

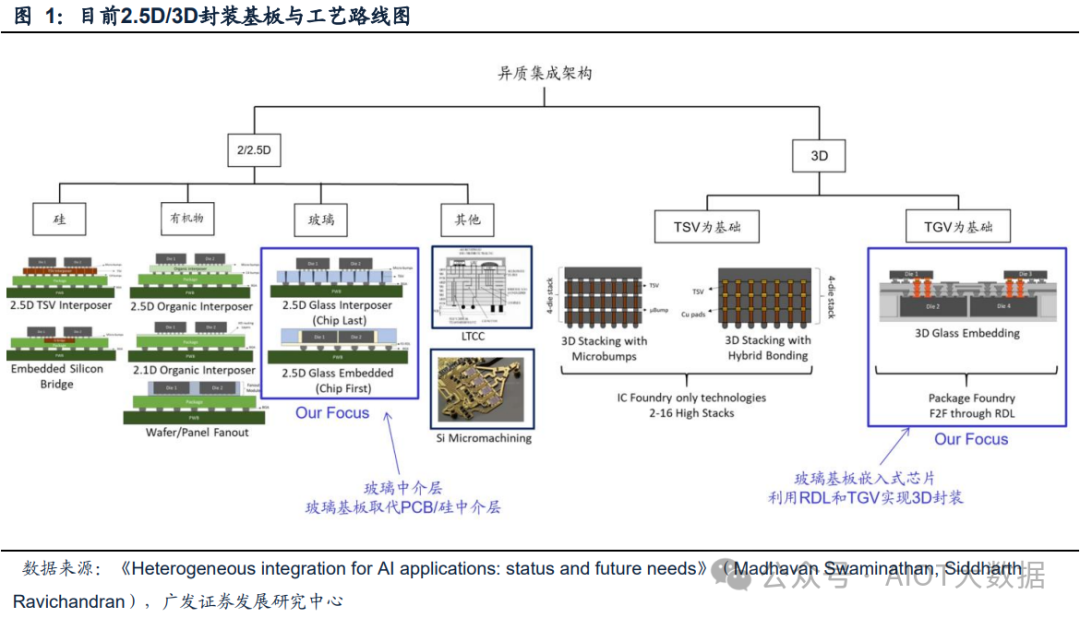
技术前沿探索:玻璃基板嵌入技术(GPE)与玻璃基板扇出封装(eGFO)
描述
Chiplet封装的兴起
由于受光刻机工作窗口,以及掩模板材料对光线解析度的限制,芯片的大小被限制在了一个很小的面积上,也就是平常所见的一片邮票大小(约800平方毫米)。
虽然有类似英特尔这种企业,在研发不计成本的超算CPU芯片时,曾经突破过这个尺寸一点点,制造出了“大芯片”(约1200平方毫米),但是并没有在市场上真正的流行起来。
算力在多线程CPU和超线程GPU的需求下,每个线程的内核数量不断的堆积,最终把芯片的一些周边功能元件给挤出了芯片面积有限的裸Die,这些周边的元器件不得不通过专用的数据交换与传输器件,在裸Die外与主芯片裸Die进行集成,这就是Chiplet封装集成工艺,由选配进入到强需求的原因。
而且随着主芯片裸Die的内核集成规模越来越大,不但周边配套的功能元件如缓存、内存、数据交换与传输等,也要随之功能越来越强大,集成的功能越来越多,成为独立裸Die趁势也越来越明显;而且受芯片有限面积的限制,主芯片裸Die也开始装不下那么多内核,要分拆开来制造,再通过类Chiplet封装集成工艺,把多个主芯片裸Die给缝制成一颗主芯片模组。
行业里,除了英特尔、谷歌缝制过类似的超算力芯片外,目前行业里最火的,就是各大科技公司纷纷争抢市场配额的英伟达GB200超级AI GPU芯片组。Nvidia基于Blackwell架构的GB200 GPU,其核心是Bianca板,它包含两个Blackwell B200 GPU和一个Grace CPU,再通过配备两个28.8Tb/s的NVSwitch5 ASIC 的NVSwitch托盘给连接成不同的单集成柜,目前有GB200 NVL72,GB200 NVL36x2,GB200 NVL36x2(Ariel)和x86 B200 NVL72/NVL36x2四种形态。
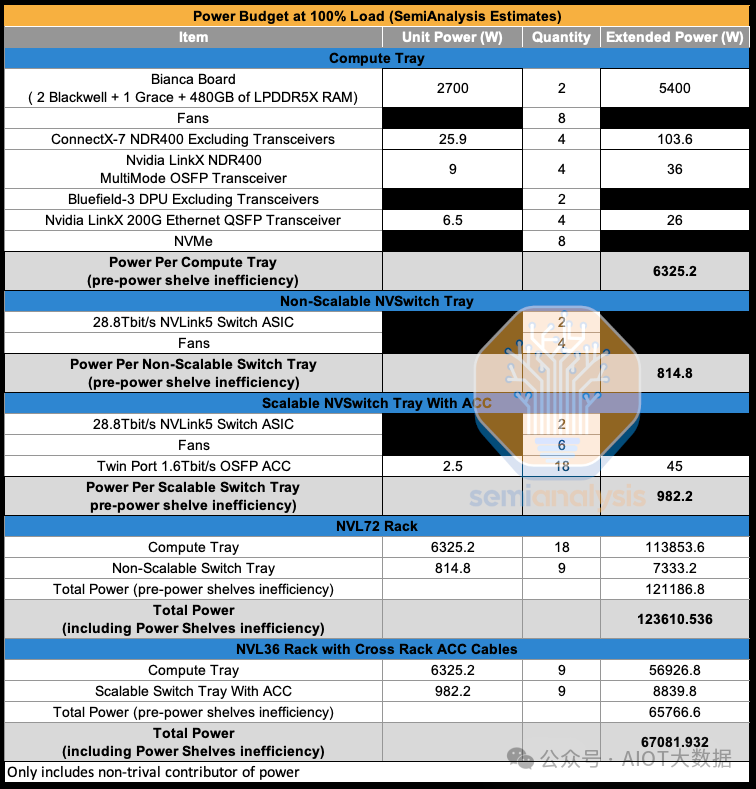
Source: SemiAnalysis GB200 Component & Supply Chain Model
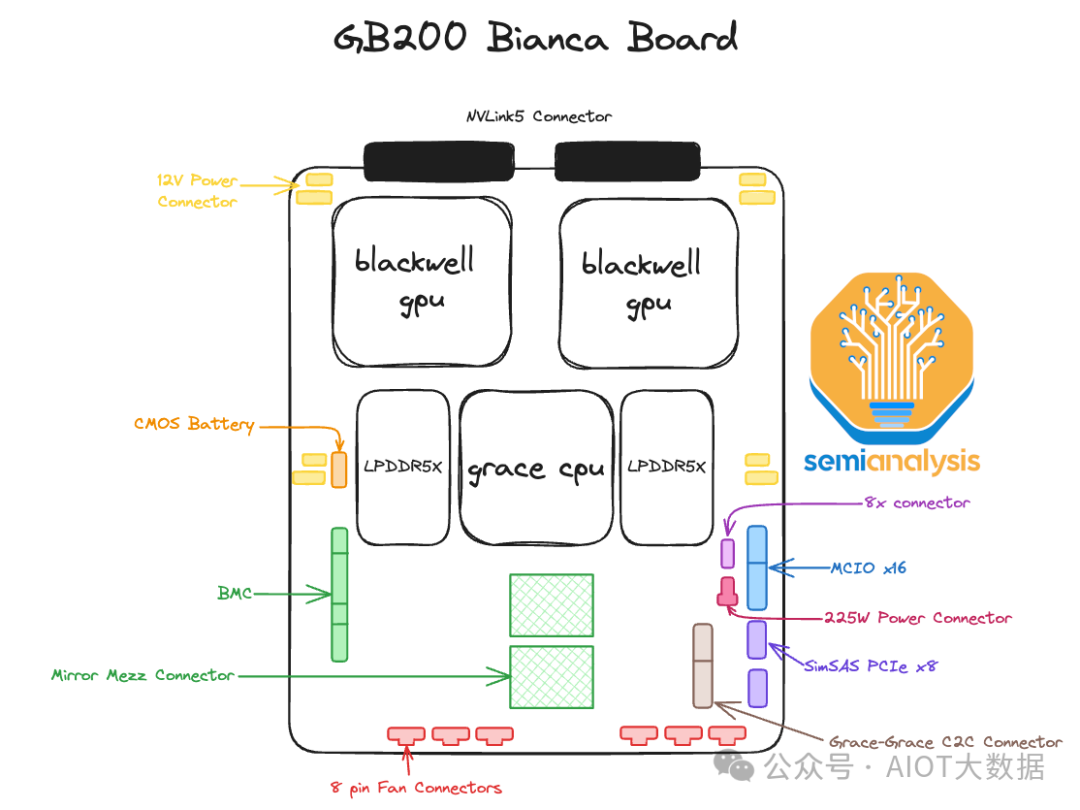
Source: SemiAnalysis
在同一个计算托盘中,有一个高速一致性NVLink连接,可实现高达600Gb/s双向带宽(300Gb/s单向),这个连接速度极快,允许CPU共享资源和内存。
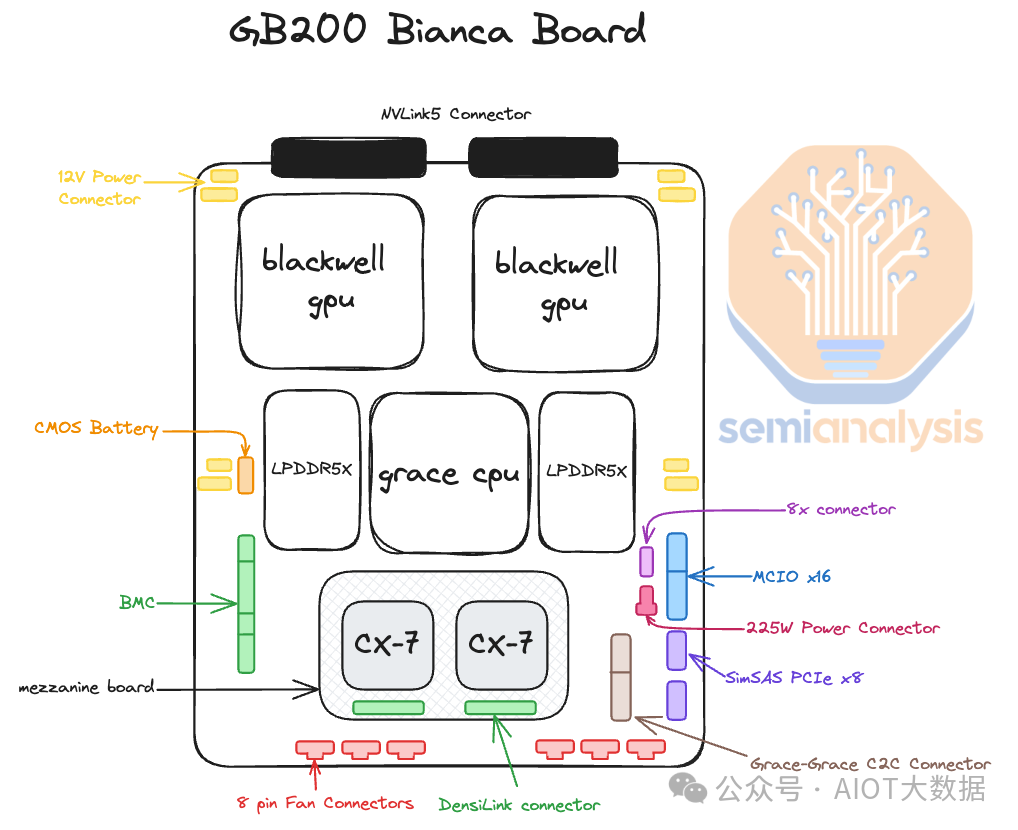
Source: SemiAnalysis
另外英伟达宣称,GB200 NVLink可以将576个Blackwell GPU连接在一起,行业分板英伟达可能会将使用288个L1 NVSwitch5 ASIC (144个1U交换机托盘),并将使用144个L2 NVSwitch ASIC (72个2U交换机托盘)位于专用NV Switch托盘上。与NVL36x2类似,因为距离很近,GPU与L1 NVSwitch将使用相同的铜背板相连。
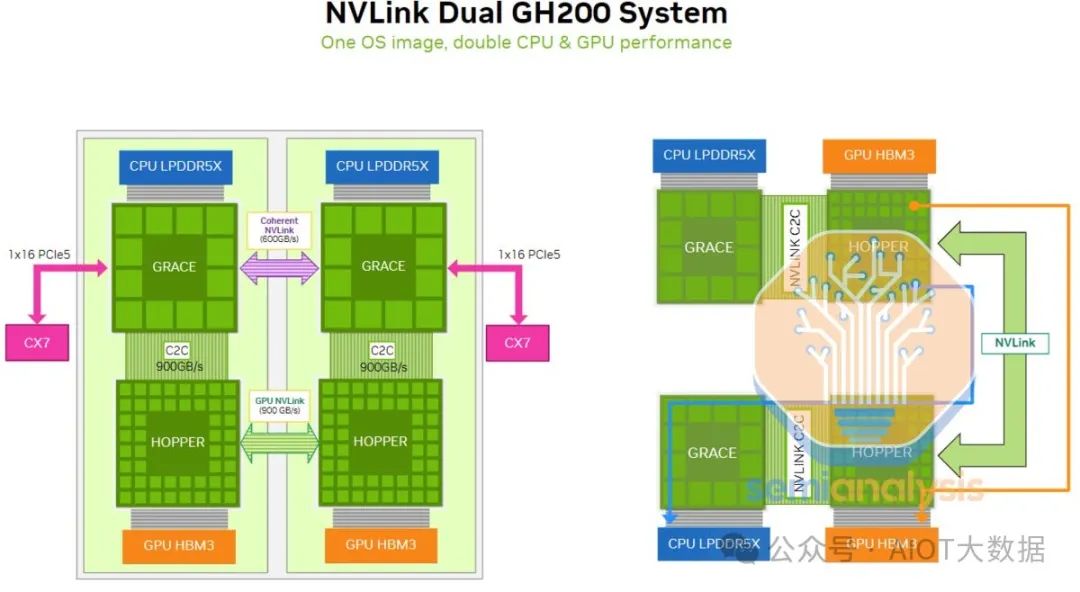
Source: Nvidia
英伟达这样做的原因,主要就是Blackwell的硅面积(约1600平方毫米,拥有2080亿个晶体管)是之前单裸Die芯片Hopper的两倍(约800平方毫米,拥有800亿个晶体管)。由于摩尔定律的放缓和3纳米问题,Nvidia必须在没有真正工艺节点缩小的情况下提供一代又一代的性能。通过使用DTCO(Design-Technology Co-Optimization)和轻微的6%光学工艺缩小,Blackwell仍然能够提供Hopper两倍的性能。
当以每平方毫米硅面积的原始TFLOPS来衡量,即与逻辑制造成本进行对比时,B100实际上提供了更低的性能,FLOPS提高了77%,而硅面积增长了约100%。这是因为为了迅速上市,需要将时钟降低以适应现有的700瓦平台,而且只有在B200和GB200 NVL72上才能看到每平方毫米硅面积的改进。
通过硅面积增益进行归一化,使用空气冷却的B200每平方毫米硅面积只提供了14%的FP16 FLOPS改进 - 这与一个全新架构的预期相去甚远。因为大部分性能增益只是通过增加更多的硅面积和量化来实现的。人们需要了解微扩展(microscaling)的工作原理,并解决使用Blackwell架构进行FP8、FP6和FP4训练的问题。考虑到两倍的硅面积应该需要两倍的功率,分析等功率性能增益是很重要的,即每瓦特功率GPU所实现的FLOPS:
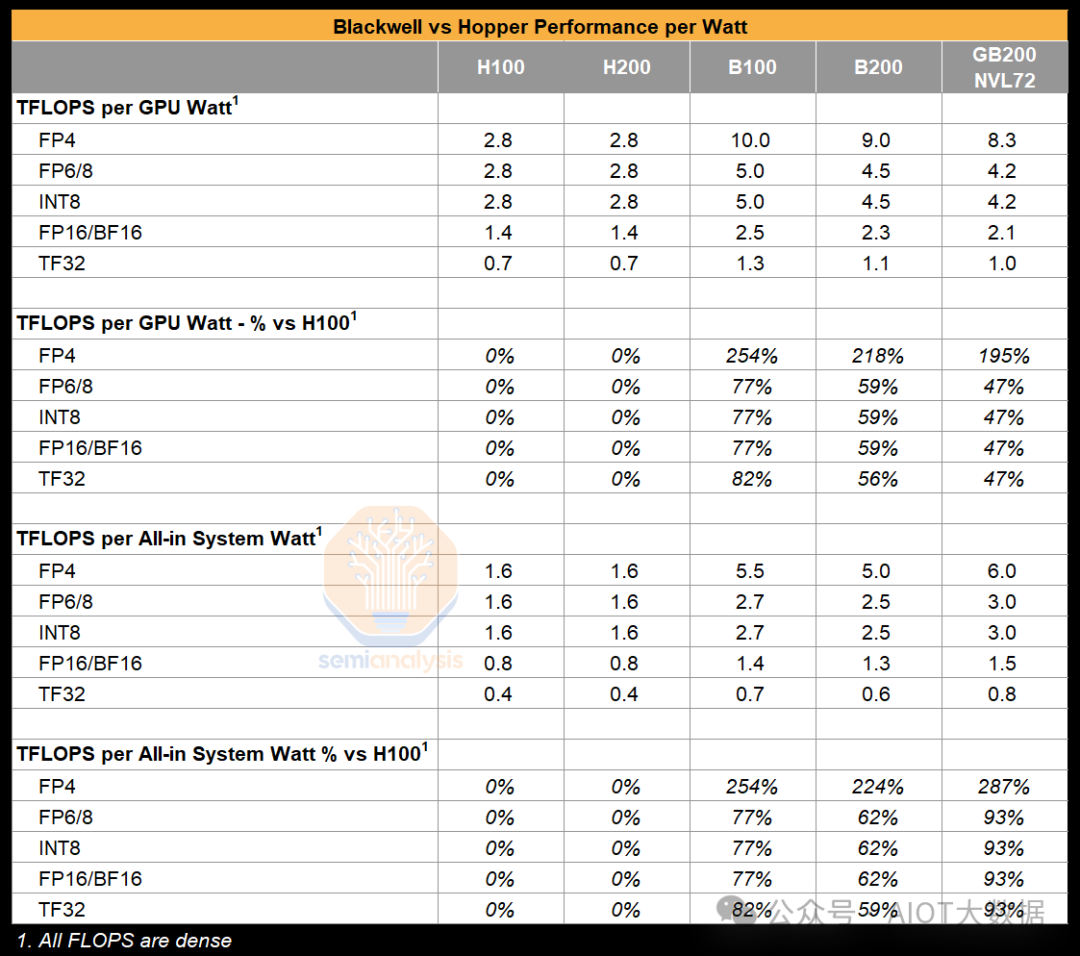
从图中可以看出,GB200每瓦特的TFLOPS比H100提高了47%。
因此在同等工艺制程约束下,芯片的面积越大,晶体管的数量就越多。为了做出地球上最大的芯片,英伟达的Blackwell芯片尺寸是一整块wafer(晶圆)在光刻机曝光极限下所能支持的最大面积:800平方毫米。英伟达表示,做的再大一点,那么整块晶圆估计都会因为物理极限而断裂。
事实上从上面的每瓦特TFLOPS功率效率来看,即便是晶圆在普通情况下,不会因为物理极限而断裂,也会因为工作时候的热量聚集而出现物理损坏或功能紊乱问题。台积电为GB200加工的第一批芯片组Bianca板,就曾经因为每瓦特TFLOPS功率太高,造成的热量聚集不均,出现了传输速率不一致,造成运算紊乱,不得不调低运算速度的BUG,最后英伟达重新设计了Bianca板的基板上,RDL再布线中介层线路与触点,才解决了这个问题。
GB200采用台积电的CoWoS封装,先将半导体芯片(CPU、GPU、存储器等)通过Chip on Wafer(CoW)的封装制程一起连接至中介层(Interposer)上,再通过Wafer on Substrate(WoS)的封装制程将硅中介层连接至底层基板上。
其中,中介层(interposer)一般选用硅(COWOS-S)、有机物(COWOS-R)或者是硅和有机物的结合(COWOS-L)。
GB200芯片组Bianca板在工作时,英伟达推荐的是把Bianca板整面贴在水冷板上进行冷却工作,以提高散热性能和降低每瓦特TFLOPS的功耗,提升算力的输出能力。
玻璃基板的应用
在射频和高功率半导体领域,由于对每瓦功率的散热要求,以及高频数据传输处理的稳定性要求,芯片封装基板从有机板到金属板,再到陶瓷板与玻璃基板,不断的优化中。其中玻璃基板由于有着下面这些优势,成为了高功率、高频率芯片组设计的主要方向:
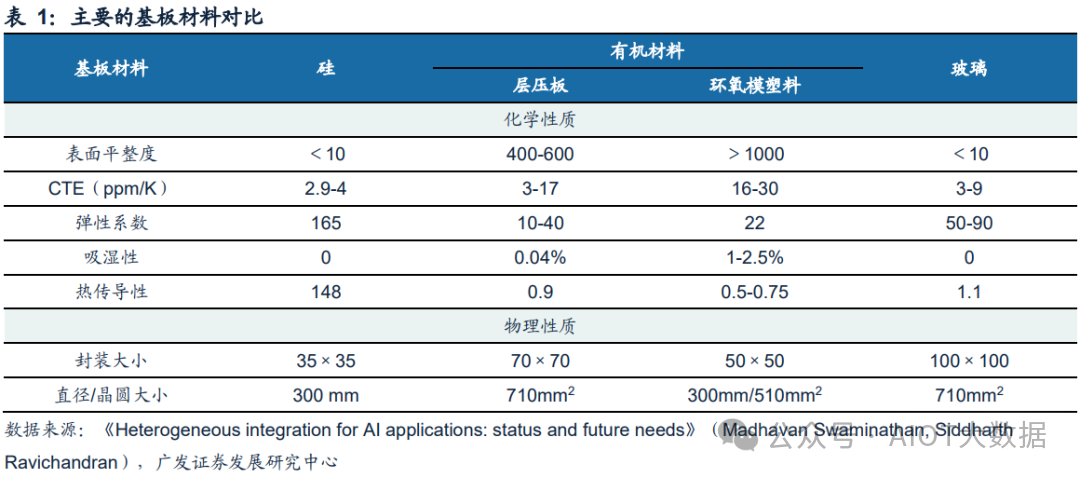
(1)低成本:受益于大尺寸超薄面板玻璃易于获取,以及不需要沉积绝缘层,玻璃转接板的制作成本大约只有硅基转接板的1/8;
(2)优良的高频电学特性:玻璃材料是一种绝缘体材料,介电常数只有硅材料的1/3左右,损耗因子比硅材料低 2~3 个数量级,使得衬底损耗和寄生效应大大减小,可以有效提高传输信号的完整性;
(3)大尺寸超薄玻璃衬底易于获取:康宁、旭硝子以及肖特等玻璃厂商可以量产超大尺寸(大于2 m×2 m)和超薄(小于50μm)的面板玻璃以及超薄柔性玻璃材料;
(4)工艺流程简单:不需要在衬底表面及TGV内壁沉积绝缘层,且超薄转接板不需要二次减薄;
(5)机械稳定性强:当转接板厚度小于100μm时,翘曲依然较小;
(6)应用领域广泛:除了在高频领域有良好应用前景之外,透明、气密性好、耐腐蚀等性能优点使玻璃通孔在光电系统集成领域、MEMS封装领域有巨大的应用前景。
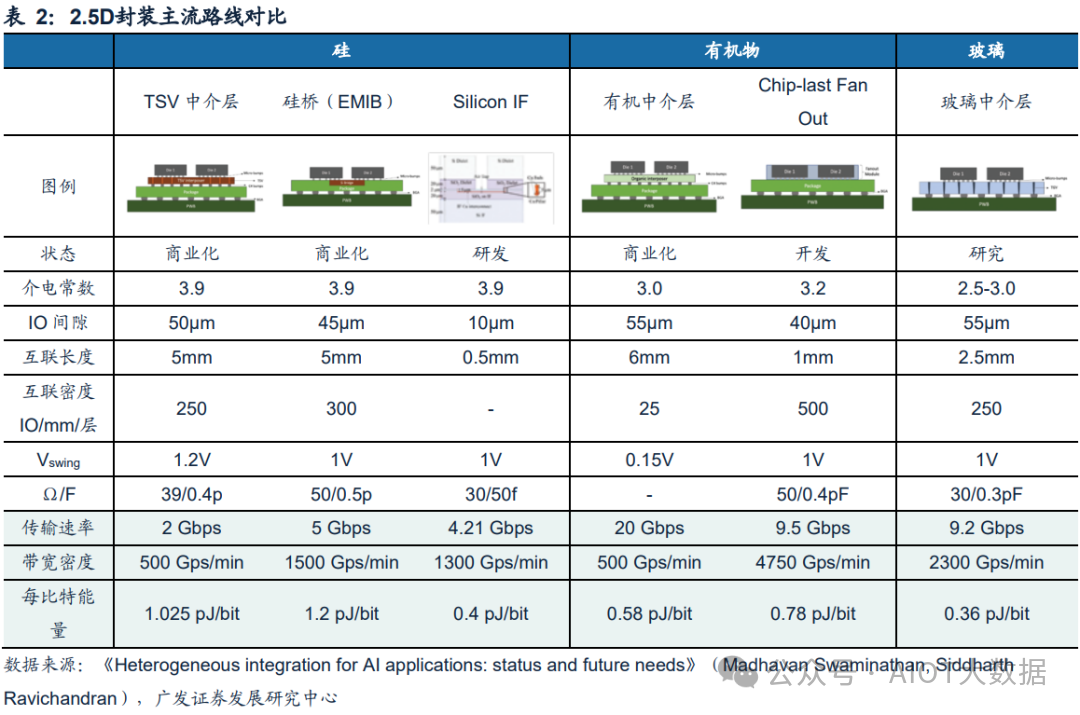
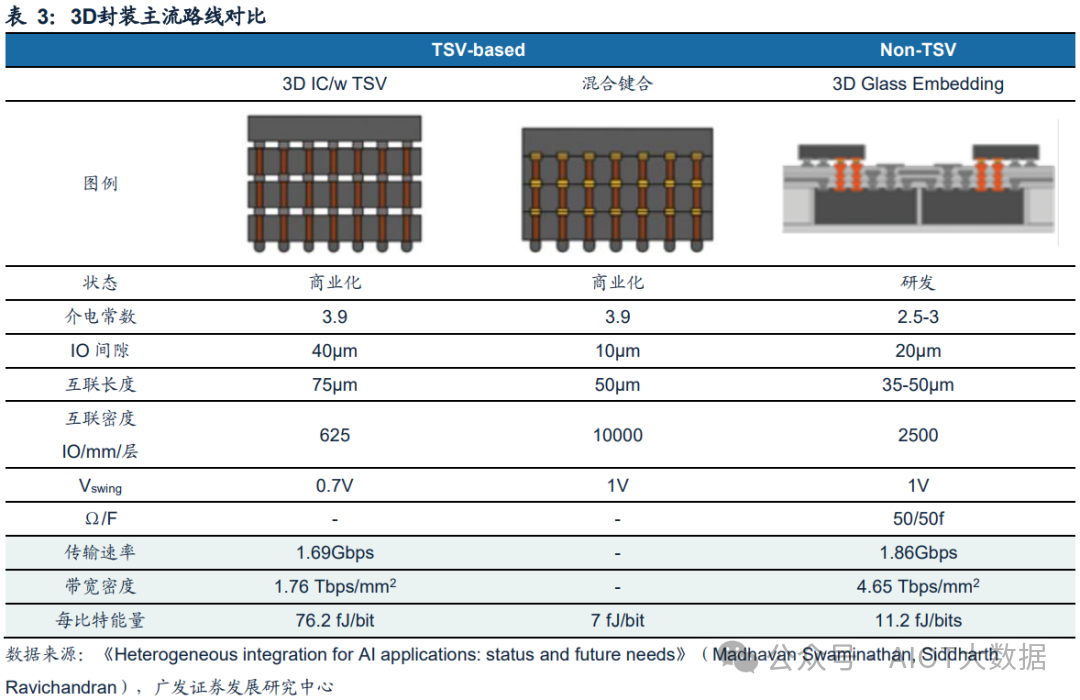
根据《Heterogeneous integration for AI applications: status and future needs》,可以看到玻璃中介层对比硅中介层,拥有更低的介电常数、更短的互联长度和更高的传输速率(约提高3.5倍)以及带宽密度(提高约3倍),同时能耗可以有效降低约2倍,玻璃中介层的优势较为明显。
对于单面线路玻璃基板而言,产品的生产主要采用简单的加成法就能完成。加法制造工艺采用导电金属浆料直接在裸基材上印刷出电路图形并高温烧型,材料利用率高,生产流程便捷、效率高,产品加工成本低、周期短。电路图形是导电金属浆料经过高温烧结成型,剥离强度可达3N/mm以上,比传统覆铜板更可靠。
加成法制作还解决了传统PCB制程工艺中化学沉铜(或真空镀膜)、黄光成像、电镀铜、蚀刻铜等高成本、高能耗、重污染的问题,真正实现节能减排,绿色生产。
玻璃基板加法制造印刷电路的加工能力:
1.基板线路铜厚范围:10~35μm;
2.基板厚度加工范围:min 0.3mm;
3.基板有效加工尺寸:max 300*450mm [注:现有设备尺寸限制,可按需升级大尺寸];
4.印刷最小线路能力:量产100μm,打样75μm。
玻璃基板加法制造电路铜的可靠性:
1.耐常规化学腐蚀,耐热应力,可焊性良好;
2.可正常进行化学蚀刻、表面处理等再加工制程且稳定可靠;
3.线路表面粗糙度低:Ra<0.5μm;
4.线路与基板附着力高:>3N/mm;
5.通过300℃热冲击测试,1000次热循环后无失效,附着力依旧稳定。
异构集成的Chiplet 3D为嵌入式玻璃扇出(eGFO)封装
对于异构集成的Chiplet 3D封装方面:玻璃基板TGV工艺可以在玻璃上制作空腔,进而为芯片的封装提供一种名为嵌入式玻璃扇出(eGFO)的新方案。根据《Heterogeneous integration for AI applications: status and future needs》,这种架构不需要逻辑芯片中的TSV来建立较短的互连长度,因此可以提高信号完整性,减少昂贵芯片的占用空间,并降低整体系统成本。
该解决方案由多个嵌入式芯片和使用RDL连接的组装芯片(玻璃制成)组成,目前这种封装的IO间距可以做到20μm,L/S为2/2μm,并拥有三个金属层,在传输效率、带宽密度、能耗上均有明显优势。
据《玻璃通孔技术研究进展》(陈力等),2013年LEE等人利用玻璃通孔技术实现射频MEMS器件的晶圆级封装,采用电镀方案实现通孔的完全填充,通过该方案制作的射频MEMS器件在20 GHz时具有0.197 dB的低插入损耗和20.032 dB的高返回损耗,在40 GHz以内具有稳定的射频性能;在5G毫米波集成天线封装方面,2020年乔治亚理工的Tummala首次在100 μm的玻璃基板上实现了在n257频段(26.5~29.5 GHz)的芯片嵌入毫米波天线集成模块,该方案相比于倒装芯片嵌入技术具有更低的信号损耗。
同样的,使用TGV工艺制成的TGV-集成天线,可以应用于3D系统封装(SiP)中,能够实现更紧凑、高功率、高效的V波段(40~75 GHz)无线平面内芯片到芯片(C2C)通信。
算力芯片领域,巨头积极投入研发。目前人工智能对数据中心和传输效率提出了更高的要求,尤其是对低功耗、高带宽的光模块的需求更加迫切,而高算力Chiplet芯片离不开Cowos、FOEB等先进封装平台。因此,随着AI芯片尺寸/封装基板越来越大,玻璃基封装被各大公司提上日程,期望玻璃基板能够构建更高性能的多芯片系统级封装(SiP)。
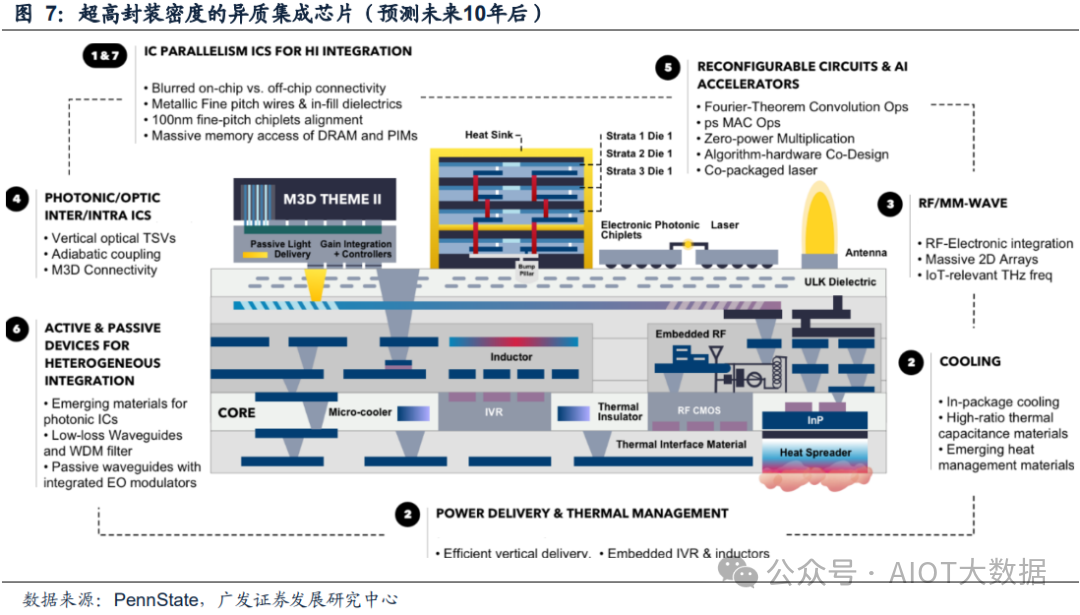
根据宾夕法尼亚大学的预测,未来随着封装工艺的演进异质集成将成为芯片发展的主流路径,参考其给出的未来10年后的超高封装密度集成芯片结构,可以看出如果需要将各模组都集成在同一芯片中,对组件小型化、基板材质都提出了很高的要求。玻璃基板翘曲低、电学性能优异的特点将使其成为下一代核心基板材料的不二之选,而玻璃通孔TGV工艺也将成为高效实现各模块互联的重要工艺。
目前三星、英特尔、谷歌、博通等,都有试作玻璃基板异构3D封装集成Chiplet芯片的产品,并在测试过程中,也证明了相关的电学性能和负载性能稳定性,要比目前行业大批量量产的
而GB200在台积电首批量产出现不稳定现象时,行业与英伟达都深入讨论过利用玻璃基板进行封装的可能性。随后台积电先后购买了两座面板工厂来准备玻璃基板封装产能,也基本上确定是未来英伟达的GPU AI算力芯片,会采用新型的玻璃基板封装。
嵌入式玻璃基板扇出(eGFO)封装关键工艺——TGV和嵌入 (GPE)封装
AI 应用通常需要更大的中介层和非常高密度的互连以实现高带宽。这些严格的要求加上可靠性和性能,要求开发和实施先进的封装技术来构建大型封装。
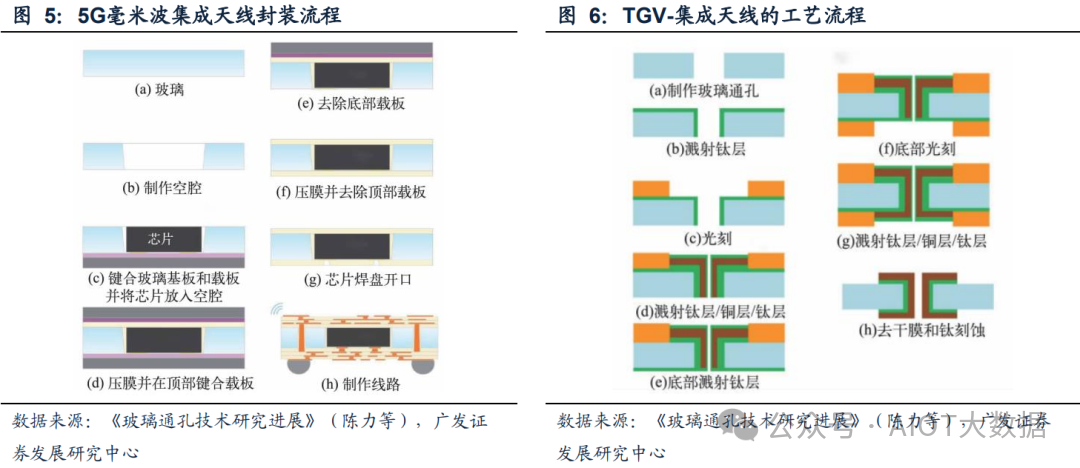
随着对适用于 AI 和 HPC 应用的更先进封装技术的需求,利用玻璃作为核心基板因其众多优势而最近引起了极大关注 。英特尔最近展示了他们的第一款玻璃基板测试芯片,并宣布了他们朝着玻璃封装发展的轨迹,以满足对更强大计算的需求。(图 5(a))韩国 SKC 的子公司 Absolics Inc. 也已开始准备小批量制造(SVM)其玻璃基板(图 5(b)),旨在以亚马逊、Meta 和微软等超大规模企业为潜在客户。

Chiplet异构3D集成玻璃芯封装的优势
基于玻璃的中介层通过提高信号完整性、支持高密度互连、集成光通信、优化热管理以及确保可靠性和可扩展性,增强了用于 AI 应用的半导体封装的带宽能力。这些特性使玻璃中介层成为实现高性能计算和实现高级 AI 功能的重要组件。玻璃表面光滑/表面粗糙度极低,可以实现细线和空间的缩放,这对于实现非常高密度的互连至关重要。
此外,玻璃由 Si-O 键组成的表面结构有助于粘附各种聚合物材料,用作介电树脂和感光树脂。将玻璃的低介电常数与多层中介层结构的低介电常数累积层相结合,可以显着降低系统的延迟。这一特性在最小化信号传播延迟和减少相邻互连之间的串扰方面起着至关重要的作用,尤其有利于高速电子设备和共封装光学器件。
此外,玻璃基板降低了互连之间的电容,从而实现了更快的信号传输并提高了整体系统性能。在数据中心、电信和高性能计算等速度至关重要的关键应用中,采用玻璃基板可以大大提高系统效率并增加数据吞吐量。
玻璃的低介电常数还支持卓越的阻抗控制,这对于保持整个电路的信号完整性至关重要。这一特性在射频应用中尤其有利,因为精确的阻抗匹配对于优化功率传输和最大限度地减少信号损失至关重要。玻璃基板确保整个基板表面的电气特性一致,从而能够设计和生产具有更高可靠性和性能的高频电路。
与有机封装相比,玻璃具有出色的尺寸稳定性,有助于提高层间精度,这是在多层玻璃中介层中实现非常高的互连密度的关键。这不仅有助于减小焊盘尺寸,还有助于将细线和走线缩小到<1μm,从而增加多层中介层中每个再分布层中的IO数量。此外,玻璃基板的热膨胀系数(CTE)在3-12 ppm /℃范围内。这可以减轻玻璃与硅(CTE=3 ppm/℃)芯片以及玻璃与印刷线路板(CTE=17 ppm/℃)之间的 CTE 不匹配问题,能够构造玻璃是封装和中介层应用玻璃芯基板的另一个优势。
玻璃构造可以是以下任何一种类型:(a) 玻璃通孔 (TGV:Through Glass Vias),(b) 盲玻璃腔 (BGC:Blind Glass Cavities),或 (c) 玻璃腔 (TGC:Through Glass Cavities)。
TGV 可以通过激光诱导深蚀刻 (LIDE:Laser Induced Deep Etching) 形成,首先对玻璃进行局部激光修改,然后进行湿化学蚀刻工艺,以最大限度地减少制造过程中微裂纹的积累。BGC 和 TGC 可以通过激光加工轻松形成,必要时可以进行湿蚀刻工艺。
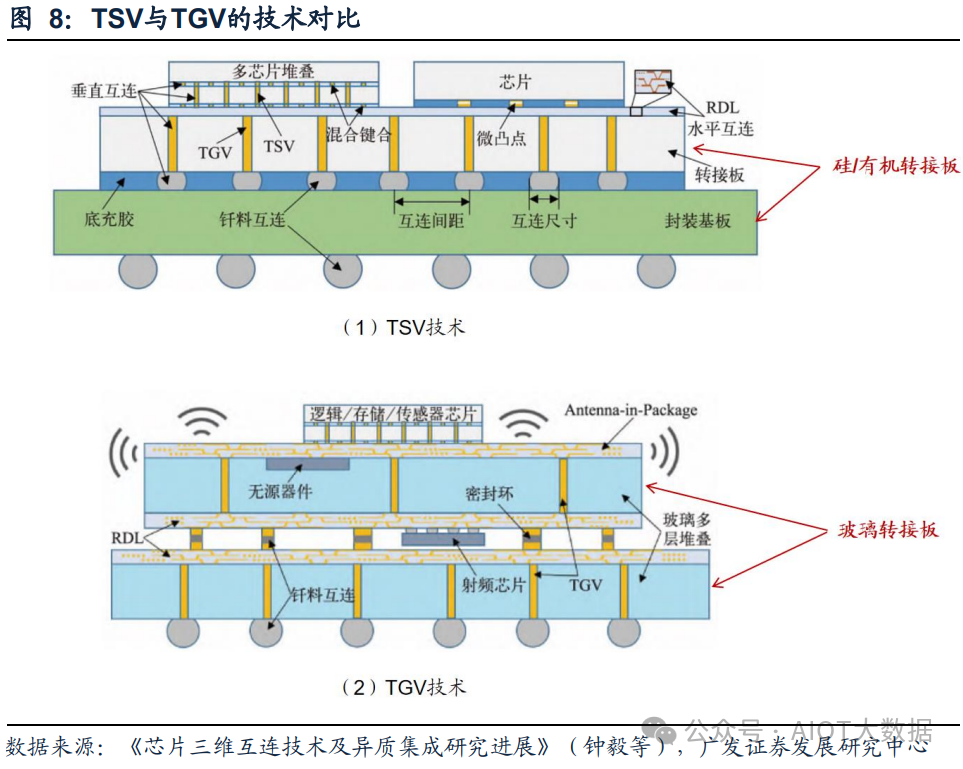
TGV技术是TSV技术的延续,主要区别在于引入了基板种类的变化。
TSV(Through Silicon Via)是指通过在硅中介层打孔的方式实现实现垂直互联,而与之对应的TGV(Through Glass Via,玻璃通孔)是指穿过玻璃基板的垂直电气互连,它们都通过在中介层打孔并进行电镀填充来实现垂直方向的电气互联,以此来降低信号传输的距离,增加带宽和实现封装的小型化。
而与TSV不同的是,TGV的中介层基板使用的是高品质硼硅玻璃、石英玻璃,以此来取得比硅中介层更好的封装表现,被认为是下一代三维集成的关键技术。
TGV作为TSV的低成本替代方案,逐渐受到广泛关注。根据《玻璃通孔技术研究进展》(陈力等),硅基转接板2.5D/3D集成技术作为先进系统集成技术,近年来得到了迅猛的发展,但硅基转接板存在两个主要问题:
(1)成本高,硅通孔(TSV)的制作采用硅刻蚀工艺,随后硅通孔需要氧化绝缘层、薄晶圆的拿持等技术,步骤复杂且流程较长;
(2)电学性能差,硅材料属于半导体材料,传输线在传输信号时,信号与衬底材料有较强的电磁耦合效应,衬底中产生涡流现象,造成信号完整性较差(插损、串扰等)。
TGV省去了沉积隔离层、绝缘层的过程。TGV的制备流程包括,先玻璃基板上进行打孔,然后采用电镀的方法将Cu沉积在基板通孔和正反面已实现电气连接,然后采用CMP的方法将表面Cu层去掉,最后采用PVD镀膜光刻方法制备RDL重布线层,去胶后最终形成钝化层。与TSV的制备流程对比,TGV省去了在衬底表面及TGV内壁沉积绝缘层的步骤(由于铜可以与硅发生反应,因此需要沉积绝缘层、隔离层),并由于玻璃基板本身就可以做的很薄,还可以省去二次减薄的过程。
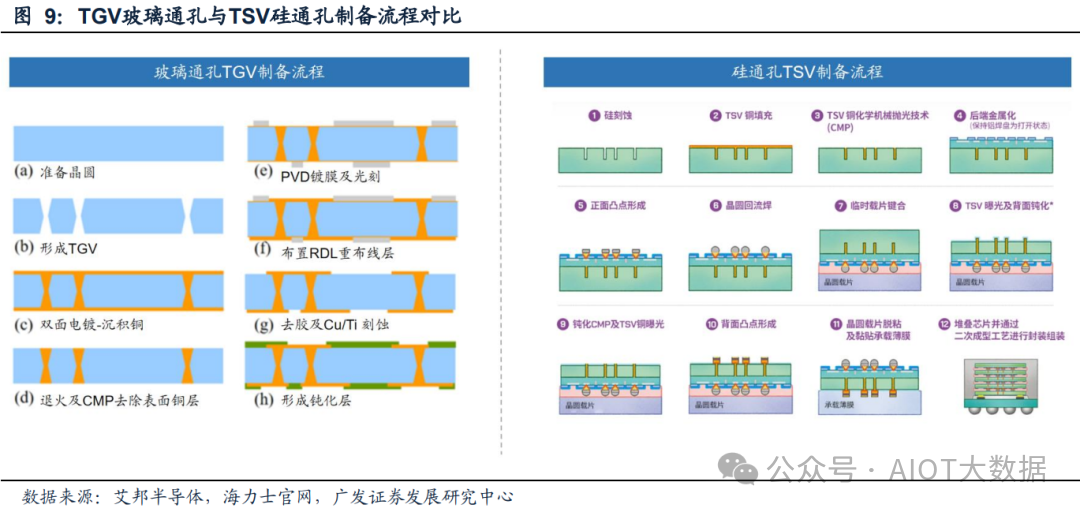
由于TSV技术目前相对比较成熟,已经大规模应用在高带宽存储器HBM的生产中,因此TGV与TSV相同的制备步骤(d)~(h)可以借鉴TSV的成功经验,技术成熟度相对比较高。根据《玻璃通孔三维互连镀铜填充技术发展现状》(纪执敬等),目前TGV中介层面临的挑战主要集中在TGV的通孔成孔工艺以及TGV的高质量填充两方面。
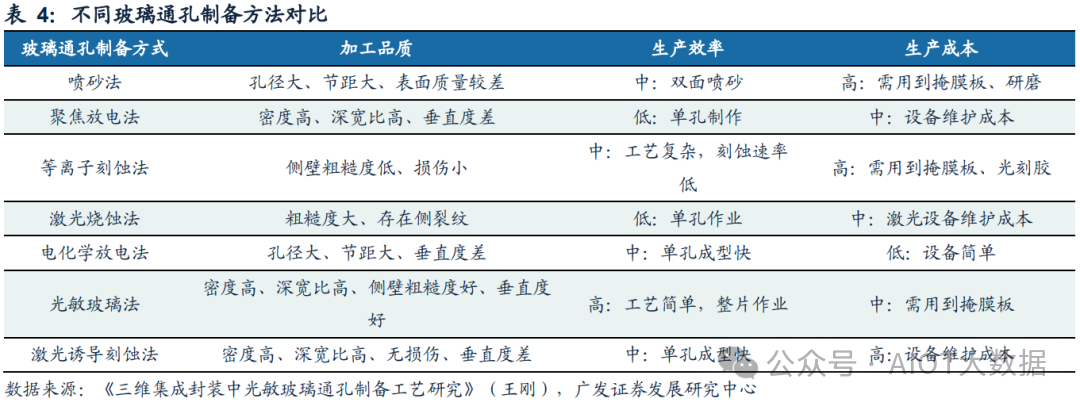
玻璃通孔成孔技术:如何制作高精度的通孔/盲孔
玻璃通孔成孔技术是制约TGV发展的主要困难之一。TGV通孔的制备需要满足高速、高精度、窄节距、侧壁光滑、垂直度好以及低成本等一系列要求,如何制备出高深宽比、窄节距、高垂直度、高侧壁粗糙度、低成本的玻璃微孔一直是多年来各种研究工作的重心。目前主流的玻璃通孔加工成型方法有喷砂法、聚焦放电法、等离子刻蚀法、激光烧蚀法、电化学放电法、光敏玻璃法、激光诱导刻蚀法等。
玻璃基板高密度布线
在完成玻璃通孔的制备后,需要在玻璃基板表面进行布线来实现互联互通的电气连接,相对于有机衬底而言,玻璃表面的粗糙度小,所以在玻璃上可以进行高密度的布线操作。但由于半加成工艺法在线宽小于5μm的时候会面临许多挑战,例如在窄间距内刻蚀种子层容易对铜走线造成损伤且窄间距里的种子层残留易造成漏电,因此针对玻璃基板的表面高密度布线,学界和业界也有不同工艺路线的探索。
线路转移(CTT)和光敏介质嵌入(PTE)
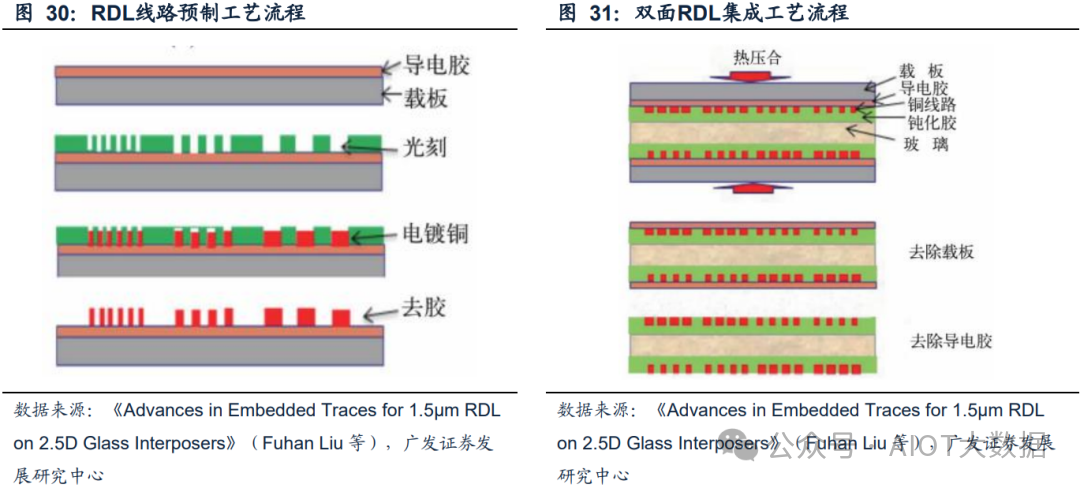
针对在玻璃表面直接进行窄距布线会造成缺陷的问题,刘富汉等人研究开发了线路转移(CTT)和光敏介质嵌入(PTE)。根据《Advances in Embedded Traces for 1.5µm RDL on 2.5D Glass Interposers》,CTT(Copper Trace Transfer,线路转移)主要包括两个过程:
1. 预制RDL线路:首先在可移动载体上单独制造一层薄导电层,通过光刻、电镀和去胶制作出RDL线路,并在转移到基板上之前测试或检查细线成品率。
2. RDL层集成:完成RDL层的制备后,先在玻璃中介层的两面利用钝化胶形成钝化层,随后使用热压合的方式将预制RDL层转移到钝化层上,最后去除载板和导电胶。
PTE(Photo Trench Embedding,光敏介质嵌入)的详细工艺流程包括:
1. 首先刻蚀基板下侧铜箔,并使用真空压膜机在基板上侧压合感光膜;
2. 随后在光刻图案化后进行种子层沉积,采用物理气相沉积(PVD)分别沉积Ti和Cu作为阻挡层和种子层,接着采用电镀工艺填充沟槽;
3. 沟槽填充完后,使用化学腐蚀剂刻蚀掉上表面的铜从而露出线路。

多层RDL的2.5D玻璃转接板技术
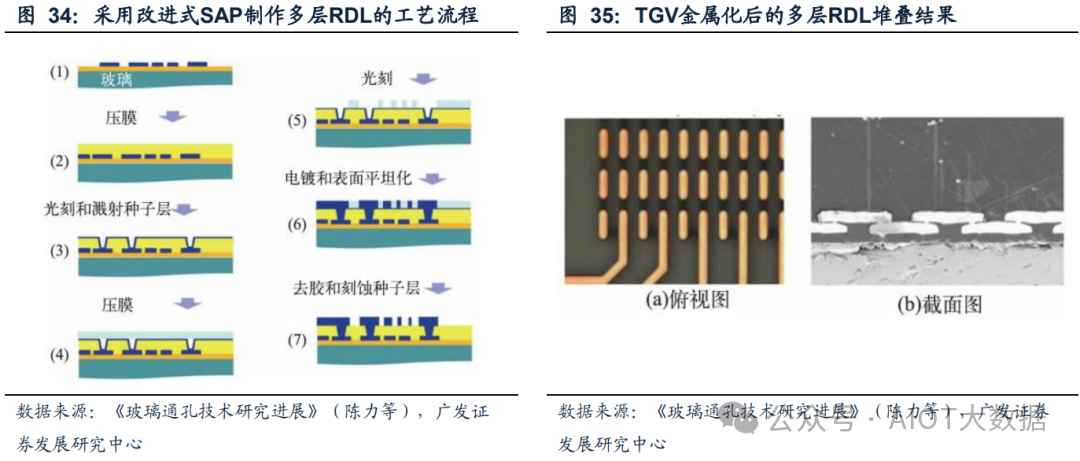
在多层RDL制备领域,乔治亚理工学院的LU等研究了多层RDL的2.5D玻璃转接板技术,实现了面板级光刻后1.5~5 μm的线条沟槽制备,并提出改进式半加成工艺法(SAP)达到了5 μm以下低成本的线宽制作工艺,即用旋转金刚刀取代昂贵的CMP对层间RDL表面平坦化,进而做到低成本多层RDL堆叠。
其工艺步骤包括:
1. 在第一层RDL上进行压膜;
2. 通过光刻和溅射制作通孔并暴露出第一层 RDL的铜焊盘,然后进行种子层溅射;
3. 随后将高分辨率的光刻薄膜层压在基板,进行曝光显影来显露第二层的RDL图案;
4. 随后采用电镀工艺填充通孔形成RDL线路,并用旋转金刚刀进行表面平坦化,去除光刻薄膜并完成种子层刻蚀。
玻璃基板嵌入 (GPE)
BGC 和 TGC 对于将芯片嵌入 BGC 和 TGC 非常重要,这被称为玻璃面板嵌入 (GPE)。制造所需尺寸的腔体,并使用精度为几微米的自动芯片拾取和放置工具将芯片放入这些腔体中。
GPE 工艺非常适合异构集成,其中不同尺寸和功能的芯片(包括电容器和磁电感器等无源元件)内置在封装中。在这种方法中,电容器和电感器保持在靠近电力输送/IVR 等应用所需的位置。
GPE 中使用的典型工艺流程
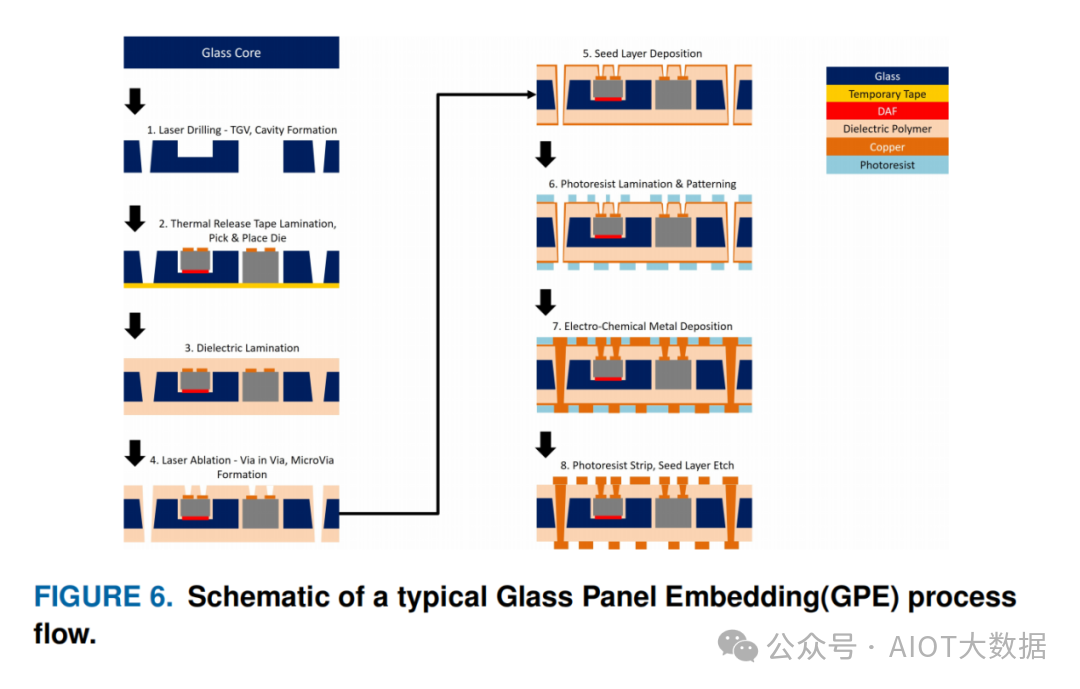
利用先进的 GPE 工艺,可以轻松地将热解决方案集成到封装中以消除热量。例如,对于带有 TGC 的 GPE,可以将隔热材料和散热器附着到玻璃基板的背面。对于 BGC,可以在减薄/研磨基板后加入散热器来消除热量。GPE 架构可以轻松地从 2.5D 架构调整为包括 3D 集成,其中可以使用以下方法之一:
(a)例如,可以将逻辑芯片与玻璃芯顶部和底部的 RDL 一起嵌入玻璃腔中,然后在顶部组装存储器芯片以生成具有短互连距离和小得多的外形尺寸的 3D 结构,从而显着降低封装的高度;
(b)无源芯片可以嵌入结构化玻璃中,并且可以通过倒装芯片工艺在玻璃封装结构上组装多个芯片 ;
(c) 此外,GPE 实现了共封装光学器件等先进封装概念,其中可以将电子芯片嵌入玻璃腔体(芯片背面采用上述散热解决方案),并在封装顶部组装光子芯片 (PIC)。通过将 PIC 安装在顶部,可以轻松地从顶部安装光纤耦合器以及任何所需的散热解决方案。
最后,除了各种优越的性能外,玻璃对封装中基板格式的限制更少。虽然硅只能在圆形晶圆中加工,但玻璃可以实现面板工艺,从而降低成本。例如,300 毫米晶圆可容纳 2,500 个 6 毫米 x 6 毫米尺寸的封装,而 600 毫米 x 600 毫米面板可容纳 12,000 个封装。
目前玻璃的限制
玻璃基板固有的易碎性带来了重大挑战,尤其是当行业采用更薄的基板来满足对更高设备集成度和性能的需求时。薄玻璃板有时薄至 100µm 或更薄,在处理和制造过程中特别容易损坏。这种在压力下开裂或破碎的风险凸显了专门设备和定制工艺的必要性,这些工艺旨在安全地处理这种材料。
除了处理困难之外,玻璃还表现出相对较低的散热性。尽管玻璃比有机层压板导热性更好,但与硅相比,玻璃的导热性较差。为了克服与玻璃导热性低相关的限制,已经证明了将铜结构(例如通孔封装通孔 (TPV)、铜块和重分布层 (RDL) 中的铜迹线)结合到玻璃基板中的方法 [107]。此外,用于嵌入式和基于基板的封装的下一代热界面材料 (TIM) 也正在积极开发中,重点是降低热界面电阻,以实现芯片的最大热传递。
-
玻璃基板怎么制作?2020-04-03 3815
-
玻璃基板简介及生产流程2010-12-15 2597
-
玻璃基板/Ambix,玻璃基板/Ambix是什么意思2010-03-27 2507
-
玻璃基板:封装材料的革新之路2024-05-17 4439
-
玻璃基板时代,TGV技术引领基板封装2024-05-30 6158
-
英特尔是如何实现玻璃基板的?2024-07-22 1174
-
热门的玻璃基板,相比有机基板,怎么切?2024-08-30 1849
-
玻璃基板的技术优势有哪些2024-10-15 1948
-
玻璃基板的四大关键技术挑战2024-11-24 2159
-
AMD加入玻璃基板战局2024-11-28 1353
-
AMD获得玻璃核心基板技术专利2024-12-06 1013
-
玻璃基板、柔性基板和陶瓷基板的优劣势2024-12-25 4523
-
玻璃基板基础知识2024-12-31 2704
-
迎接玻璃基板时代:TGV技术引领下一代先进封装发展2025-01-23 4067
-
芯片封装用玻璃基板四大核心技术一览2026-03-21 495
全部0条评论

快来发表一下你的评论吧 !
