接口与集成元素都与Spring XD中的一致,但底层架构发生了变化。
服务提供商接口或者SPI取代了基于Zookeeper的运行方式。现在,SPI能够协同Pivotal的Cloud Foundry或者Yarn之类监控/发布微服务应用的系统一同运作。
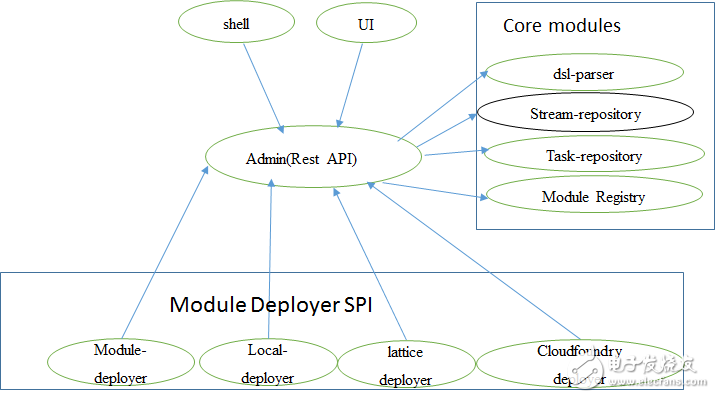
下表对Spring Cloud Data Flow的各个组件做了解释:
组件
目的
核心域模块 数据流的主要基础组成,包含了类似source、sink、stream之类的模块,以及批处理任务,所有这些模块都是Spring Boot Data的微服务应用。
模块注册 使用Maven维护着可用的模块。
Module Deployer SPI 在不同的运行环境(比如Lattice、Cloud Foundry、Yarn和Local)中部署模块的抽象层。
Admin 属于Spring Boot应用,提供REST API和UI。
Shell 使用Shell可以运行DSL命令以创建、处理、撤销数据流或执行其他的简单任务,并连接Admin的Rest API。
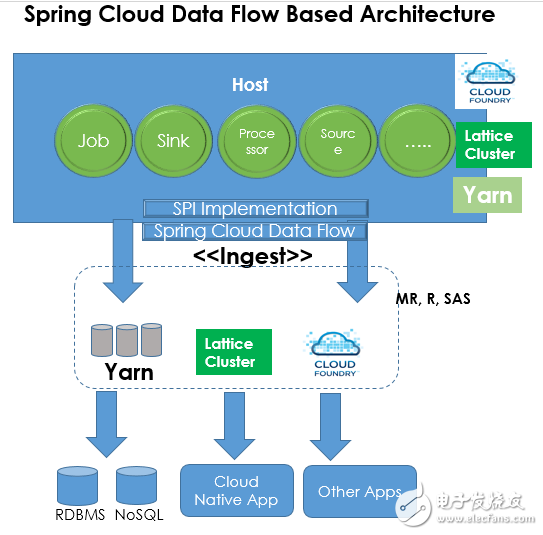
上图表现了使用Spring Cloud Data Flow所创建的典型数据流。
Source、job、sink和processor模块都是Spring Boot的微服务,可以部署在Cloud Foundry、Lattice或Yarn集群上。使用这些微服务来部署原生云平台,我们就能创建数据流,并将其输入基于Yarn、Lattice或Cloud Foundry的目标。特定平台的SPI(服务提供商接口)可用于基于平台部署的微服务绑定、探索以及绑定通道。
用例
Spring Cloud Data Flow的真正好处在于它能够快速安装与配置,通过统一的框架构建数据的收集及处理步骤,因此开发者就能专注于具体问题的解决。
我们打算对构建非现有源(如Facebook数据)用例的所需更改作出高度概括,这种做法是为了分析Facebook的帖子,在Spring Cloud Data stream的模块中,没有现成的Facebook数据源,因此我们需要为Facebook源创建定制的模块。创建数据流需要三个主要的微服务:source、processor和sink,三者的接口均已提供。
Facebook数据流的Source and Sink微服务示例代码如下:
Facebook Source:
@SpringBootApplication@ComponentScan(.class) publicclassSourceApplication{publicstaticvoidmain(String[] args) { SpringApplication.run(SourceApplication.class, args); } } @Configuration@EnableBinding(Source.class) publicclassFBSource{@Value(“${format}”) privateString format; @Bean@InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = “${fixedDelay}”, maxMessagesPerPoll = “1”)) publicPostSource《String》 FBPostSource() { // Logic to get FB Posts from Facebook API’sreturn// FB Post }}
注解@EnableBindings(Source.class) 探测到了binder的实现(需要在应用路径中按照Redis的方式进行设置),之后binder创建了通道适配器。所有微服务都以Spring Boot应用的形式进行开发,以便我们更好地管理依赖关系。
Facebook Sink:
@SpringBootApplication@EnableBinding(Sink.class) @ComponentScan(.class) publicclassSinkApplication{publicstaticvoidmain(String[] args) { SpringApplication.run(SinkApplication.class, args); } } @ConfigurationpublicclassFBSink{privatestaticLogger logger = LoggerFactory.getLogger(LogSink.class); @ServiceActivator(.INPUT) publicvoidloggerSink(Object payload) { logger.info(“Received: ”+ payload); } }
在上面的代码中,我们使用source接收Facebook的数据流,将其写入控制台,并将Sink.class作为@EnableBinding的参数。在本例中,@ServiceActivator与端点控制台的输入是相关联的。
Processor微服务会根据SPEL expressions,筛选来自FBSource微服务的Facebook帖。processor微服务的输出结果就是FBSink的输入内容。
结论
Spring Cloud Data Flow使用了Spring Cloud stream模块,我们可以利用这些模块以Spring Boot应用的形式创建运行信息传递微服务,这样它们就能部署在不同的平台上,独立运行并相互交互。在使用Spring Cloud stream模块创建数据流通道的时候,Spring Cloud Data Flow扮演了粘合剂的作用。
目前,在数据收集、实时分析与数据载入方面有很多独立的开源项目。Spring Cloud Data Flow为数据收集、实时分析、批处理与数据输出提供了统一、分布式的可扩展服务。
定量分析能否成功,在很大程度上要依赖于其收集、存储与处理数据的能力。如果企业决策者能获得及时、可靠的见解分析,那么大数据项目的成功几率就会有所提高。
如今,想要为数据处理搭建合适的架构,需要付出颇为可观的努力。数据处理的类型主要集中在三个方面:
批处理:多用于处理大量具有可扩展性与分布性的静态数据。 实时处理:主要用于处理流式数据(连续不断的无限数据流),这类数据具有分布性与高速率特质。 混合计算模式:这种模式是批处理与实时处理的结合,可处理大容量的高速率数据。
大数据工程很花时间,同时要求工程师具备数据采集与数据处理的相关技巧,在大多解决方案中,时间与技能这两点都必不可少。Pivotal公司发布的Spring XD和Spring Cloud Dataflow这两款产品,都是用于减少大数据工程中开销的。本文会对Spring XD做以简单的介绍,并对其最新版,也就是Spring Cloud Data Flow进行更为详尽的介绍。
Spring XD
第一轮创新的结果造就了Spring XD(eXtreme Data,极限数据),这项技术为解决大数据处理的相关任务提供了易于使用的解决方案。Spring XD建立在成熟的Spring技术之上,为数据获取、迁移、处理、深度分析、流处理以及批处理任务提供支持。
Spring XD提供的框架可用于实时处理及批处理任务,该框架具有复杂性、稳定性及可扩展性。有了Spring XD,无论是收集数据,还是将数据从不同的数据源迁移到目标上,都变得更为简单。
Spring XD架构已广泛用于传统的企业ETL中、实时分析中与数据科学项目的工作台的创建中。
基于Spring XD的架构:
这种架构在下图中有所表现,在下列模块协助下,我们能够创建、运行、部署、撤销数据流通道(data pipeline),在框架中执行任意类型的数据处理任务。
SpringXD的主要组件是Admin和Container。
Admin UI向服务器发送需要处理的请求,而服务器通过执行任务的相关模块来处理请求。在这里,一个模块就是创建Spring应用前后关系(application context)的一个组件。
所有模块都需要XD容器才能运行和执行任务。
下面是Spring XD架构的关键模块。
Source:数据流的创建总是始于source模块。Source可以使用轮询机制或事件驱动机制,并且只会输出一个结果。 Processor:接受信息输入,并对输入的信息执行某种类型的处理,然后再输出信息。 Sink:顾名思义这个模块是负责终止数据流的,然后将输出结果发送到HDFS之类的外部资源中。 Job:这个模块负责执行批处理任务。
Spring Cloud Data Flow的需求
在Spring XD中,本质上不断变更的应用与需求之间还存在着缺口,需要我们在新一轮创新中解决。下面是推动新框架需求最为关键的要求:
在云技术的推动下,平台级别的操作与非功能需求都能很容易的实现。至于应用级别的非功能需求,仍是很有挑战性的。
我们对系统分阶段交付、执行动态资源分配、具有扩展能力以及在分布式环境中追踪的能力,都有着越来越大的需求。
如今,人们对于平台的需求从功能性转向选择云供应商。基于微服务的云架构更适合这一目标,但Spring XD并不能直接支持微服务架构。
Spring XD支持大数据场景,但仍有很大一部分项目无需Hadoop提供数据存储与处理服务。
Spring Cloud Data Flow
在第二轮的创新中,Pivotal公司推出了Spring Cloud Data Flow,作为Spring XD的替代产品。Spring Cloud Data Flow继承了Spring XD的优点,并提供了更有扩展性的解决方案——利用云技术的原生方式。Spring Cloud Data Flow是一个混合计算模型,结合了流数据与批量数据的处理方式。开发者可以通过Spring Cloud Data Flow,在诸如数据获取、实时分析、批处理等常见用例中执行数据流的创建与编排。Spring Cloud Data Flow的目标就是为了方便数据工程师,让他们能专注于分析工作和具体的问题。Spring Cloud Data Flow仅提供了管理服务的模型。
Spring Cloud Data Flow的架构
Spring Cloud Data Flow是Spring XD的修订版,在功能的构成方式上,还有如何协助原生云架构扩展应用方面,都做出了根本性的改变。
Spring Cloud Data Flow不再使用传统基于组件的架构了,而是采用了信息驱动的微服务架构,这种架构更适合原生云应用平台的原生应用。Spring XD的模块现在被部署到云上的微服务取代。
主要变化出现在下面这些领域中:
Spring Cloud Data Flow利用原生云平台引进了新的服务提供商接口(SPI),取代Spring XD原有的运行层。
虽然类似Admin REST API、shell层和UI层之类的用户接口与集成元素都与Spring XD中的一致,但底层架构发生了变化。
服务提供商接口或者SPI取代了基于Zookeeper的运行方式。现在,SPI能够协同Pivotal的Cloud Foundry或者Yarn之类监控/发布微服务应用的系统一同运作。
下表对Spring Cloud Data Flow的各个组件做了解释:
组件
目的
核心域模块 数据流的主要基础组成,包含了类似source、sink、stream之类的模块,以及批处理任务,所有这些模块都是Spring Boot Data的微服务应用。
模块注册 使用Maven维护着可用的模块。
Module Deployer SPI 在不同的运行环境(比如Lattice、Cloud Foundry、Yarn和Local)中部署模块的抽象层。
Admin 属于Spring Boot应用,提供REST API和UI。
Shell 使用Shell可以运行DSL命令以创建、处理、撤销数据流或执行其他的简单任务,并连接Admin的Rest API。
上图表现了使用Spring Cloud Data Flow所创建的典型数据流。
Source、job、sink和processor模块都是Spring Boot的微服务,可以部署在Cloud Foundry、Lattice或Yarn集群上。使用这些微服务来部署原生云平台,我们就能创建数据流,并将其输入基于Yarn、Lattice或Cloud Foundry的目标。特定平台的SPI(服务提供商接口)可用于基于平台部署的微服务绑定、探索以及绑定通道。
用例
Spring Cloud Data Flow的真正好处在于它能够快速安装与配置,通过统一的框架构建数据的收集及处理步骤,因此开发者就能专注于具体问题的解决。
我们打算对构建非现有源(如Facebook数据)用例的所需更改作出高度概括,这种做法是为了分析Facebook的帖子,在Spring Cloud Data stream的模块中,没有现成的Facebook数据源,因此我们需要为Facebook源创建定制的模块。创建数据流需要三个主要的微服务:source、processor和sink,三者的接口均已提供。
Facebook数据流的Source and Sink微服务示例代码如下:
Facebook Source:
@SpringBootApplication@ComponentScan(.class) publicclassSourceApplication{publicstaticvoidmain(String[] args) { SpringApplication.run(SourceApplication.class, args); } } @Configuration@EnableBinding(Source.class) publicclassFBSource{@Value(“${format}”) privateString format; @Bean@InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = “${fixedDelay}”, maxMessagesPerPoll = “1”)) publicPostSource《String》 FBPostSource() { // Logic to get FB Posts from Facebook API’sreturn// FB Post }}
注解@EnableBindings(Source.class) 探测到了binder的实现(需要在应用路径中按照Redis的方式进行设置),之后binder创建了通道适配器。所有微服务都以Spring Boot应用的形式进行开发,以便我们更好地管理依赖关系。
Facebook Sink:
@SpringBootApplication@EnableBinding(Sink.class) @ComponentScan(.class) publicclassSinkApplication{publicstaticvoidmain(String[] args) { SpringApplication.run(SinkApplication.class, args); } } @ConfigurationpublicclassFBSink{privatestaticLogger logger = LoggerFactory.getLogger(LogSink.class); @ServiceActivator(.INPUT) publicvoidloggerSink(Object payload) { logger.info(“Received: ”+ payload); } }
在上面的代码中,我们使用source接收Facebook的数据流,将其写入控制台,并将Sink.class作为@EnableBinding的参数。在本例中,@ServiceActivator与端点控制台的输入是相关联的。
Processor微服务会根据SPEL expressions,筛选来自FBSource微服务的Facebook帖。processor微服务的输出结果就是FBSink的输入内容。
结论
Spring Cloud Data Flow使用了Spring Cloud stream模块,我们可以利用这些模块以Spring Boot应用的形式创建运行信息传递微服务,这样它们就能部署在不同的平台上,独立运行并相互交互。在使用Spring Cloud stream模块创建数据流通道的时候,Spring Cloud Data Flow扮演了粘合剂的作用。
目前,在数据收集、实时分析与数据载入方面有很多独立的开源项目。Spring Cloud Data Flow为数据收集、实时分析、批处理与数据输出提供了统一、分布式的可扩展服务。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





下载排行榜
- 暂无相关数据

