


在本节中,我们将向您展示如何在原始 Linux 机器上安装所有库。回想一下,在第 23.2 节中,我们讨论了如何使用 Amazon SageMaker,同时自己构建实例在 AWS 上的成本更低。演练包括三个步骤:
-
从 AWS EC2 请求 GPU Linux 实例。
-
安装 CUDA(或使用预装 CUDA 的 Amazon Machine Image)。
-
安装深度学习框架和其他用于运行本书代码的库。
这个过程也适用于其他实例(和其他云),尽管有一些小的修改。在继续之前,您需要创建一个 AWS 帐户,有关更多详细信息,请参阅第 23.2 节。
23.3.1. 创建和运行 EC2 实例
登录您的 AWS 账户后,点击“EC2”(图 23.3.1)进入 EC2 面板。
图 23.3.1打开 EC2 控制台。
图 23.3.2显示了 EC2 面板。
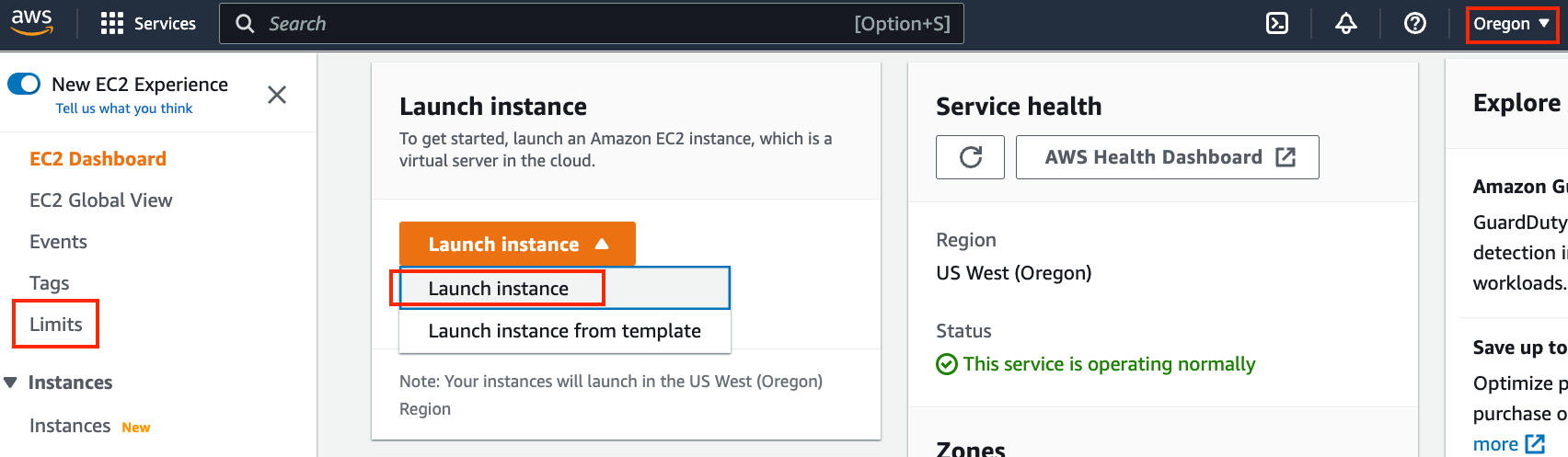
图 23.3.2 EC2 面板。
23.3.1.1。预设位置
选择附近的数据中心以减少延迟,例如“Oregon”(图 23.3.2右上角的红色框标记)。如果您位于中国,则可以选择附近的亚太地区,例如首尔或东京。请注意,某些数据中心可能没有 GPU 实例。
23.3.1.2。增加限制
选择实例前,点击左侧栏中的“Limits”标签查看是否有数量限制,如图 23.3.2所示。图 23.3.3显示了这种限制的一个例子。该帐户目前无法按区域打开“p2.xlarge”实例。如果您需要开启一个或多个实例,请点击“请求提升限额”链接申请更高的实例配额。一般来说,处理一份申请需要一个工作日。
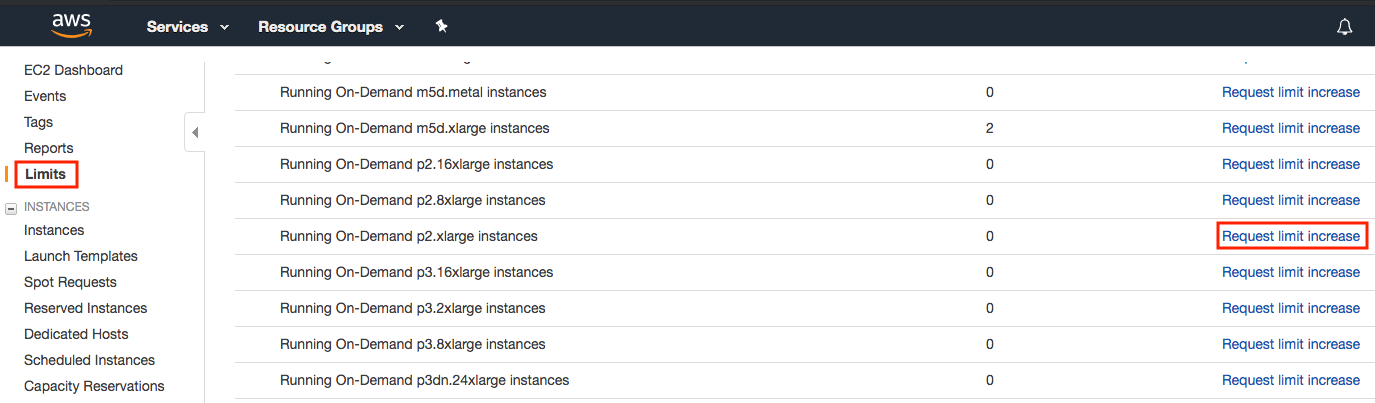
图 23.3.3实例数量限制。
23.3.1.3。启动实例
接下来,单击图 23.3.2中红色框标记的“Launch Instance”按钮 以启动您的实例。
我们首先选择合适的 Amazon Machine Image (AMI)。选择一个 Ubuntu 实例(图 23.3.4)。
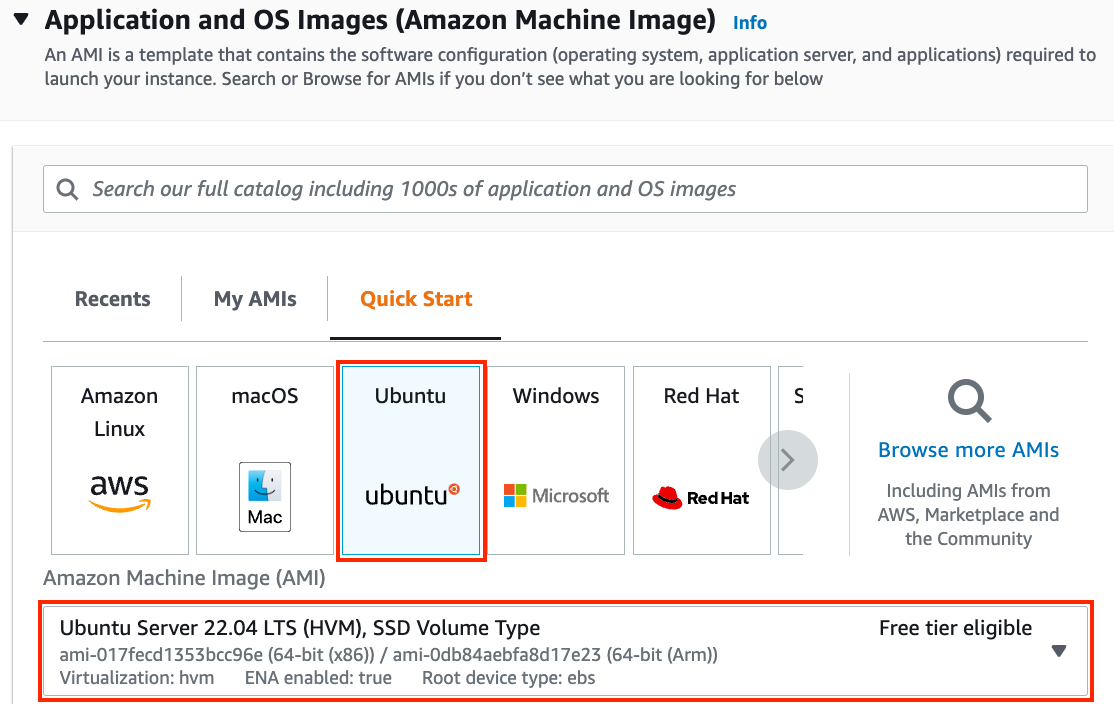
图 23.3.4选择一个 AMI。
EC2 提供了许多不同的实例配置供您选择。这有时会让初学者感到不知所措。表 23.3.1列出了不同的适用机器。
|
姓名 |
显卡 |
笔记 |
|---|---|---|
|
g2 |
格子K520 |
古老的 |
|
p2 |
开普勒K80 |
旧但通常像现货一样便宜 |
|
g3 |
麦克斯韦M60 |
好的权衡 |
|
p3 |
沃尔特V100 |
FP16 的高性能 |
|
p4 |
安培A100 |
大规模训练的高性能 |
|
g4 |
图灵T4 |
推理优化 FP16/INT8 |
所有这些服务器都有多种类型,表明使用的 GPU 数量。例如,p2.xlarge 有 1 个 GPU,p2.16xlarge 有 16 个 GPU 和更多内存。有关更多详细信息,请参阅AWS EC2 文档或 摘要页面。出于说明的目的,p2.xlarge 就足够了(在 图 23.3.5的红色框中标记)。
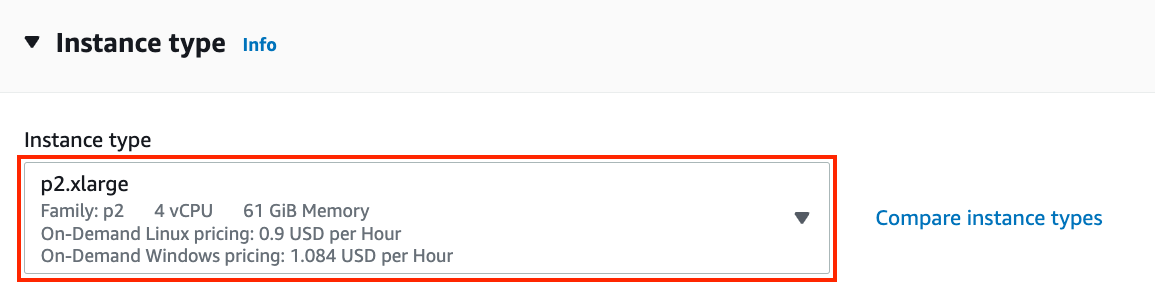
图 23.3.5选择一个实例。
请注意,您应该使用具有合适驱动程序的支持 GPU 的实例和支持 GPU 的深度学习框架。否则,您将看不到使用 GPU 带来的任何好处。
我们继续选择用于访问实例的密钥对。如果没有密钥对,点击 图23.3.6中的“新建密钥对”生成密钥对。随后,您可以选择之前生成的密钥对。如果生成新密钥对,请确保下载密钥对并将其存储在安全位置。这是您通过 SSH 连接到服务器的唯一方法。
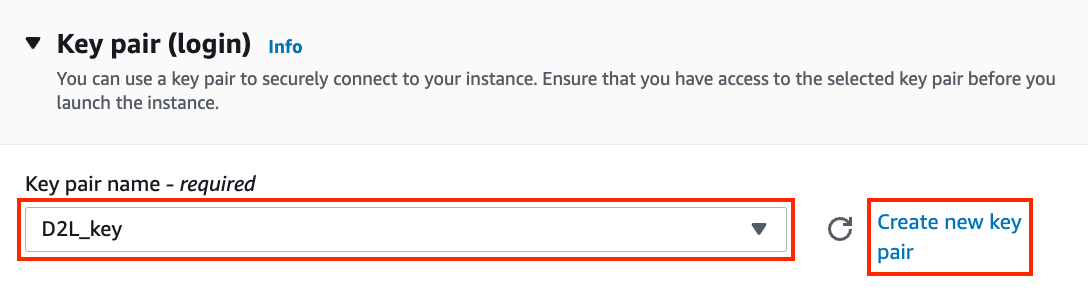
图 23.3.6选择密钥对。
在这个例子中,我们将保留“网络设置”的默认配置(点击“编辑”按钮配置子网和安全组等项目)。我们只是将默认硬盘大小增加到 64 GB(图 23.3.7)。请注意,CUDA 本身已经占用了 4 GB。
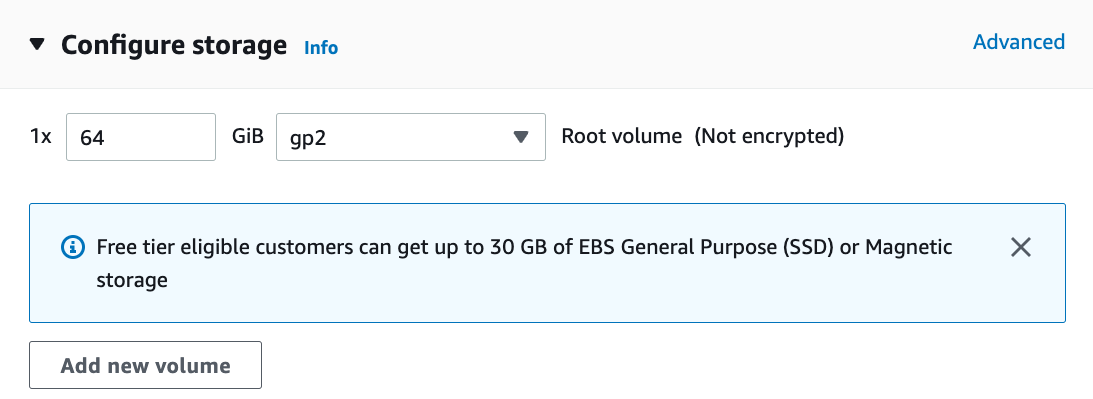
图23.3.7修改硬盘大小。
单击“Launch Instance”以启动创建的实例。点击图23.3.8所示的实例ID,可以查看该实例的状态。
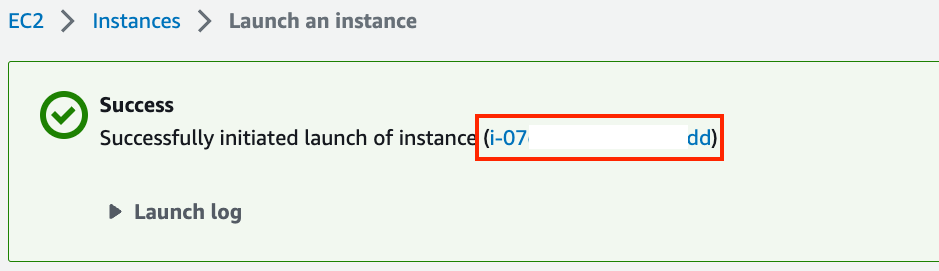
图 23.3.8点击实例 ID。
23.3.1.4。连接到实例
如图23.3.9所示,实例状态变为绿色后,右键单击实例,选择Connect查看实例访问方式。
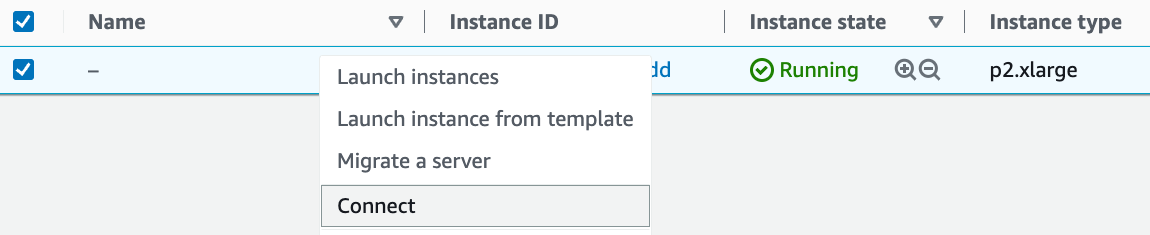
图23.3.9查看实例访问方式。
如果这是一个新密钥,则必须不能公开查看 SSH 才能正常工作。转到您存储的文件夹D2L_key.pem并执行以下命令以使密钥不公开可见:
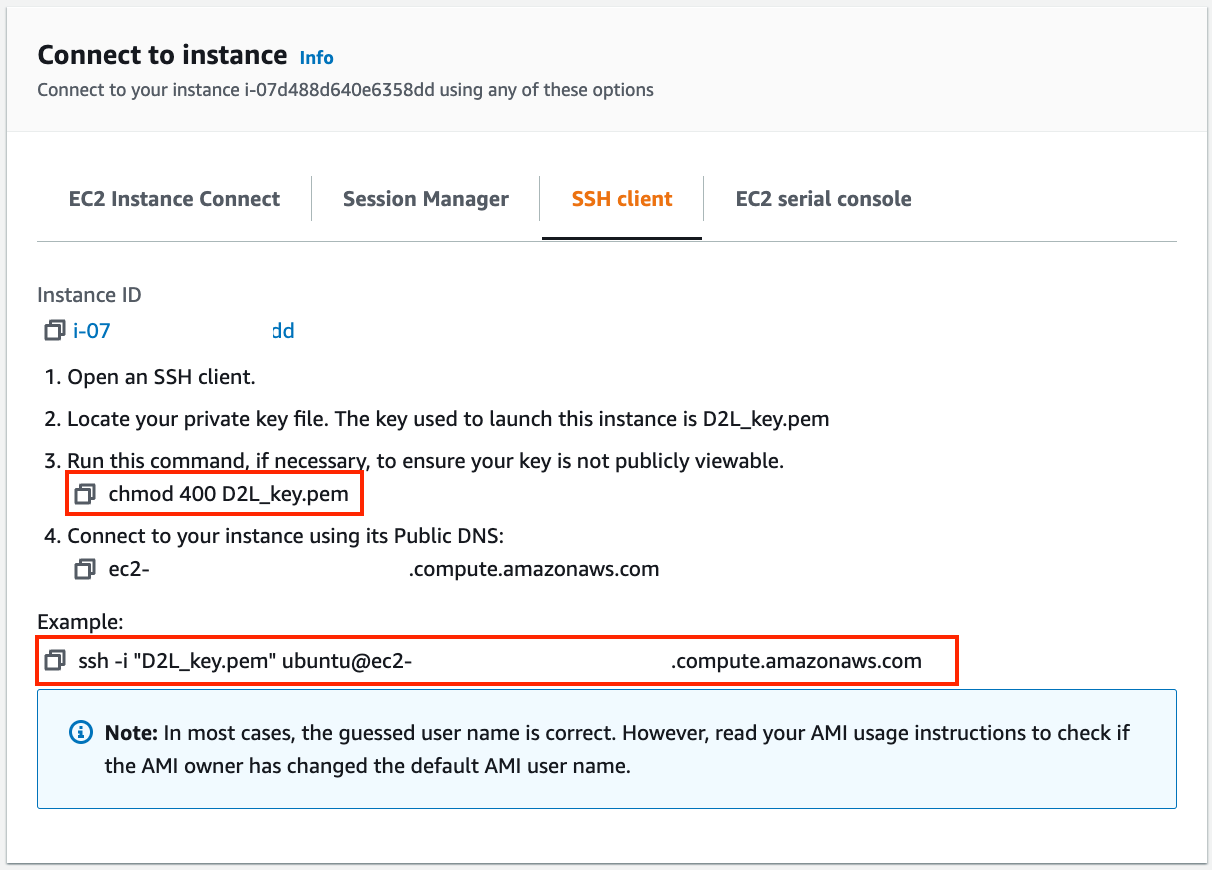
图23.3.10查看实例访问和启动方法。
现在,复制图23.3.10下方红框中的ssh命令 ,粘贴到命令行中:
当命令行提示“Are you sure you want to continue connecting (yes/no)”时,输入“yes”并回车登录实例。
您的服务器现已准备就绪。
23.3.2。安装 CUDA
在安装 CUDA 之前,请务必使用最新的驱动程序更新实例。
这里我们下载CUDA 10.1。访问NVIDIA官方资源库找到下载链接,如图23.3.11所示。
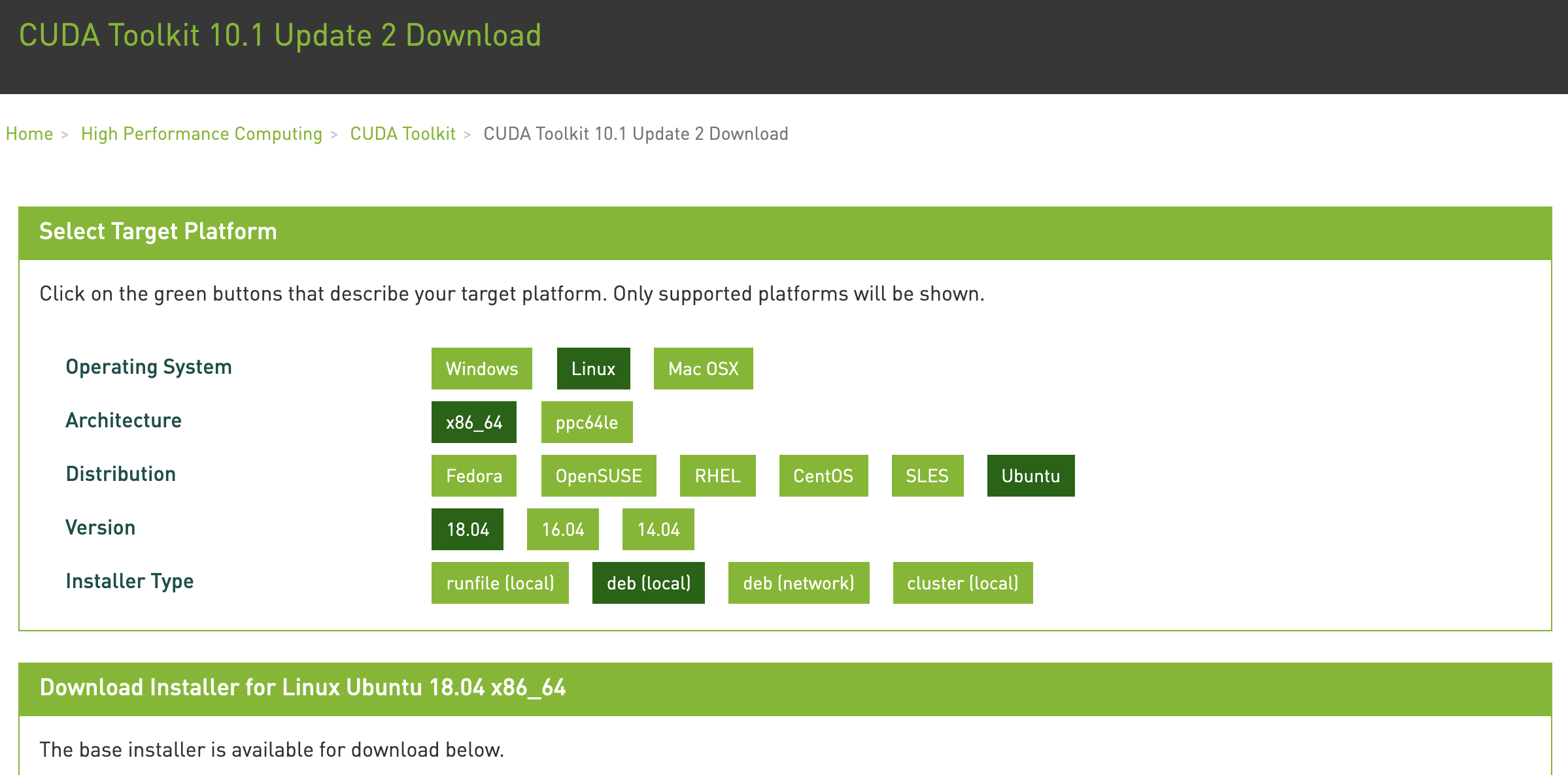
图 23.3.11找到CUDA 10.1下载地址。
复制说明并将其粘贴到终端以安装 CUDA 10.1。
# The link and file name are subject to changes
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
sudo apt-key add /var/cuda-repo-10-1-local-10.1.243-418.87.00/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
安装程序后,运行以下命令查看 GPU:
最后,将CUDA添加到库路径中,以帮助其他库找到它。
23.3.3。安装用于运行代码的库
要运行本书的代码,只需按照 在 EC2 实例上为 Linux 用户安装中的步骤操作,并使用以下在远程 Linux 服务器上工作的提示:
-
在Miniconda安装页面下载bash脚本,右击下载链接,选择“复制链接地址”,然后执行 .
wget [copied link address] -
运行后,您可以执行 而不是关闭并重新打开当前的 shell。
~/miniconda3/bin/conda initsource ~/.bashrc
23.3.4。远程运行 Jupyter Notebook
要远程运行 Jupyter Notebook,您需要使用 SSH 端口转发。毕竟云端的服务器没有显示器和键盘。为此,从您的台式机(或笔记本电脑)登录您的服务器,如下所示:
接下来,到EC2实例上本书下载代码的位置,然后运行:
图 23.3.12显示了运行 Jupyter Notebook 后可能的输出。最后一行是端口 8888 的 URL。
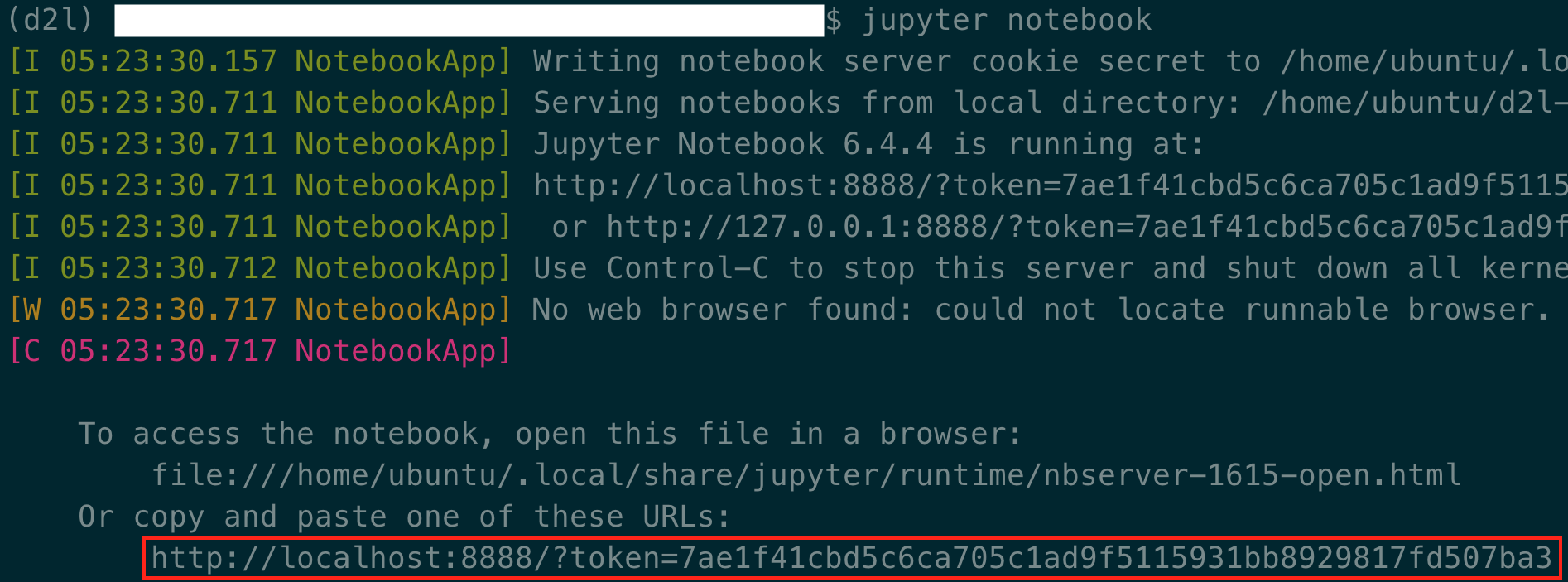
图 23.3.12运行 Jupyter Notebook 后的输出。最后一行是端口 8888 的 URL。
由于你使用了端口转发到8889端口,复制图23.3.12红框中的最后一行,将URL中的“8888”替换为“8889”,在本地浏览器中打开。
23.3.5。关闭未使用的实例
由于云服务按使用时间计费,您应该关闭未使用的实例。请注意,还有其他选择:
-
“停止”实例意味着您将能够再次启动它。这类似于关闭常规服务器的电源。但是,停止的实例仍会为保留的硬盘空间收取少量费用。
-
“终止”实例将删除与其关联的所有数据。这包括磁盘,因此您无法再次启动它。仅当您知道将来不需要它时才这样做。
如果您想将该实例用作更多实例的模板,请右键单击图 23.3.9中的示例并选择“图像” →“创建”以创建实例的图像。完成后,选择“实例状态”→ “终止”终止实例。下次要使用该实例时,您可以按照本节中的步骤,根据保存的图像创建实例。唯一的区别是,在“1. 选择AMI”如图23.3.4所示,您必须使用左侧的“My AMIs”选项来选择您保存的图像。创建的实例将保留存储在映像硬盘上的信息。例如,您不必重新安装 CUDA 和其他运行时环境。
23.3.6. 概括
-
我们可以按需启动和停止实例,而无需购买和构建我们自己的计算机。
-
在使用支持 GPU 的深度学习框架之前,我们需要安装 CUDA。
-
我们可以使用端口转发在远程服务器上运行 Jupyter Notebook。
23.3.7。练习
-
云提供了便利,但并不便宜。了解如何启动Spot 实例 以了解如何降低成本。
-
试验不同的 GPU 服务器。他们有多快?
-
试验多 GPU 服务器。你能把事情扩大到什么程度?



