

高密度Interposer封装设计的SI分析
电子说
描述
原创 StrivingJallan 芯片SIPI设计
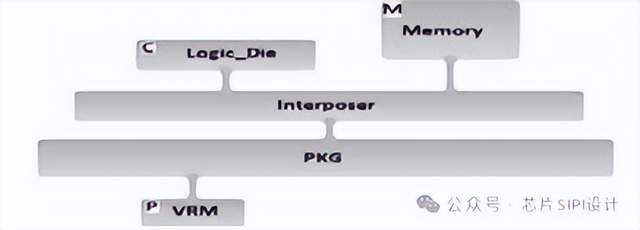
为了克服硅中间层技术的尺寸限制,并实现更好的处理器和存储器集成,开发了一种基于硅interposer的新型2.5D SiP,如图所示。多个芯片集成在一个接口层(interposer)上,用高密度、薄互连连接,这种高密度的信号,再加上硅interposer设计,需要仔细的设计和彻底的时序分析。

对于需要在处理器和大容量存储器单元之间进行高速数据传输的高端内存密集型应用程序来说,走线宽度和长度是一个主要挑战。HBM以更小的外形实现更高的带宽,同时使用更少的功耗,interposer技术最适合峰值带宽、每瓦带宽和每区域容量是有价值指标的应用,例如图形应用处理器单元(gpu)、高性能计算、服务器、网络和客户端应用。
下图为Si interposer设计侧视图:两个芯片并排放置,通过金属层走线连接。硅interposer用于建立具有高密度凸点的die to die连接。其他连接则通过interposer直接连接到IC封装基板。给出了芯片RDL在集成电路设计环境中的布局,以及封装设计环境中芯片RDL在封装顶部的布局。

为了获得良好的SI性能,系统封装必须具有低传输损耗和短信号路径达到所要求的电气规格,由于高密度互连路由,interposer集成导致新的电气挑战。总功耗的降低要求在尽可能低的电压和最高可靠的频率下运行。这导致需要将电感与位于晶体管上的decap,以保持电压,独立于正在执行的操作,并降低接地电阻。由于必须在一个封装中平衡多种要求,例如降低电压,增加晶体管数量,以及模拟和混合信号设计,因此提出了新的挑战。
下图显示了带有逻辑和存储芯片的interposer层的示意图,两个DIE并排组装,使用细铜线来进行DIE to DIE连接。

整个存储系统使用硅interposer集成到封装中,如下图所示,interposer尺寸为30mm × 25mm。中间层顶部附有20mm × 24mm的高性能处理器芯片。完全集成的内存系统包括四层HBM内存,带宽为512GB/s。处理器和HBM都使用micro bump连接到interposer上。interposer通过传统的倒装芯片bump安装在基板上,处理器有189000个micro bumps,中间处理器有34000多个倒装芯片bump。四个DIE以2.5mm的间隙并排放置。线宽为2μm实现了die to die连接,为了提高布局的性能,处理器DIE被分成六个具有相同数量bump的DIE,从D1到D6,如下图所示。

下图显示了回波损耗和插入损耗,左图显示回波损耗小于-22dB,可以支持最高可达2800MT/s interposer数据传输设计;右图显示了PoP设计的回波损耗和插入损耗。在2800MT/s传输速率的介面设计中,插入损耗为-1dB。
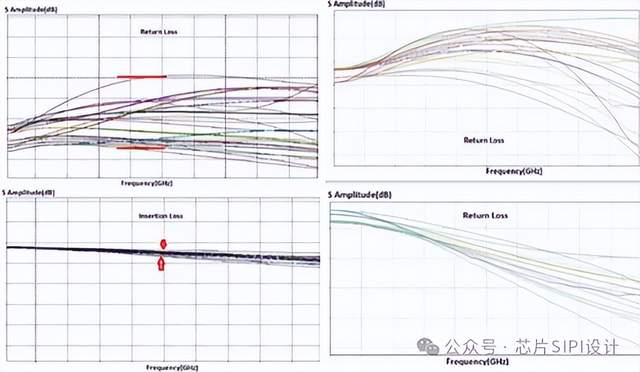
结果表明,与传统的PoP 技术相比,interposer具有更好的回波损耗和插入损耗性能。回波损耗提高了-8dB,反演损耗提高了-1dB,通过在互连之间使用接地保护带,可以最大限度地减少interposer中的串扰。接下来是进行时域分析,下图是含有interposer结构的仿真拓扑。
在仿真中,interposer表示与HBM互连的处理器的s参数,为了准确地仿真IO切换行为,IBIS模型分别应用到处理器和HBM模块中。下图为POP封装仿真拓扑。

对于SI分析,时域仿真使用s参数模型来检查眼图打开和抖动,为了电源的完整性,s参数可以简化为检查频域的输入阻抗曲线。
眼高和抖动通过眼图仿真得到,interposer和PoP设计的仿真结果分别如下图左右所示。与PoP封装相比,左侧为带有interposer设计,右侧结果为Pop封装结果,可以看到interposer的设计有更大的眼图开窗。

与 PoP设计相比,interposer设计中的抖动也更好,interposer中HBM和处理器芯片之间的互连长度更小/更短,这都表明interposer技术提高了SI 的性能。
声明:本网站部分文章转载自网络,转发仅为更大范围传播。 转载文章版权归原作者所有,如有异议,请联系我们修改或删除。联系邮箱:viviz@actintl.com.hk, 电话:0755-25988573
审核编辑 黄宇
-
器件高密度BGA封装设计2009-09-12 5717
-
探讨高密度小间距LED屏工艺2019-01-25 3180
-
Altera器件高密度BGA封装设计2009-06-16 1199
-
高密度封装技术推动测试技术发展2009-12-14 841
-
高密度(HD)电路的设计 (主指BGA封装的布线设计)2009-03-25 1778
-
高速高密度PCB的SI问题2011-09-09 1394
-
Mentor推出独特端到端Xpedition高密度先进封装流程2017-06-27 2603
-
Cyntec高密度uPOL模块的特点2021-10-29 2793
-
高密度互连印刷电路板如何实现高密度互连HDIne ?2023-06-01 1381
-
高密度布线设计指南2023-09-01 771
-
器件高密度BGA封装设计-Altera.zip2022-12-30 718
-
高密度互连印刷电路板:如何实现高密度互连 HDI2023-12-05 2367
-
高密度封装失效分析关键技术和方法2025-03-05 1948
-
光纤高密度odf是怎么样的2025-04-14 2115
-
高密度配线架和中密度的区别2025-06-13 1236
全部0条评论

快来发表一下你的评论吧 !
