


深度学习模型的嵌入式部署一直以来都不是那么得容易,虽然现在有Nvidia Nano和TFLite的树莓派部署,但要么硬件成本太高、功耗太大、要么性能太差,难以实用化和产品化。一方面,AI科学家和工程师没有太多的嵌入式知识,另一方面,嵌入式工程师没有太多AI的知识,因此很需要开源硬件社区来解决这些问题。
本文介绍AIoT目前的情况以及面临的挑战,并讲解Maix-EMC的开发缘由,功能和实现。我们也希望有一定基础的小伙伴可以加入开源社区一起完善Maix-EMC,让大家可以转换更多结构的模型到低成本AIoT硬件上。(参与项目贡献的小伙伴可获赠Maix套装一份!)
眼瞅着AI红红火火,无数的嵌入式工程师也眼红着。与此同时,一大批AI科学家开发出来的模型,也面临落地问题。基于安卓或者Linux的开发者还好,谷歌大佬给了TFLite的支持,但是没有AI加速器的普通ARM平台板子成本动辄已经几百元了,而跑起模型来却只有几帧。。玩单片机的嵌入式工程师手头的主控芯片往往算力最高仅数百MOPS,内存数百KB,也没有TFLite解释器,一切都是那么绝望。
OpenMV模组
另一方面,AI科学家和工程师们也有着自己的硬件梦,估计很多人早就用树莓派玩起了TFLite,或者更深入地玩起了Tengine, NCNN等加速引擎。但是没有AI加速器的加持,再怎么优化,帧数还是个位数,价格亲民的树莓派3+摄像头 成本也要接近300元了!
树莓派开发板
作为嵌入式设备主控芯片的老大哥---ARM,早早地出了在自家Cortex-M系列芯片上运行的NN后端支持库:CMSIS-NN。然而其充其量相当于TF的ops的底层实现,需要用户小心翼翼地管理内存,设置量化参数。这都2019年了,谁还想要像5000年前那样手工撸神经网络呢?
2019年,谷歌也推出了TFLite for Micro,与ARM相反,谷歌是从复杂的TFLite往下精简。粗粗翻阅TFLite for Micro的代码,目前还在比较初级的阶段,支持的ops比较少,内存管理貌似不够精简(使用了大量的allocator),为了支持一些动态特性有些许效率的牺牲。当然其优点还是支持从谷歌的TFLite转换。
目前,这两者都还处于实验阶段,还没有跑起来MobileNet等大家耳熟能详的轻量级网络,能跑的只是MNIST或者Cifar10等级的教学意义上的小网络,没有任何的意义,并且它们对要求使用者具有丰富的神经网络经验,包括但不限于:量化,剪枝,蒸馏,压缩。这些都大大限制了它的实用性。
不过,高手在民间,2019年春节,在UP主的QQ群里就活捉了一只来自拉夫堡大学的生猛老博,他的嵌入式神经网络框架NNoM就实现了不错的可用性,让用户可以忽略模型在嵌入式端的实现细节,通过其解释器自动执行完毕。在这个框架下,基本只受限于主控本身内存,算力,以及作者本身的填坑速度了。
新的转机
在2018年末,嘉楠耘智出了一款价格亲民的高素质纯国产AI芯片----K210。其低廉的价格(3美金以下),新颖的核心(RISC-V 64GC),强大的算力(~1TOPS),较低的功耗(0.3~0.5W),以及稳定的货源。吸引了Sipeed和TensorLayer开源社区的注意。围绕着这款芯片,Sipeed开源了一系列的硬件模块设计,制作了多款嵌入式板卡:MAIX Go/Bit/Dock/Duino…
Sipeed基于K210开发的相关模组
为了方便大家快速上手,Sipeed开发了易用的MaixPy (MicroPython)环境, 并兼容了多数OpenMV接口:
虽然Maix板卡已经具备了运行MobileNet等典型网络的能力,具备了实用性;然而,一直有个问题困扰着Sipeed和TensorLayer社区的小伙伴们:芯片原厂提供的模型转换器nncase不好用啊。原厂的模型转换器主要有以下问题:
-
对于AI开发者不友好
用户需要经过:h5 -> pb -> tflite -> kmodel 多道工序才能完成转换。 -
出错提示过于简略
nncase的出错提示让人摸不着头脑,仅会报某层类型不支持,连层号都没有。又因为层的转换涉及到前后文顺序,单靠一个出错时的层号,很难排查。 -
C#工程过于模块化
虽然转换器本身不是很大的工作量,但是nncase的C#工程过于细分,有三四级目录,又没有相应文档说明,很多爱好者即使有心想改进nncase,却也耐不住性子去翻阅这样繁杂的工程。
那么好的芯片,没有好用的工具怎么行,既然原厂的工具不好用,那么开源社区组团上吧–>
撸一个模型转换器吧
Maix-EMC的初衷就是做一个好用的、好维护的、社区型、跨平台模型转换器,设计目标如下:
- 使用Python编写,简洁清晰,适当模块化,让有一定基础的AI工程师能参与完善;
- 基于层结构的模型解析,对于以层为基础的深度学习框架有一定移植性(如,TensorLayer, Keras);
- 使用扁平化,无需复杂解析的模型文件,即时载入内存,即时执行;
- 嵌入式端解析器使用层类型进行解析,后端运算库具备可插拔性(比如使用CMSIS-NN作为后端);
这个构想埋在心里很久,一直苦于业务繁忙没有时间去实现,最近总算是抽空断断续续地开始挖了这个坑。。如果你只想使用Maxi-EMC,而不关心它的细节,请看这篇文章:
低成本AIoT硬件深度学习部署实战zhuanlan.zhihu.com
Maxi-EMC的基础架构
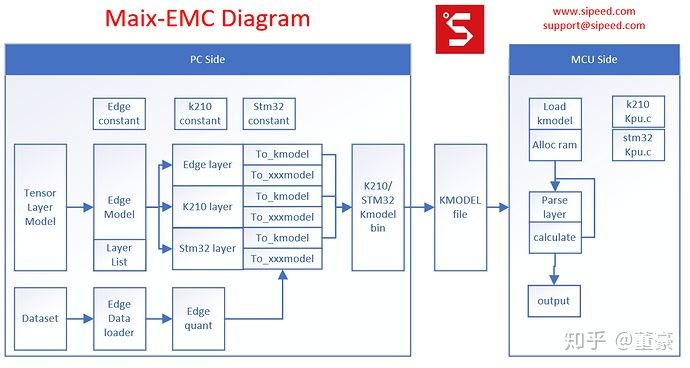
左侧: EMC即这个工作的左侧,将PC端的模型文件转换成二进制扁平化的模型文件。PC端的模型文件我们选用了TensorLayer,因为TensorLayer的层定义高度比较合适,基本等同于kmodel定义的层的高度,两者转换基本只是作了 量化,某些层的合并优化, 极大地加快了开发进度。反观TensorFlow的pb文件里算子,低到了Add, mul的程度, 需要手工整合这些低层次算子到层定义,非常不便。
中间:这个工作的中间是kmodel文件,类似于字节码或者说IR。这里模型文件没有采用通用的protobuf(pb)或者flatbuffer(tflite), 因为对于嵌入式平台来说,它们的解析以及内存消耗都太大。为了快速实现demo,并考虑嵌入式的效率,这里我们借用了k210 sdk中的kmodel v3格式。这个格式本是为K210设计,但是同样适用于普通嵌入式平台,只需新增通用层类型的定义。
右侧:这个工作的右侧是嵌入式硬件平台上的kmodel解释器(interpreter)。对于k210, 我们只需借用SDK本身的kpu.c, 稍作修改即可。对于普通单片机,我们只需将kpu.c中的卷积层计算函数替换成普通的cpu计算函数。这里的计算后端可以借用CMSIS-NN或者NNoM的计算后端,往上套上kmodel层参数的调用wrapper即可。
下面我们从左到右介绍整个流程的实现。
TensorLayer模型转换为kmodel
层结构的转换
由于TensorLayer使用基于层的模型结构描述,整个转换过程比较简单。入口文件是edge_model.py,其中gen_edge_layers_from_network将TensorLayer层转换为EMC的层中间表示形式。这里首先通过platform_table查表选择当前硬件平台使用的TensorLayer层转EMC层的函数表,以及打包模型的函数。
platform_table = {
# platform tl layer convertor model generator
'k210' : [tl_to_k210_table, gen_kmodel]
#'stm32' : gen_stm32_layer_func_table,
}
在tl_to_k210_table中,gen_edge_layer_from_network查找到对应的TensorLayer层类型的表项,并往后匹配到最长的列表,将该列表交给layer_generator 来生成 EMC中间层的list (可能会在前后加了上传/下载/量化/去量化的dummy层)
tl_to_k210_table= {
# TL layer class layer_generator merge
'Dense' :[gen_fc_layer, [[],]] ,
'Flatten' :[gen_flatten_layer, [[],]] ,
'Reshape' :[None, [[],]] ,
'GlobalMaxPool2d' :[gen_gmaxpool2d_layer, [[],]] ,
'GlobalMeanPool2d' :[gen_gavgpool2d_layer, [[],]] ,
'MaxPool2d' :[gen_maxpool2d_layer, [[],]] ,
'MeanPool2d' :[gen_avgpool2d_layer, [[],]] ,
'Concat' :[gen_concat_layer, [[],]] ,
'Conv2d' :[gen_k210_conv_layer, [[], ['BatchNorm'],]] ,
'DepthwiseConv2d' :[gen_k210_conv_layer, [[], ['BatchNorm'],]] ,
'ZeroPad2d' :[gen_k210_conv_layer, [['Conv2d'], \
['Conv2d', 'BatchNorm'], \
['DepthwiseConv2d'], \
['DepthwiseConv2d', 'BatchNorm']]] ,
'DummyDequant' :[gen_dequant_layer, [[],]] ,
'SoftMax' :[gen_softmax_layer, [[],]] ,
}
量化操作
由于TensorLayer目前没有很好的量化API,所以在EMC的层转换中附带实现了参数量化。
edge_quant.py中可选minmax或者kld量化。实测对于小模型,minmax还是最简单直接,快速有效的方式。KLD方式可能略有提升,但有时却会负优化。。为了进一步提升精度,我们还使用了Channel Wise的量化方式来降低精度损失。对每一个Channel使用不同的量化参数,直到最后再合并,经测试在大通道的模型中会有一定的优化效果。
后处理及打包
至此我们初步将TensorLayer层转换成了一系列层列表,我们再使用optimize_layers来优化层列表,去除一些抵消的层(如相邻的量化/去量化层),进行一些可选的后处理(比如k210的stride修复步骤)。
然后我们使用gen_kmodel将层列表转换成kmodel层列表中的每个层都有to_kmodel方法,调用该方法即可获得当前层符合kmodel格式的layer body的bytearray结果。gen_kmodel再把所有层的body堆叠在一起,统计好最大的动态内存需求,加好头部,即得到了kmodel。
EMC 层支持的添加
这里简单介绍下如何添加新的层支持。首先在edge_model.py的tl_to_k210_table里加上你需要添加的TensorLayer层与EMC层的转换表项。然后在对应的xxx_layer.py中加上对应的实现。K210相关的加速层在k210_layer.py中实现(目前已经基本实现,但是需要修复一些bug),CPU计算的非加速层,在edge_layer中实现。只需模仿其中的层的实现,对每个层类型,完成以下一个函数和一个类:
- gen_xxx_layer: 输入TL layer list, 转换成EMC layer list;
- class xxx_Layer: 需要实现init方法(填充层信息),以及to_kmodel方法(按kmodel格式填充信息,返回打包的bytearray)
事实上,你可以实现自定义的to_xxxmodel方法,在此框架上实现你自己的模型格式。
kmodel简介
kmodel是一个自定义的,扁平化的模型存储格式,模型格式的封装已经在EMC代码里完成,这里简要介绍一下:在EMC中,我们调用了dissect.cstruct, 这是pyhton解析c结构体的库, 很方便我们使用k210的kpu.c中关于kmodel的结构体定义。在EMC中,这部分定义放在k210_constant.py中:
"
typedef struct
{
uint32 version;
uint32 flags;
uint32 arch;
uint32 layers_length;
uint32 max_start_address;
uint32 main_mem_usage;
uint32 output_count;
} kpu_model_header_t;
typedef struct
{
uint32 address;
uint32 size;
} kpu_model_output_t;
typedef struct
{
uint32 type;
uint32 body_size;
} kpu_model_layer_header_t;
...
kmodel 头部是kpu_model_header_t, 描述了 版本,量化位数,层数,最大内存占用大小(驱动中一次性申请该模型需要的动态内存),输出节点数量。在头部之后,排列着若干个kpu_model_output_t,描述输出节点的信息。在输出节点信息之后,排列着所有层的头部信息:kpu_model_layer_header_t,依次描述层的类型,层body的大小。在层头部信息之后,就按层信息依次排列层body数据,其中某些部分会要求一定的字节对齐。
层类型定义在edge_constant.py中,在原始的kpu.h的定义上稍作修改,区分了k210专用层和普通层(这里是为了快速移植K210驱动才使用了K210专用层,理论上仅定义一套通用层标准比较好)
K210的kmodel解释器的实现
可以参见kpu.c, 驱动会按顺序读取kmodel每一层的层信息,根据层类型执行对应函数。
需要注意的是上传/下载操作。K210内存分为6M CPU内存 和 2M KPU内存。使用KPU计算的层,需要将待计算的数据上传到KPU内存。在KPU中,可以连续计算很多层CONV相关计算,而无需将结果下载到CPU内存。但是一旦下一层是需要CPU运算的层,则需要进行一次下载才能继续运行。所以,我们需要留意TensorLayer层的顺序,在需要切换KPU/CPU运行的层前后,插入上传,下载的dummy 层。在EMC中,我们使用meta_info[‘is_inai’]字段确认当前的待计算内容是否在AI内存。
另外,KPU计算,使用的2M内存,是以乒乓形式使用,即输入数据在开端,则输出结果在末端进入下一层后,上一层的输出结果作为了输入结果,在末端,计算结果放到了开端。
如此往复计算,EMC中meta_info[‘conv_idx’]记录了当前的卷积层序号,进而可以确认当前的输出结果所在KPU内存的偏移。
其它注意点,需要下载kpu.c查看:https://github.com/kendryte/kendryte-standalone-sdk/blob/develop/lib/drivers/kpu.c
测试
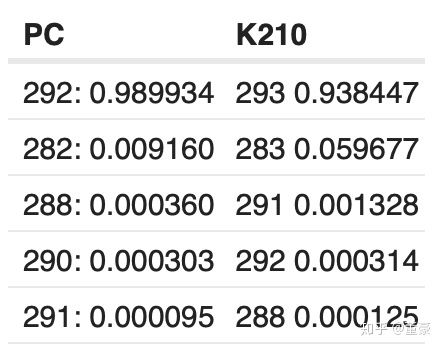
我们使用Maix-EMC测试转换了mbnet的每一层,与PC原始结果对比:
同一张图片,alpha=1.0, top5的预测概率:
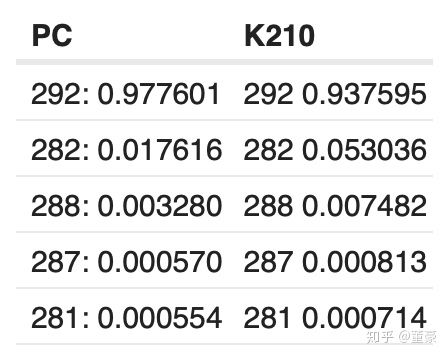
同一张图片,alpha=0.75, top5的预测概率:
同一张图片,alpha=0.5, top5的预测概率:
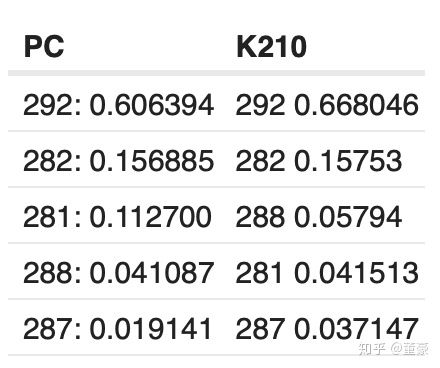
可以看到相对PC端的结果,K210的计算结果退化了3~6%,是否是转换器原因造成的呢?
我们对比下谷歌的TFLite的量化工具的测试数据:
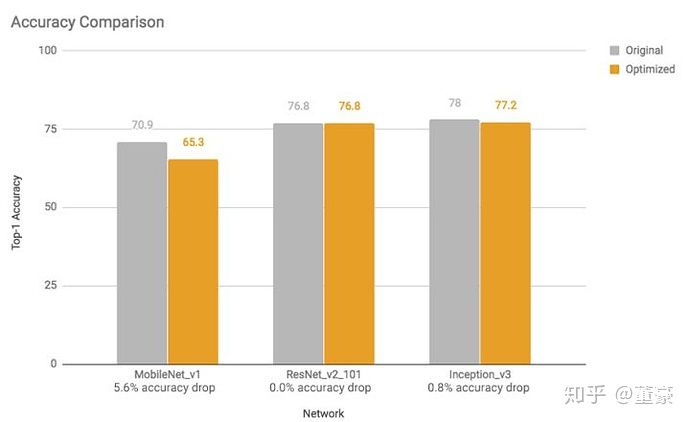
发现对于MobileNet来说,TFLite的量化也造成了5.6%的损失,所以这是正常的损失。(当然这里的tflite的精度是指的是数据集总体的精度损失,我前面仅测了一张图片的概率损失,有差别)。虽然我们有很多方式改善训练后量化损失,但是基本都会膨胀模型体积,所以在这里不再赘述。
小结
目前Maix-EMC完成了初步简单结构的模型转换功能,可以基于TensorLayer框架快速部署到K210普通上,对于复杂模型仍然需要社区小伙伴一起完善。



