搜索内容
登录
爬虫
0人关注
在互联网领域,爬虫一般指抓取众多公开网站网页上数据的相关技术。目前,爬行是获取数据的主要方式。正如爬虫工作者所知,爬虫时IP很容易被封堵,这是因为有了反爬虫机制,所以才使用代理IP。
...展开
76
文章
1201
视频
36
帖子
7998
阅读
关注标签,获取最新内容
全部
技术
资讯
资料
帖子
视频
爬虫的学习方法
2023-02-23
1665阅读
Python技术之爬虫的基本流程和原理
2022-12-14
2408阅读
网页爬虫及其用到的算法和数据结构
2022-12-02
1371阅读
FOFA联动XRAY小工具:XRAY-F
2022-10-26
1338阅读
用炫酷大屏展示爬虫数据!
2022-08-05
1708阅读
反爬虫组件kk-anti-reptile的工作流程与使用方法
2022-07-14
2347阅读
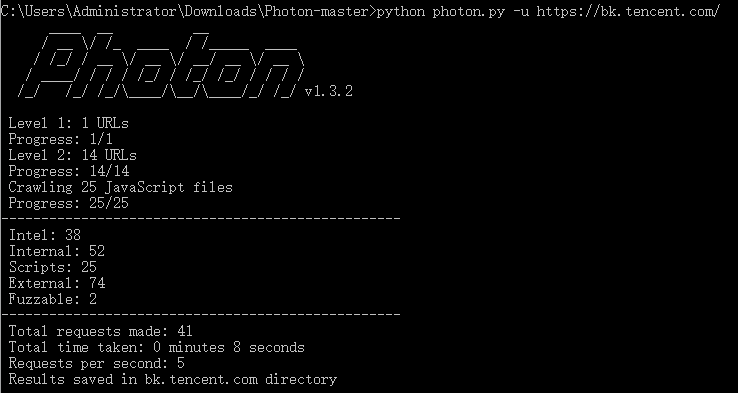
Photon情报搜集爬虫的主要功能与安装使用说明
2022-06-23
1635阅读
RuiJi Scraper可视化浏览器爬虫扩展
2022-05-19
474阅读
通过分析ajax中信息爬取图片
2022-03-23
1808阅读
豆瓣电影Top250信息爬取
2022-03-23
3261阅读
python网络爬虫概述
2022-03-21
2490阅读
如何安装第三方模块爬取4K壁纸
2021-12-27
1978阅读
详解常见的反爬虫的两种机制
2021-07-29
5822阅读
崔丽就中兴通讯对新形势下广电未来发展的洞察和理解的发言
2021-05-31
2735阅读
采用多目标蚁群优化算法的主题爬虫方法
2021-03-23
1025阅读
大数据爬虫采集应用流程的注意事项
2021-01-15
3922阅读
Python爬虫之Beautiful Soup模块
2020-12-10
705阅读
Python爬虫之requests模块教程
2020-12-10
697阅读
GitHub上开源了个集众多数据源于一身的爬虫工具箱——InfoSpider
2020-11-23
2559阅读
常见的反爬措施和应对方案
2020-11-23
3585阅读
上一页
2
/
5
下一页
相关推荐
更多 >
IOT
海思
STM32F103C8T6
数字隔离
硬件工程师
wifi模块
MPU6050
Protues
STC12C5A60S2
UHD
74ls74
×
20
完善资料,
赚取积分




 下载APP
下载APP
 搜索内容
搜索内容