
资料下载


基于深树的软件缺陷预测模型的详细资料说明
HIHSS
分享资料个
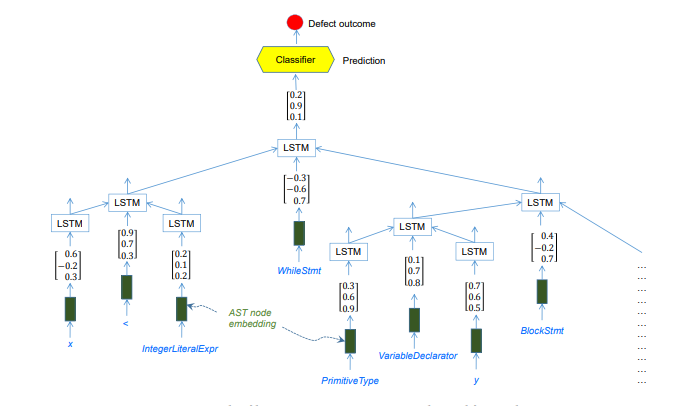
缺陷在软件系统中很常见,可能会给软件用户带来各种各样的问题。为了快速预测大型代码库中最可能出现的缺陷位置,开发了不同的方法。它们中的大多数都专注于设计与潜在缺陷代码相关的特性(例如复杂性度量)。然而,这些方法并不能充分捕获源代码的语法和不同级别的语义,这是构建准确预测模型的重要能力。本文提出了一种新的预测模型,能够自动学习表示源代码的特征,并将其用于缺陷预测。我们的预测系统建立在强大的深度学习、树形结构的长期短期记忆网络之上,与源代码的抽象语法树表示直接匹配。对两个数据集(一个来自三星贡献的开源项目,另一个来自公共承诺库)的评估表明了我们的方法对于项目内和跨项目预测的有效性。
随着软件系统在我们社会的各个领域继续发挥着关键作用,这些软件产生的缺陷对企业和人们的生活产生了重大影响。然而,由于软件代码库在规模和复杂性上的显著增长,识别软件代码中的缺陷变得越来越困难。缺陷预测的重要性和挑战使其成为软件工程中一个活跃的研究领域。大量的研究已经开始开发预测模型和工具,帮助软件工程师和测试人员快速缩小软件代码库中最有可能存在缺陷的部分。早期的缺陷预测有助于优先考虑和优化检查和测试的工作和成本,特别是在面临COS时。T和截止压力。
机器学习技术已广泛应用于建立缺陷预测模型。这些技术从软件代码中派生出许多特性(即预测器),并将它们提供给常见的分类器,如Naive Bayes、支持向量机和随机森林。大量的研究(例如)已经仔细地设计了能够区分有缺陷代码和无缺陷代码的功能,例如代码大小、代码复杂性(例如Halstead功能、McAbe、CK功能、情绪功能)、代码转换度量(例如更改的代码行数)、过程度量。然而,这些特性并不能真正反映代码的语法和语义。此外,软件度量特性通常不能很好地概括:在某个软件项目中工作良好的特性在其他项目中可能表现不好。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





