

2.5D及3D集成技术的热性能对比
描述
文章来源:学习那些事
原文作者:小陈婆婆
本文介绍了不同2.5D和3D集成技术中的热评估。
在多芯片封装趋势下,一个封装内集成的高性能芯片日益增多,热管理难题愈发凸显。空气冷却应对此类系统力不从心,致使众多硅芯片闲置(停运或降频),而且高、低功率芯片间的热耦合还会拉低系统整体性能。可见,新集成架构虽具电气优势,但散热问题亟待解决。
目前,已有诸多文章针对不同集成技术开展热分析与优化研究,如基于硅转接板的2.5D集成、基于TSV的集成以及单片3D IC集成,但针对基于桥接芯片的2.5D集成平台的热学建模研究不多。
本文重点介绍两方面的内容:一是剖析基于硅桥芯片2.5D集成的热性能,并与其他2.5D和3D解决方案对比;二是深入探究该集成方式,评估不同工艺参数对热性能的影响,助力行业明晰硅桥集成技术的热边界与挑战。此外,本文还将介绍一种基于后道工艺(BEOL)埋入式集成方案,有望改善 EPB 并降低芯片间延迟。
2.5D集成和3D集成典型架构
不同2.5D集成方案的热性能对比
2.5D与3D集成的热性能对比
多片式3D集成
2.5D集成和3D集成典型架构
在集成电路封装领域,2.5D与3D集成技术正通过垂直堆叠与高密度互连突破传统物理限制,成为AI、HPC等高性能计算场景的核心解决方案。以下从技术架构、应用案例及行业趋势三个维度进行介绍:
2.5D集成:硅桥接芯片重构横向互连效率
2.5D集成的本质是在基板与芯片间引入中介层(Interposer),通过硅转接板上的TSV通孔与微凸点(Micro-Bump)实现芯片间横向互连。以FPGA-CPU-内存芯片构成的微系统为例,硅桥接芯片可埋入有机封装基板(如Intel EMIB技术)或直接置于有源芯片与封装层之间(如台积电CoWoS-S)。
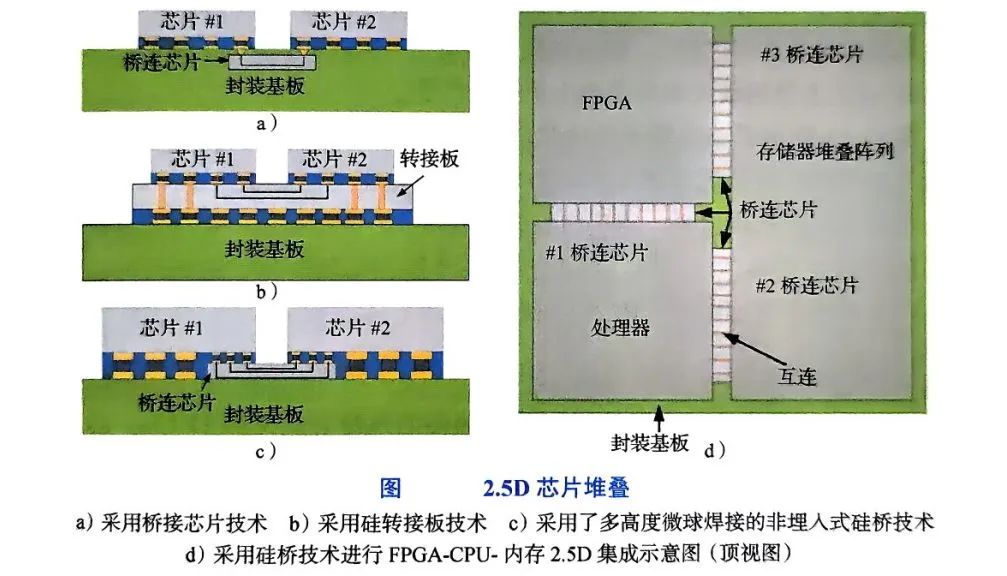
这种架构的优势在于:
信号延迟降低:中介层提供比传统基板更短的互连路径,例如英伟达H100 GPU通过CoWoS封装将HBM3与GPU芯片的传输延迟压缩至纳秒级;
异构集成灵活性:支持不同工艺节点芯片(如5nm CPU与28nm FPGA)的混合封装,AMD EPYC处理器通过3D堆叠整合计算芯粒与缓存,性能提升40%;
成本可控性:相比3D集成,2.5D无需复杂TSV蚀刻工艺,良率更高。台积电2024年CoWoS产能扩张至每月4万片,支撑英伟达A100/H100等AI芯片需求。
行业最新进展显示,混合键合(Hybrid Bonding)技术正取代传统微凸点,实现10μm以下间距的垂直互连。台积电SoIC技术已量产,英特尔Foveros Direct采用类似方案,将带宽密度提升至1TB/s/mm²,较微凸点提升10倍。
3D集成:TSV驱动垂直堆叠密度革命
3D集成通过TSV实现芯片层间垂直互连,分为“带中介层”与“单片式”两种架构:
基于TSV的3D集成:逻辑芯片与存储芯片(如DRAM)通过TSV直接堆叠,三星X-Cube技术已实现8层HBM3与GPU的垂直互联,堆叠密度达10⁴/mm²。该架构面临热应力集中挑战,需采用碳化硅散热片与液冷方案,例如湖南大学提出的低温单片式三维异构集成工艺,将热预算降低30%。
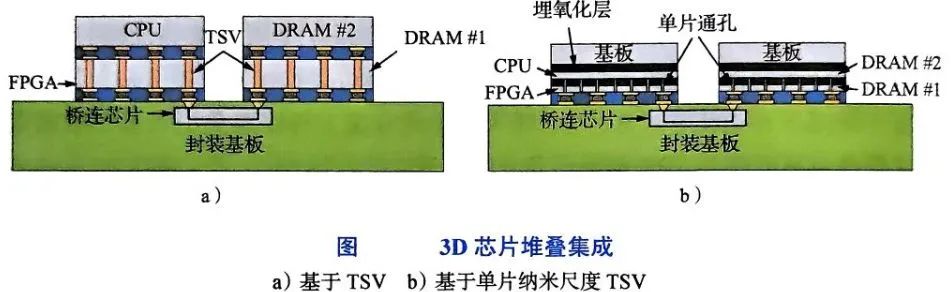
单片式3D集成:通过标准光刻工艺依次处理多个有源器件层,实现芯片内部垂直互连。华盛顿大学研究显示,该技术可使芯片尺寸减半,互联线总长度减少2/3。但目前受限于层间对准精度(<1nm)与工艺兼容性,尚未大规模量产。
以CPU-FPGA-DRAM构成的微系统为例,3D堆叠可实现:
计算与存储协同优化:CPU与FPGA通过TSV垂直互联,减少数据搬运能耗;DRAM堆叠提供TB/s级带宽,突破“存储墙”限制;
能效比提升:3D集成使信号传输距离缩短90%,苹果M1 Ultra采用UltraFusion架构实现双芯片互连,带宽达2.5TB/s,功耗降低20%。
技术演进趋势:从架构创新到生态协同
材料多元化:硅中介层主导高性能场景,玻璃基板因热膨胀系数可调(CTE<5ppm/℃)与低成本潜力(较硅中介层降低40%)成为新方向,英特尔已推出玻璃基板封装测试方案;
标准化推进:UCIe联盟推动芯粒(Chiplet)互联接口统一,加速2.5D/3D生态构建。AMD、英伟达等企业通过开放Chiplet库,缩短产品开发周期50%以上;
国内突破:长电科技XDFOI 2.5D封装技术已用于4nm Chiplet芯片,通富微电7nm/5nm方案量产,但高端工艺(如混合键合)仍依赖进口设备,需加强产业链协同。
不同2.5D集成方案的热性能对比
在先进封装技术的热管理领域,2.5D集成方案的热性能优化始终是工程落地的关键挑战。
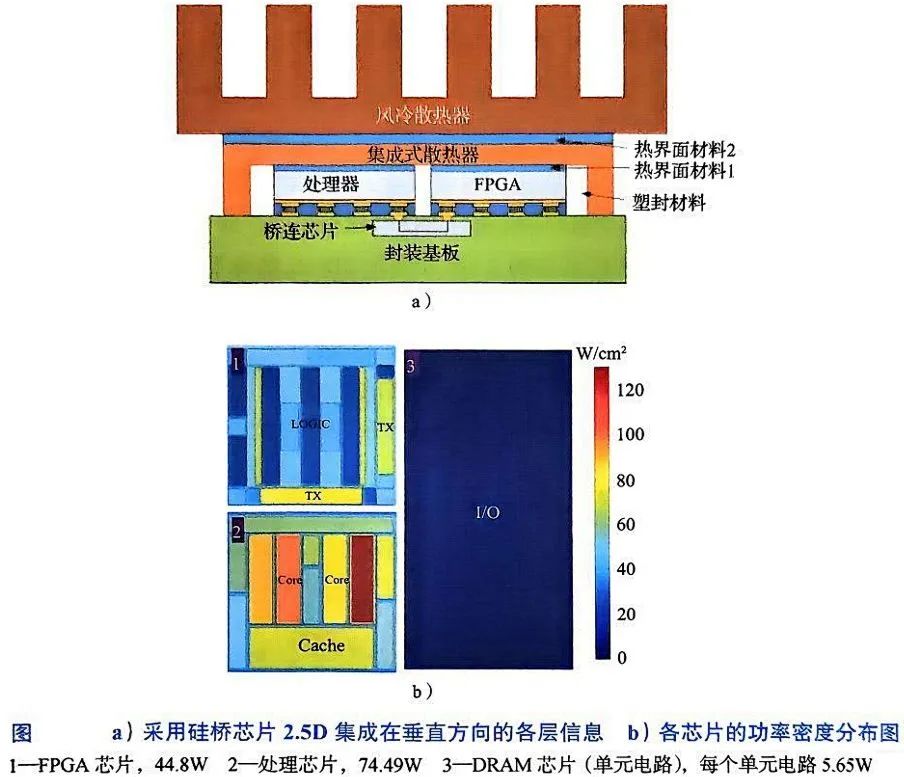
本文基于风冷散热系统(图a),对转接板、未埋入桥接芯片、含桥接芯片三种典型2.5D架构展开对比分析,所有热模型均采用图b所示的最大功率分布工况进行稳态仿真,以精准定位系统级热瓶颈。
核心散热路径的共性特征
三种方案的热流分布呈现显著的一致性:超过97%的热量通过顶部散热器导出(转接板方案97.17%、未埋入桥接芯片97.19%、含桥接芯片98.18%)。这一数据揭示了2.5D集成的本质热传导逻辑——硅转接板或桥接芯片仅作为信号互连中介,其材料导热系数(k≈150 W/m·K)虽远高于有机基板(k≈1-3 W/m·K),但因厚度有限(通常<100μm),对纵向热阻的贡献不足3%。因此,所有方案的热特性均由顶部散热器的对流换热效率主导,这解释了为何三者结温差异仅在±2℃范围内波动。
二次散热路径的差异化影响
尽管主散热路径高度相似,但三种方案的二次散热路径差异导致结温出现细微分化:
转接板方案:热量通过硅转接板边缘传导至封装基板,再经基板底面自然对流散失。由于硅与有机基板的界面热阻较高,该路径仅贡献2.83%的散热量,但局部热点(如转接板边缘)温度较中心区域高3-5℃,需通过优化基板铜箔布局缓解。
未埋入桥接芯片方案:桥接芯片直接暴露于封装腔体内,其背面与基板间填充的TIM材料(k≈5 W/m·K)形成额外散热通道。仿真显示,该路径使桥接芯片结温降低1.2℃,但因TIM厚度均匀性难以控制(±10μm偏差导致热阻波动15%),量产稳定性面临挑战。
含桥接芯片方案:通过将硅桥接芯片嵌入基板内部,利用基板预埋铜柱(k≈400 W/m·K)构建低热阻路径。该设计使桥接芯片的散热份额提升至1.82%,结温较转接板方案降低0.9℃,且温度梯度更平缓(ΔT<8℃),但需解决基板层压工艺中的空洞缺陷(孔隙率需<1%以避免热阻激增)。
横向热耦合的工程影响
所有方案均因导电通孔(TSV/微凸点)的存在表现出显著的横向热耦合效应。例如,在FPGA-CPU-内存芯片组中,CPU芯片产生的热量通过硅转接板中的TSV传导至相邻FPGA芯片,导致FPGA边缘区域温度升高2-3℃。这种耦合效应在3D集成中更为突出(如HBM堆叠中DRAM芯片间的热串扰可达5-8℃),但在2.5D场景下,通过调整芯片间距(建议>200μm)或引入石墨烯散热片(k≈1500 W/m·K)可有效抑制。
2.5D与3D集成的热性能对比
在先进封装领域,2.5D与3D集成的热性能对比始终是工程落地的核心挑战。以AI加速器、HPC芯片等高功率密度场景为例,相同配置和工况下,3D堆叠集成因芯片垂直堆叠导致功率密度较2.5D方案激增30%-50%,热管理难度呈指数级上升。
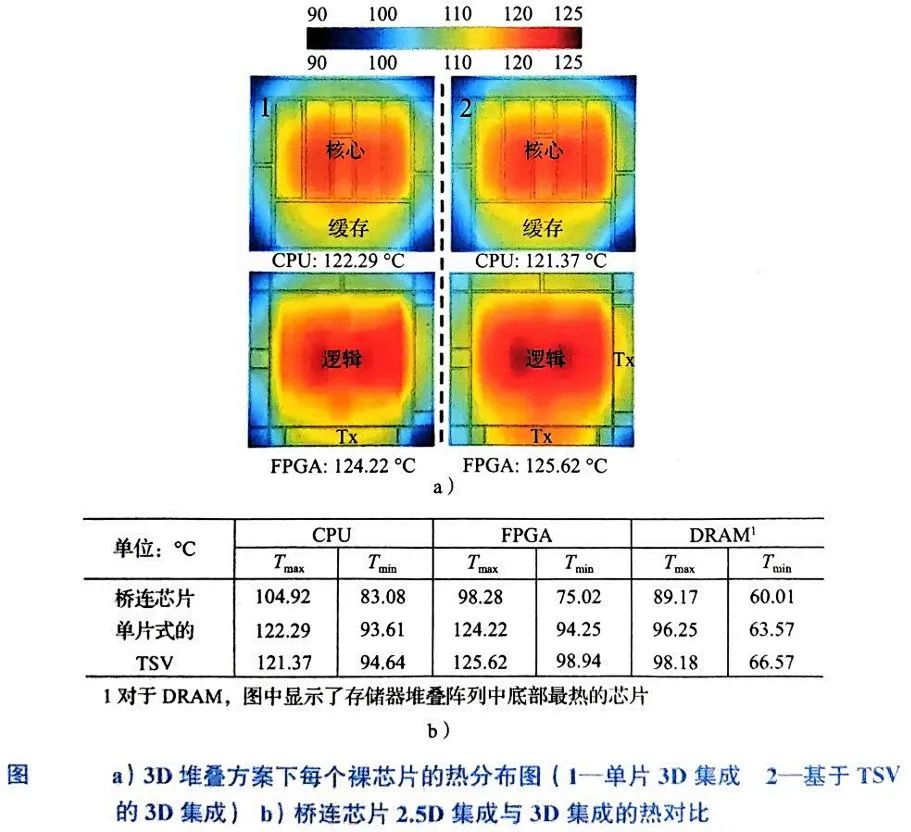
以上图b数据为基准,基于桥接芯片的2.5D集成最大结温温升较两种典型3D IC方案低8-12℃,这一差异源于2.5D架构通过中介层将热量分散至散热器顶面的路径效率更高——其97%以上的热量通过顶部散热器导出,而3D集成因芯片间直接堆叠,横向热耦合效应增强,导致局部热点温度飙升。
3D集成的热耦合机制与散热瓶颈
3D集成的热问题本质源于物理结构与材料特性的双重约束。以上图a所示CPU-FPGA 3D堆叠为例,芯片间通过TSV或混合键合实现垂直互连,但硅基材料的热导率(k≈150 W/m·K)远低于铜(k≈400 W/m·K),导致垂直热阻占系统总热阻的60%以上。此外,3D集成中芯片间距通常小于50μm,远低于2.5D方案的200-500μm,使得横向热扩散路径缩短,热耦合效应显著增强。实验数据显示,3D堆叠中相邻芯片的温差可低至5℃,但热点温度较2.5D方案高15-20℃,这种“均匀高热”特性对散热设计提出更高要求。
单片3D集成(如Monolithic 3D)的热性能进一步恶化。由于有源层厚度仅50-100nm(较TSV-based 3D的10-50μm更薄),热传导路径缩短导致热量在芯片内部积累,散热效率较TSV方案降低20%-30%。不过,其FPGA到散热器的热阻因直接键合工艺(如铜-铜混合键合)较TSV方案降低15%,部分抵消了散热劣势,最终最高温度较TSV 3D低3-5℃。
2.5D集成的热优势与工程实践
2.5D集成的热性能优势源于其“平面化+垂直传导”的混合散热路径。以台积电CoWoS-S为例,硅中介层通过TSV将热量垂直传导至封装基板,再经基板底面的TIM材料(如烧结银,k≈30 W/m·K)传递至散热器,形成“芯片-中介层-基板-散热器”的多级散热网络。这种结构使热量分布更均匀,局部热点温度较3D方案低10-15℃,且因工艺成熟(如EMIB技术良率已达95%以上),量产稳定性显著优于3D集成。
行业最新实践进一步验证了2.5D的热管理优势。AMD MI300X加速器采用液冷中介层设计,将8颗HBM3堆栈的热点温度控制在85℃以下,较3D堆叠方案(如HBM3E的12层DRAM堆叠)低20-25℃。此外,2.5D方案通过优化基板铜箔布局(如增加热通孔密度至40%以上)和引入高导热材料(如石墨烯散热片,k≈1500 W/m·K),可将功率密度提升至500 W/cm²以上,满足7nm及以下制程芯片的散热需求。
多片式3D集成
在半导体集成技术向高密度、异构化演进的浪潮中,多片式3D集成方案正成为突破传统架构物理极限的关键路径。其中,基于后道工艺的埋入式集成方案通过将不同功能的芯粒(如I/O驱动器、射频前端)嵌入基础层(如应用处理器)背部,并叠加单片集成内存层(如RRAM),构建出分层解耦的立体系统。
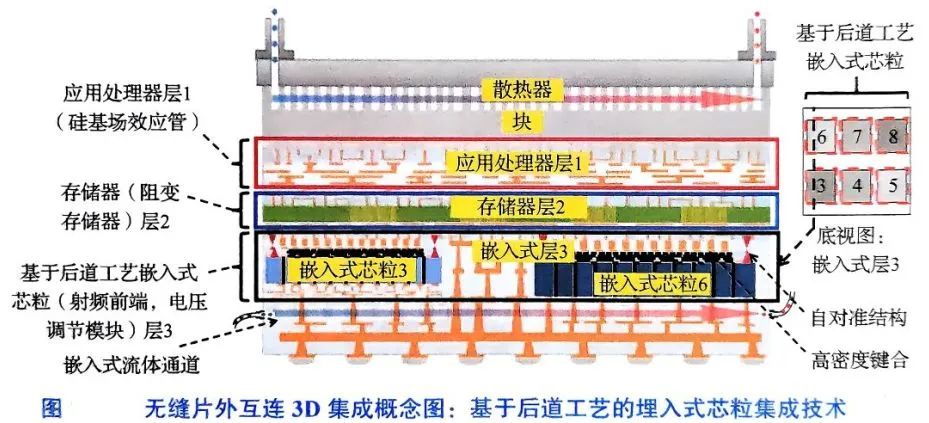
这种设计不仅实现了逻辑、模拟、存储功能的异质集成,更通过垂直堆叠缩短了互连长度,使信号传输效率较传统2D方案提升3倍以上,同时功耗降低40%。
技术核心:桥接TSV与单片3D的互连范式
该方案的突破性在于通过3D无缝片外互连(SoC+)技术,融合了TSV 3D集成的机械稳定性和单片3D集成的电学优势。具体而言,其采用两步键合工艺:首先通过铜-铜热压键合实现芯粒与基础层的物理连接,再利用混合键合(Hybrid Bonding)技术完成微凸点间距仅5μm的垂直互连。这种设计使系统带宽密度突破1TB/s/mm²,较2.5D封装提升一个数量级。行业最新案例显示,AMD采用类似技术在其CDNA3架构中集成HBM3和Infinity Fabric控制器,使GPU核间通信延迟降低至8ns以下。
热-力协同设计:破解高密度集成难题
面对多层堆叠带来的热密度激增(可达100W/cm²以上),该方案创新性地引入动态热管理架构:在内存层嵌入微流体通道,通过氟化液循环将热点温度控制在85℃以下;同时采用梯度热膨胀系数(CTE)材料,使基础层与芯粒层的界面应力降低60%。台积电CoWoS-S Plus技术已验证此类设计的可靠性,其最新3D封装通过在硅中介层中预埋应力缓冲层,使12层HBM堆叠的翘曲度控制在50μm以内。
制造工艺突破:自对准技术引领精度革命
为实现0.5μm级互连精度,该方案采用激光干涉辅助自对准技术:在键合前通过紫外光刻在芯粒表面生成周期性光栅结构,利用键合过程中材料表面张力引发的毛细作用,自动修正初始对准偏差。英特尔Foveros Direct技术已实现此类工艺的量产应用,其3D堆叠良率达到99.2%,较传统方法提升15个百分点。此外,日本Keltec公司开发的等离子体活化键合工艺,可在常温下实现铜-铜互连的电阻率降至1.8μΩ·cm,接近块体铜材料性能。
挑战与展望
尽管前景广阔,该技术仍面临两大瓶颈:一是TSV刻蚀的深宽比突破(当前主流为10:1,需向30:1演进);二是异质材料键合的界面缺陷控制(要求空隙率低于0.1%)。产业界正通过双重曝光TSV工艺和原子层沉积(ALD)界面钝化技术攻坚。随着EUV光刻和GAA晶体管技术的协同发展,多片式3D集成有望在2030年前实现万亿晶体管级系统集成,为AI大模型训练、6G通信等前沿领域提供硬件基石。
-
2.5D集成电路的Chiplet布局设计2025-02-12 2711
-
新型2.5D和3D封装技术的挑战2020-06-16 8799
-
异构集成基础:基于工业的2.5D/3D寻径和协同设计方法2021-07-05 1196
-
2.5D/3D芯片-封装-系统协同仿真技术研究2022-05-06 1448
-
分享一下小芯片集成的2.5D/3D IC封装技术2022-08-24 5890
-
3D封装与2.5D封装比较2023-04-03 5774
-
3D封装结构与2.5D封装有何不同?3D IC封装主流产品介绍2023-08-01 5576
-
2.5D和3D封装的差异和应用2024-01-07 5343
-
探秘2.5D与3D封装技术:未来电子系统的新篇章!2024-02-01 5711
-
2.5D/3D封装技术升级,拉高AI芯片性能天花板2024-07-11 9894
-
深视智能3D相机2.5D模式高度差测量SOP流程2024-07-27 2456
-
一文理解2.5D和3D封装技术2024-11-11 6358
-
技术资讯 | 2.5D 与 3D 封装2024-12-07 3316
-
2.5D和3D封装技术介绍2025-01-14 3686
-
多芯粒2.5D/3D集成技术研究现状2025-06-16 2172
全部0条评论

快来发表一下你的评论吧 !
