
资料下载


如何进行网络流量分类详细资料和算法的研究
分享资料个
随着网络技术的快速发展,基于网络的应用越来越多、越来越复杂。种类繁多的应用(合法的或者非法的)不但吞噬着越来越多的网络资源,而且也对QoS和网络安全带来了巨大的威胁。由于在负载均衡、资源利用等方面的优势,流量工程(Traffic Engineering)得到了业界广泛的关注。在流量工程中,流量识别是网络管理、流量监控、服务分析、安全和错误监测、网络计费等多方面的重要基础。
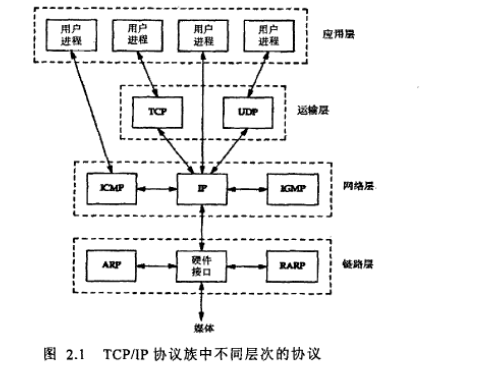
已有的流量识别方式,例如基于端口识别,基于特征码识别,BLINC识别存在一些缺点。近年来,以流量统计特征为基础的机器学习识别方法得到了广泛的关注。基于机器识别流量类型的原理是:根据IP包的长度、时间间隔等流量特征进行流量类型识别,无须检测IP包的载荷内容。在实践中,基于机器学习的流量类型识别又有“有监督型”和“无监督型”两种。例如贝叶斯,EM算法属于有监督型,而k-means算法则属于无监督型,它们的区别在于有无导师信号的指导。在当前的实践中,基于机器学习的流量识别方法表现出了较高的准确率。
有监督型算法往往由于依赖已知的人工分析,对于新的网络流量反应迟钝。这样一个很具挑战性的课题就是不仅保证对已知流量的准确检测,而且能检测出未知流量。本文将无监督型的自组织映射网络算法(Self-organizing Mapping,SOM)引入流量分类,该算法在学习过程中不需要人工分析做向导,自动对数据进行分类。
在属性的选取上,引入流量时间间隔变化率这- -概念,尽可能消除了网络状况对于流量时间间隔的影响,并实现了一个基于该算法的流量识别系统模型,初步达到了识别新流量的目的。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




