
资料下载


机器学习让糖果分拣变得简单
陈文博
分享资料个
描述
灵感
最近,我一直在尝试使用 Edge Impulse 在图像数据集上训练 TensorFlow 模型。因此,在考虑万圣节时,几乎每个人都会遇到一个常见问题。为什么整理和整理所有糖果需要这么长时间?因为单独拾起每一块并将其放入各自的堆中会耗费太多精力,所以我想利用机器学习的力量来自动化这个过程。
工作原理
该理论如下:用户首先将一块糖果放在平台上,然后由相机对其进行扫描。该图像被一个模型分类,该模型产生一个它认为糖果是什么的标签。根据结果,选择一堆,然后平台移动到该位置。一旦它到达,某种推动机构将糖果推入堆中,然后平台返回并重新设置循环。
设置边缘脉冲
为了收集训练数据并生成 TensorFlow 模型,我选择了 Edge Impulse。我首先创建了一个名为“candySorter”的新项目,然后前往设备页面。Edge Impulse 有一个不错的功能,您可以导入多种类型的数据并仅根据文件名自动推断其标签,因此我编写了一个简单的 Python 脚本,该脚本使用 Pi 的相机拍照并在按下按钮时将其保存为所需的标签被按下。
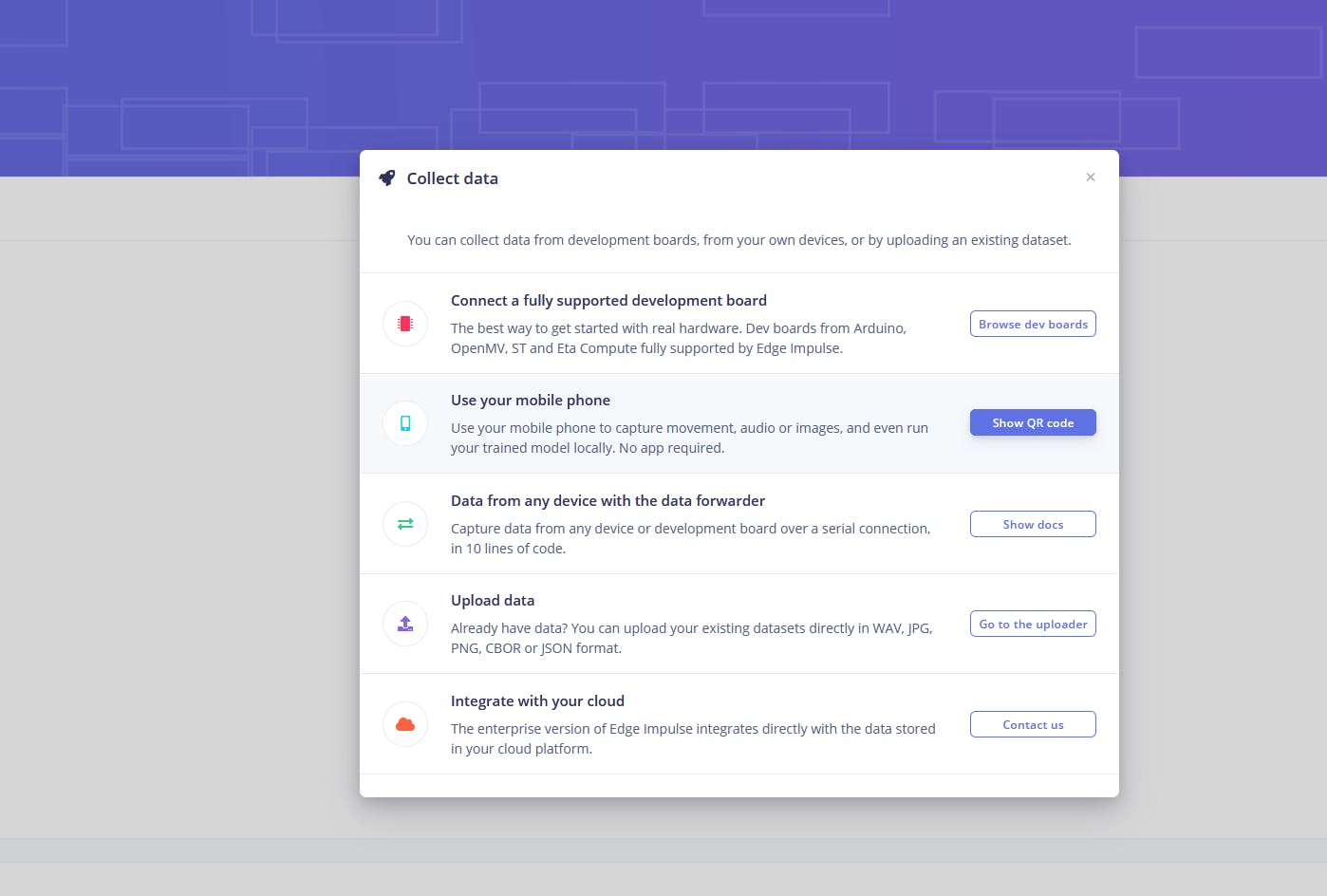
训练和部署模型
现在有大量的图像数据,是时候在其上训练一个 TensorFlow 模型了。对于输入,我使用了一个将原始图像缩放为 96x96 像素大的图像块。处理块只是将颜色深度设置为 RGB 而不是单色,训练块利用 MobileNetV2 模型的迁移学习。输出是以下标签之一:kitkat、sour patch、twizzler或reeses。
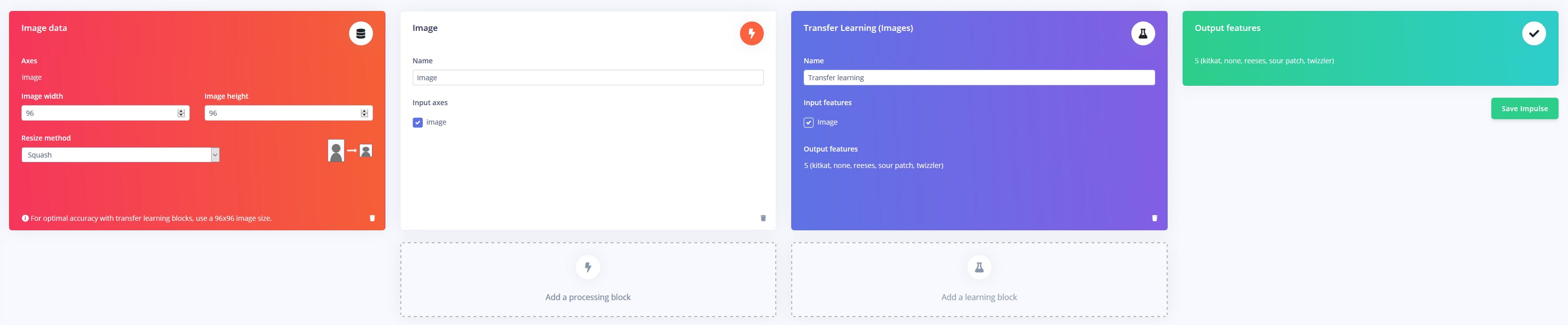
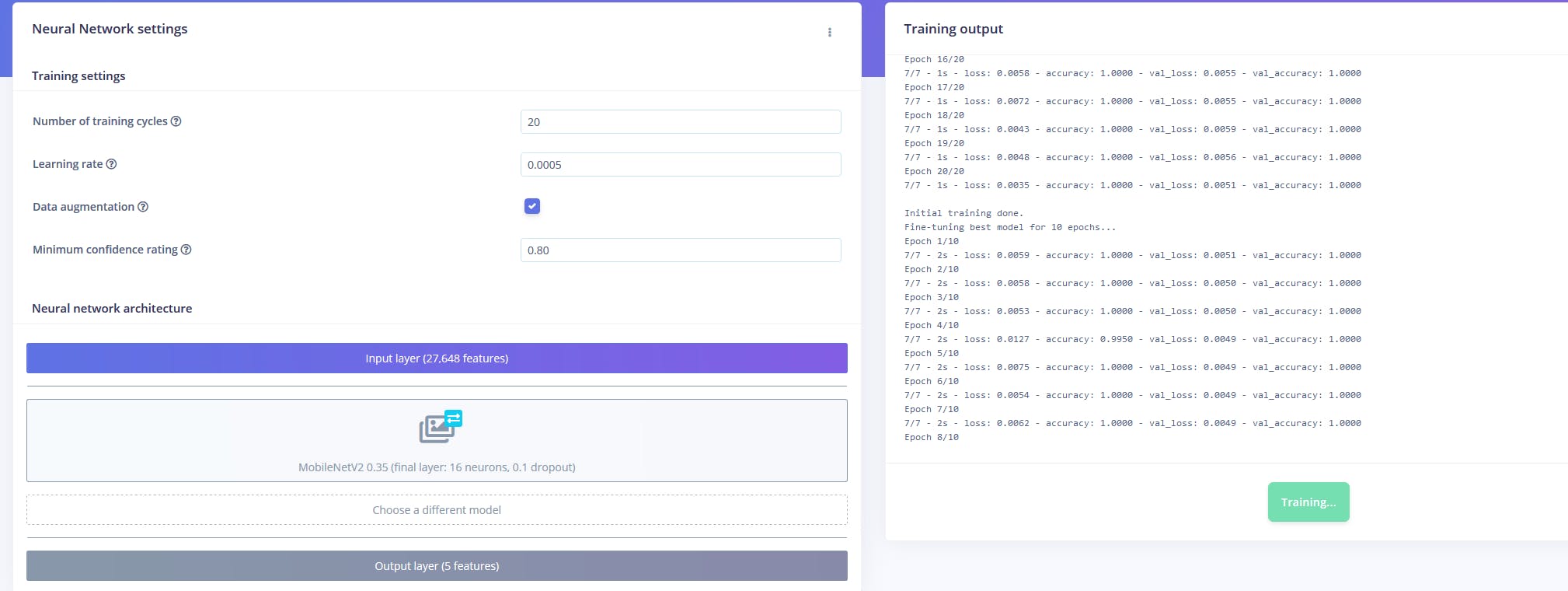
训练完成后,我将模型部署为独立的 Web 程序集库,可以从 Node.js 源文件外部调用。
处理图像
该系统使用 Raspberry Pi 4 使用 Raspberry Pi 相机模块捕获图像,但分类器无法理解该格式,它需要一个特定大小的像素值数组。因此,捕获被保存到BytesIO流中并调整为 96x96 像素大。然后将其转换为一串扁平像素值,该字符串接受一个 RGB 值元组并将其转换为单个十六进制值并将其附加到列表中。

分类对象
该subprocess.run()函数调用 Node.js 源文件,并将颜色数据字符串作为参数传递给程序,然后在程序中对其进行解析并提供给模型。在模型提出它认为的对象后,会通过标准输出输出 JSON 字符串,然后将其通过管道传输到 Python 变量并解析为字典对象。最后,找到最大值并提取相关标签并用于确定应将糖果放入哪个箱中。然后通过 USB 将此 bin 编号发送到等待的 Arduino Mega 2560。
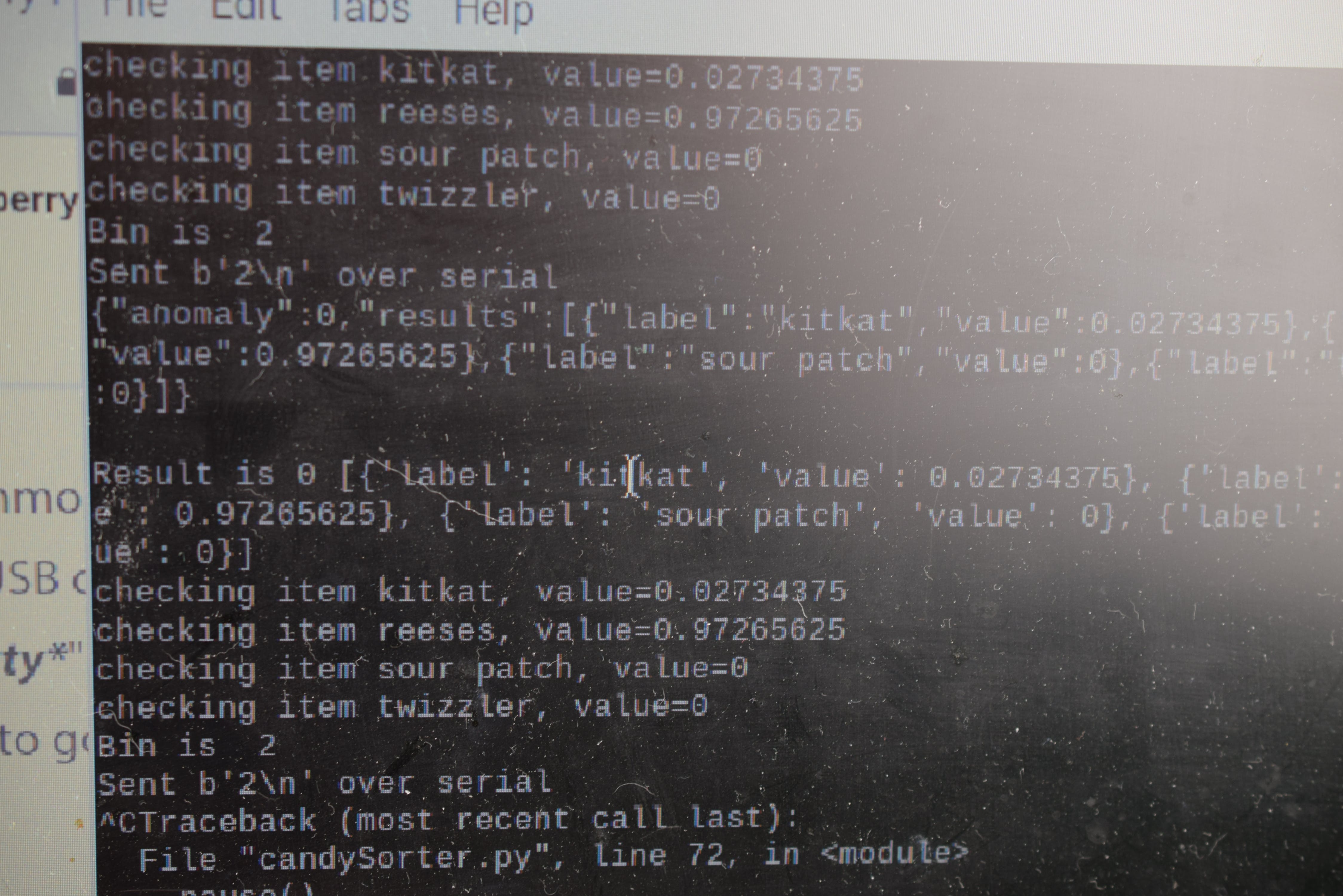
硬件
首先是 x 轴滚轮,它由单个 NEMA17 步进电机移动到位,该步进电机由 DRV8825 步进电机驱动器模块驱动。

当 Arduino Mega 2560 启动时,它会通过缓慢滑动滚轮来使轴归位,直到它碰到限位开关,此时它为 0。当有新的串行数据时,它被读取并解析为一个整数,表示 bin糖果应放入。箱子间隔 10 厘米,所以这个数字乘以 100 毫米,步进器移动相应的步数。到达目的地后,顶部的螺线管会启动并快速推动下方的糖果。

将糖果分拣成堆
将 ML 模型加载到 Pi 上后,我将所有东西都插入。实际的排序机制自动运转起来,并且 Pi 开始显示它所看到的预览。从那里,我简单地把一块糖果放在平台上,然后按下按钮给它拍照。该图像被调整大小并发送到模型,模型决定了它的标签。最后,将箱号发送过来,并将糖果存放到正确的位置。将来,我想通过添加一个漏斗来进一步自动化这一过程,该漏斗可以将糖果倒在顶部,然后随着时间的推移单独存放每一块。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




