

简单认识3D SOI集成电路技术
描述
文章来源:学习那些事
原文作者:小陈婆婆
在此输入导语本文主要讲述3D SOI集成电路概述。
在半导体技术迈向“后摩尔时代”的进程中,3D集成电路(3D IC)凭借垂直堆叠架构突破平面缩放限制,成为提升性能与功能密度的核心路径。
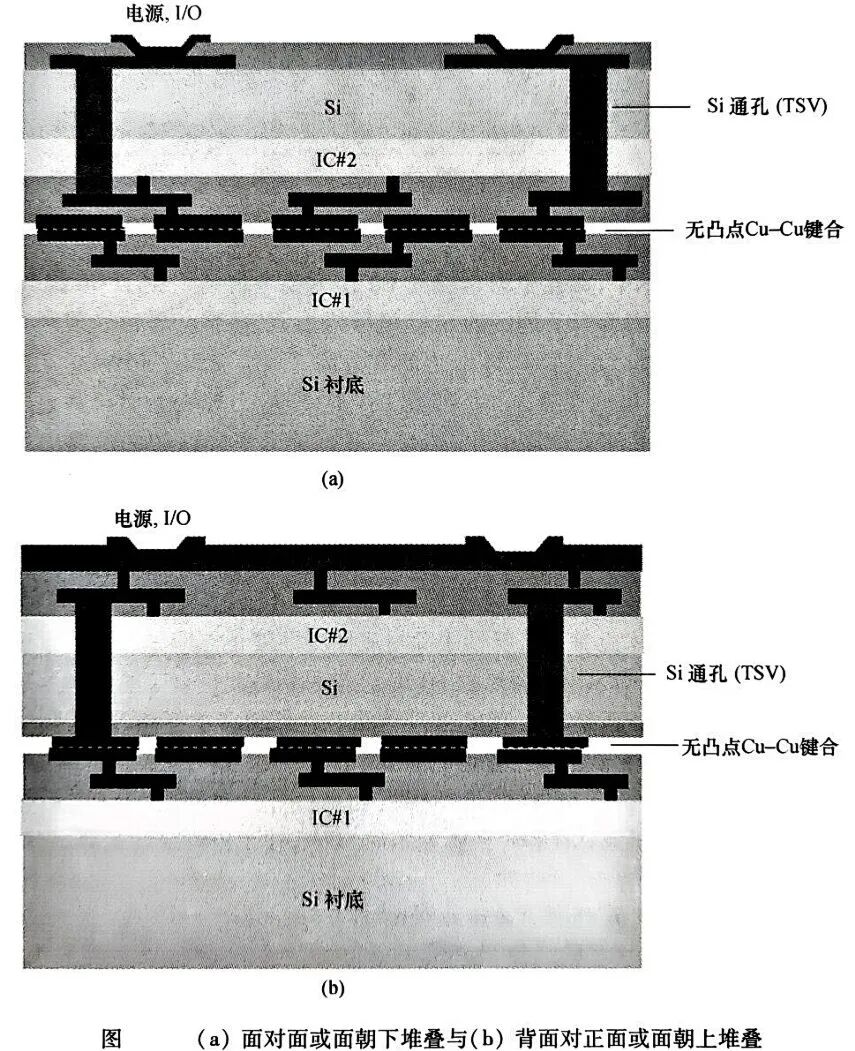
其中,绝缘体上硅(SOI)平台因独特材料特性与工艺优势,在3D集成领域展现出不可替代的价值。SOI晶圆通过埋氧化层实现超薄硅层(厚度可降至亚微米级)的精准转移与堆叠,规避了体硅技术中高深宽比硅通孔(TSV)的工艺瓶颈——传统体硅需依赖深宽比10:1~20:1的TSV实现垂直互连,而SOI平台可采用深宽比低于5:1的TSV甚至后端工艺兼容的通孔技术,结合低温键合工艺(如直接Cu-Cu键合或绝缘层键合),在降低工艺复杂度与成本的同时,显著提升互连密度与信号传输速度。
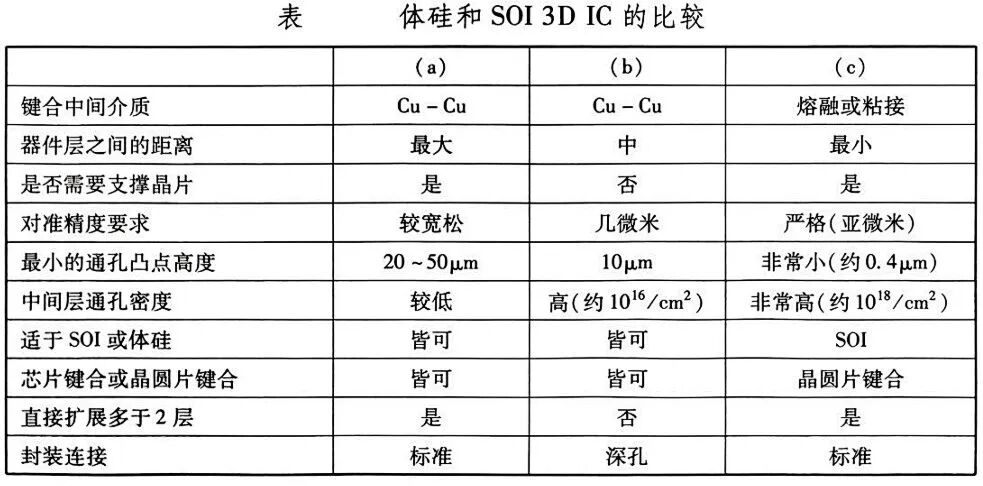
当前SOI基3D IC的技术突破聚焦于材料-工艺-设计的全链条协同创新。在材料层面,外延层转移技术(如ELTRAN)通过多孔硅控制晶圆分裂,实现硅层厚度均匀性优于1%,注氧隔离技术(SIMOX)结合高温退火优化散热与抗辐射性能,键合注入结合技术(Smart-Cut)则通过离子注入与层转移实现亚微米级超薄硅层的精准制备。
工艺层面,TSV技术正从后道封装向前道制造延伸,与FinFET晶体管工艺协同优化——例如采用化学镀镍合金填充工艺将TSV工序缩减至6道,良率提升至98%以上,深反应离子刻蚀(DRIE)实现30-100μm孔径的高精度加工,配合PECVD沉积0.5-2μm二氧化硅绝缘层与200-500nm阻挡层/种子层,构建高可靠性垂直互连结构。
设计层面,EDA工具链(如新思科技3DIC编译器)通过跨工艺互联规划、寄生参数评估与热应力预测,实现从架构探索到签核的全流程协同,例如AMD Zen 4处理器采用3D V-Cache技术,通过TSV与微凸点将64MB SRAM缓存堆叠于CPU核心上方,垂直互连距离缩短至传统2D设计的1/10,缓存延迟降低85%至10ns,带宽提升至1.2TB/s,面积效率提升70%;NVIDIA H100 GPU则集成8层HBM3内存,通过TSV实现3.3TB/s内存带宽,功耗降低30%,支撑AI训练对超高内存带宽的需求。
应用场景方面,SOI基3D IC在高性能计算、AI、存储与传感器领域持续拓展边界。在高性能计算领域,苹果M1 Ultra通过UltraFusion封装技术连接两个M1 Max芯片,实现2.5TB/s芯片间带宽,GPU核心扩展至64核,AI算力达192 TOPS,能效比提升3倍;Xilinx UltraScale+ FPGA集成3D堆叠的逻辑切片与高速收发器,TSV密度达10⁴个/cm²,内部带宽提升至1.6TB/s,延迟降低40%,适用于5G基站与AI推理场景。存储领域,三星HBM4采用12层堆叠与4纳米逻辑芯片,结合TSV技术实现单节点3PB内存容量,带宽达281GB/s;晶方科技则通过8英寸与12英寸TSV封装能力,构建国内首条300毫米“中道”TSV规模化量产线,支撑HBM与6G通信封装需求。传感器领域,背照式CMOS图像传感器通过TSV分离模拟电路与光电二极管,量子效率提升至85%以上,暗电流降低至0.5nA/cm²,索尼IMX989传感器已实现1英寸光学格式。
面向未来,SOI基3D IC的技术演进将围绕异构集成、智能化与国产化三大方向深化。异构集成通过Chiplet架构整合不同工艺节点的逻辑、存储与RF模块,平衡成本与性能,例如AMD通过台积电CoWoS-S封装技术实现TSV密度10⁶个/cm²,支持AI芯片的高带宽需求。智能化则通过AI辅助设计优化仿真验证效率,例如华大九天通过关键路径分析与快速建模工具推动设计与制造迭代,国产EDA工具正与国际标准接轨并依托AI实现创新突破。国产化方面,中国企业在SOI材料、晶圆键合设备与TSV技术领域持续突破——沪硅产业实现大尺寸硅片产业化,超硅半导体推进薄层SOI研发;中微公司、北方华创在晶圆键合设备领域取得显著进展,应用材料、科磊等国际巨头则通过技术合作与本土企业协同创新。
总体而言,SOI基3D IC通过超薄硅层、低深宽比TSV与低温键合技术的协同,在性能、功耗与成本方面形成综合优势,正从实验室走向规模化应用。SOI平台在高性能计算、存储扩展与异构集成领域持续释放技术潜力,成为半导体产业突破物理极限、实现自主可控的关键支撑。
-
3D集成电路的结构和优势2024-12-03 3606
-
简单认识射频集成电路产品2023-12-28 2051
-
简单认识模拟集成电路2023-12-08 3297
-
一文详解3D集成电路的热问题2022-05-13 2849
-
硅3D集成技术全面解析2020-04-10 3696
-
集成电路测试技术简单介绍2016-09-01 744
-
SOI和单片3D集成技术 芯片成本战的杀手锏2014-10-09 2243
-
教你认识如何看懂集成电路的线路图2012-06-26 10096
-
激光直接成型实现低成本3D集成电路2011-12-15 3242
-
单片型3D芯片集成技术与TSV的研究2011-05-04 2309
-
从知识平台角度认识集成电路2010-07-16 502
-
SOI和体硅集成电路工艺平台互补问题的探讨2009-12-14 763
-
从知识平台认识集成电路2009-11-19 926
-
从知识平台角度认识集成电路--知识平台上SOC的高速发展2009-10-15 2687
全部0条评论

快来发表一下你的评论吧 !
