
资料下载


构建一个自动化标签快速准确的检测系统
石胜厚
分享资料个
描述
每天,数十亿个可变数据标签被用来提供重要的消费者信息、捍卫品牌、提供品牌保护和标识,以及跟踪或识别事物。如此多的功能被打包到一个很短的区域。写在标签上的信息,无论是用作邮寄物品上的路由条形码还是用于帮助识别产品,都必须清晰准确,标签本身也必须放置得当。标签检测系统提供的功能可确保满足这些标准。
打印质量受多种因素影响很大,包括机器设置、环境条件和原材料质量。贴错标签、墨水溢出、污迹斑斑的文字、缺失的印刷品、圆点和标记是与印刷相关的常见现象。这些缺陷不仅会留下误解和错误信息的可能性,还会导致客户反复拒绝并降低品牌价值。检查印刷质量是一个关键步骤,可以让您的生产免于所有这些麻烦。
因此,我们正在尝试构建一个自动化标签快速准确的检测系统,利用 FOMO 的功能来检测墨水污迹、异物、不需要的点和标记、倒置标签以及许多其他打印问题。由于 FOMO 快速准确,因此可以以极低的价格构建自动标签检测系统,并具有极高的准确性和速度。


的
它是如何工作的
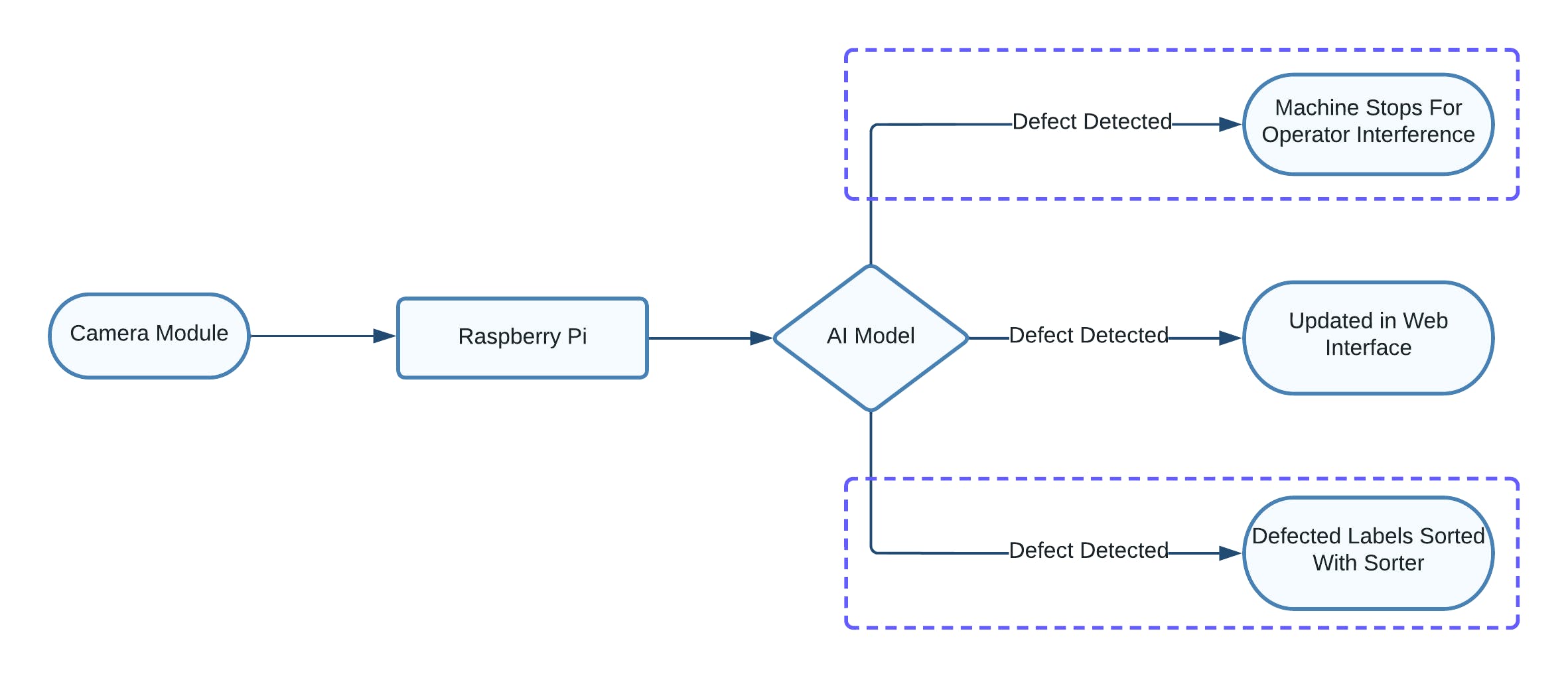
我们的系统由一个 Raspberry Pi 4 和一个兼容的 5 MP 摄像头模块组成。该系统不断运行使用 FOMO 构建的 AI 模型。该模型目前能够检测墨水溢出、墨水污迹、模切和倒置标签。可以轻松添加更多类,并且可以使系统更加健壮。
如果系统检测到任何已知缺陷,它会在 Web 界面中生成警报,可以轻松监控。这个系统可以很容易地调整,只要在印刷机本身检测到缺陷,机器就会立即停止以防止操作员干预,从而减少由于机器错误导致任何此类缺陷的可能性。或者,该系统可以很容易地用于使用分类器设备从一组印刷标签中对有缺陷的标签进行分类。
的
硬件要求
- 树莓派 4
- 5 MP 摄像头模块
软件要求
- 边缘脉冲
- Python
硬件设置
硬件设置非常简单。它由一个 Raspberry Pi 4 Model B 和一个兼容的 5 MP 摄像头模块组成。


软件设置
Raspberry Pi 4 随附快速入门指南,可帮助您在设备上设置 Edge Impulse。按照说明将您的设备连接到 Edge Impulse Dashboard。
的
构建 TinyML 模型
一旦我们设置了硬件和软件,现在就可以构建 tinyML 模型了。让我们从收集一些数据开始。
1. 数据采集与标注
我们的数据由四类组成:墨水污迹、墨水溢出、模切和倒置标签。




我们收集了属于每个类别的 20 张图像,并使用数据上传器上传了它们。从Labeling Queue中给它们打上标签,按照 80:20 的比例分成训练集和测试集,这样就形成了一个很好的数据集,可以开始模型训练了。
2. 脉冲架构
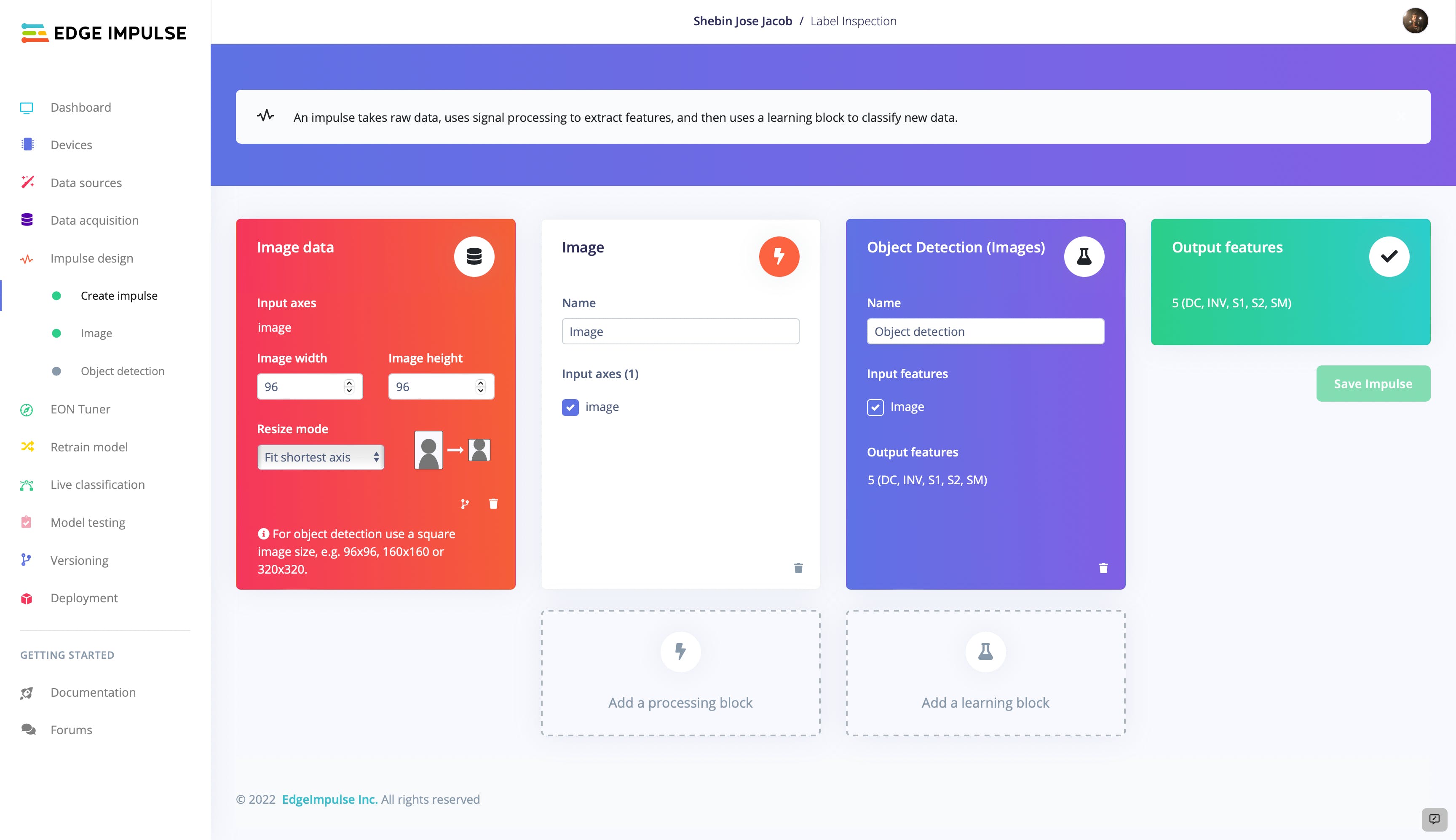
由于我们使用 FOMO 作为我们的对象检测模型,它在 96 X 96 图像上表现更好,我们将图像宽度和高度设置为 96px。保持调整大小模式以适合最短轴,向脉冲添加图像处理块和对象检测(图像)学习块。
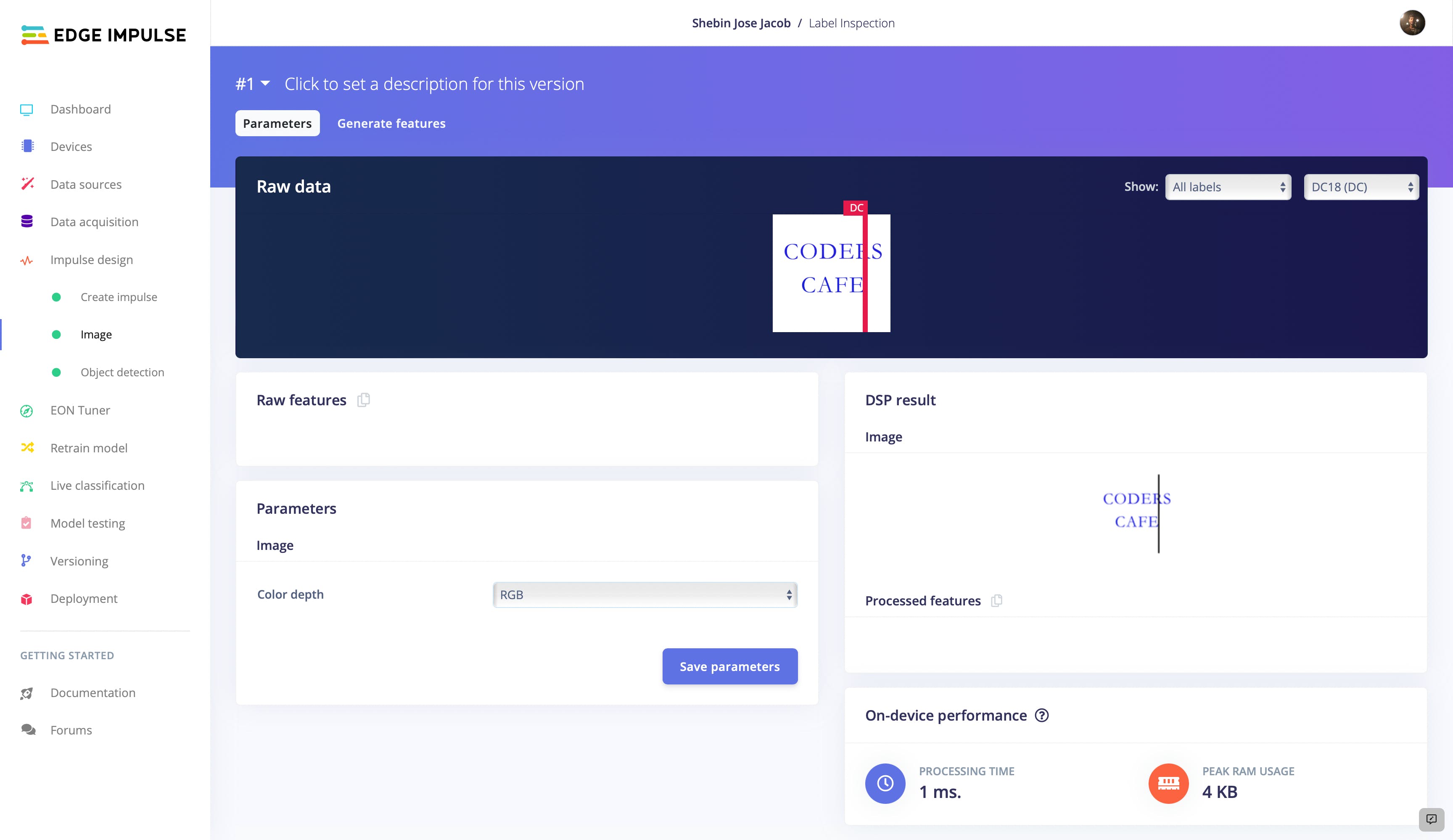
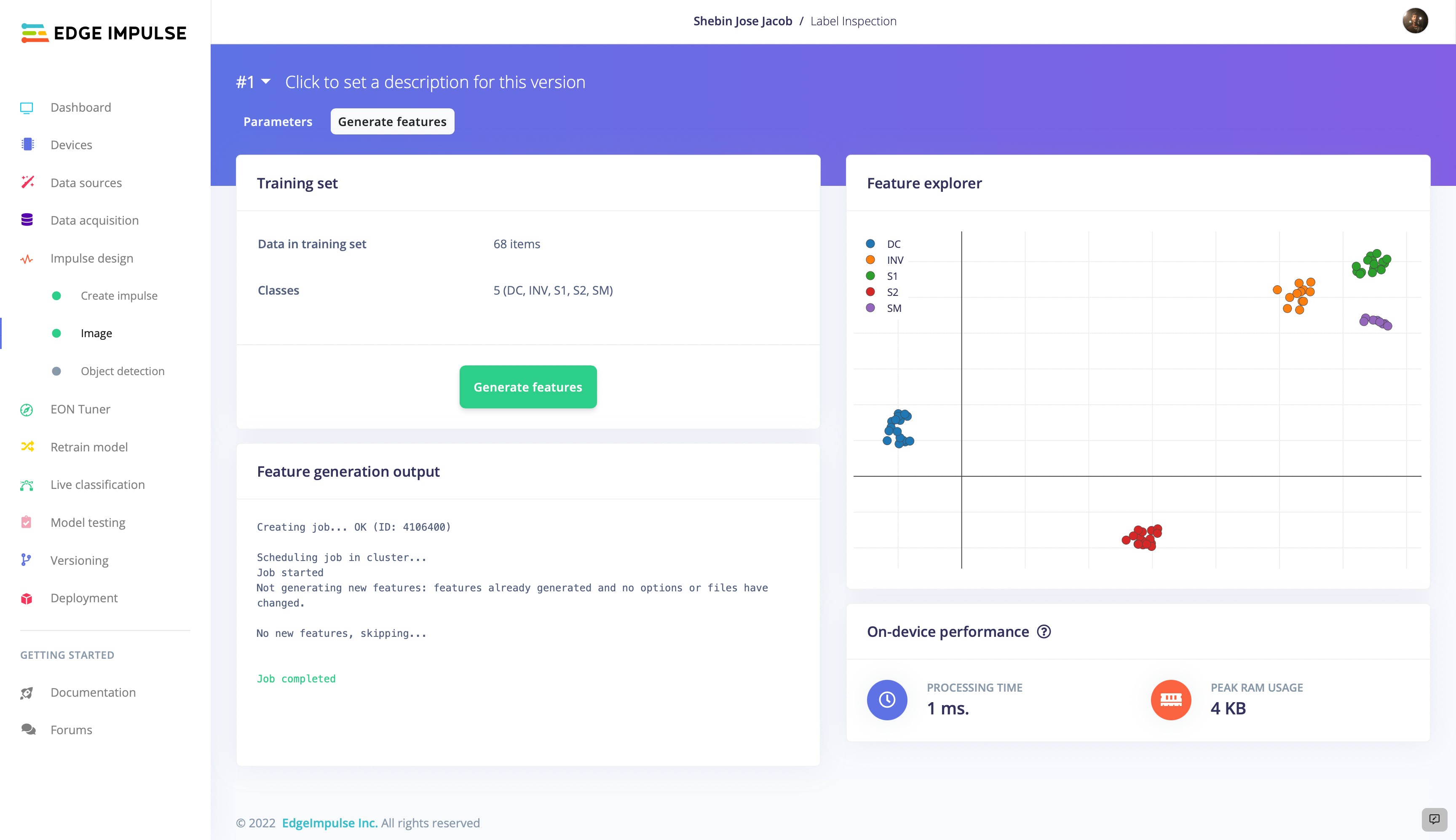
继续保持设置不变,并使用Feature Explorer查看数据集合和类的分离程度。
3. 模型训练与测试
一旦我们设计了我们的冲动,让我们继续训练模型。我们使用的模型训练设置如图所示。您可以调整参数,使经过训练的模型显示出更高的准确性,但在使用模型训练设置时要小心过度拟合。
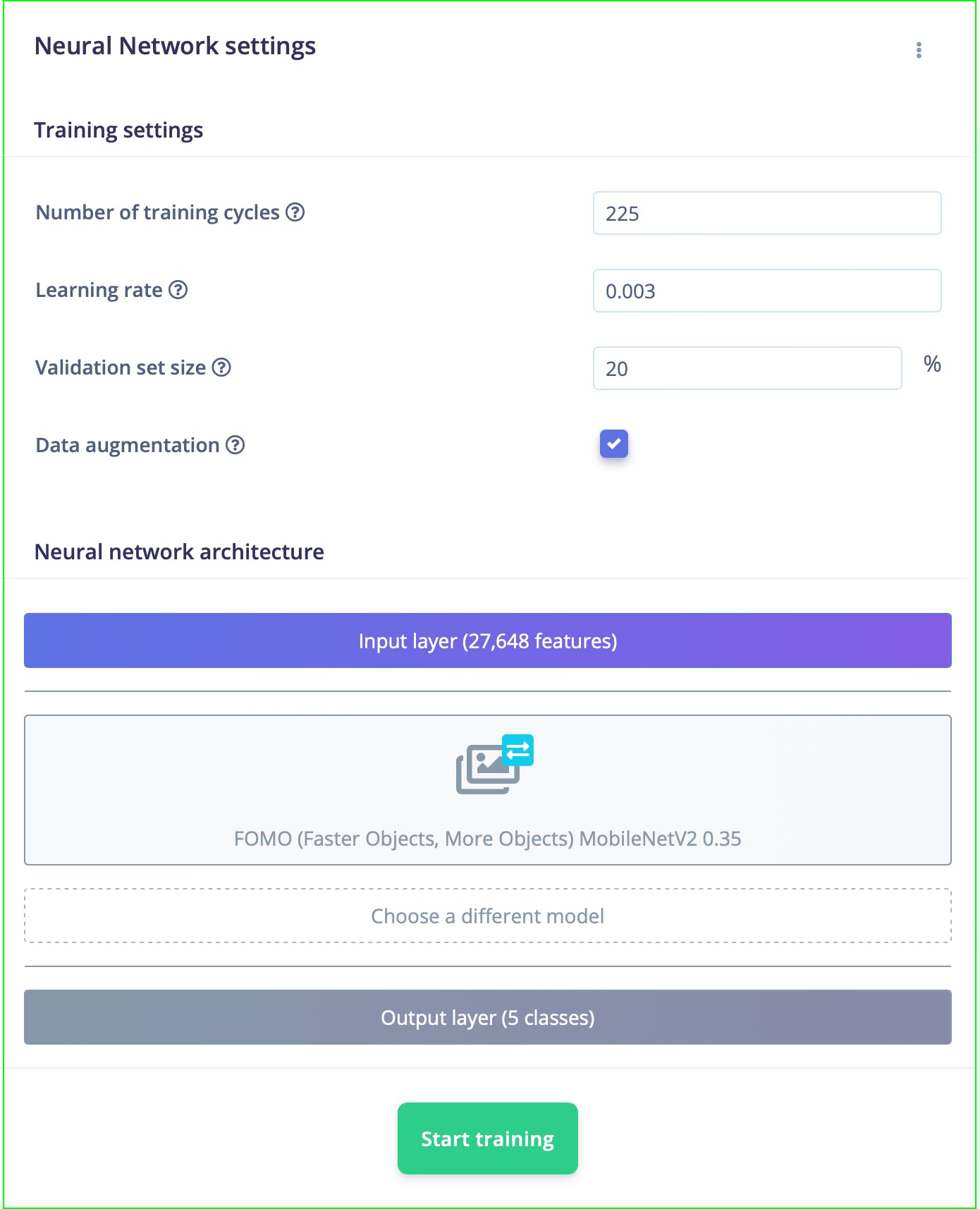
在本例中,我们使用FOMO (MobileNet V2 0.35)作为神经网络,输出快速、轻量级且可靠的机器学习模型。我们使用 225 个学习周期和 0.003 的学习率来构建一个功能齐全的模型。
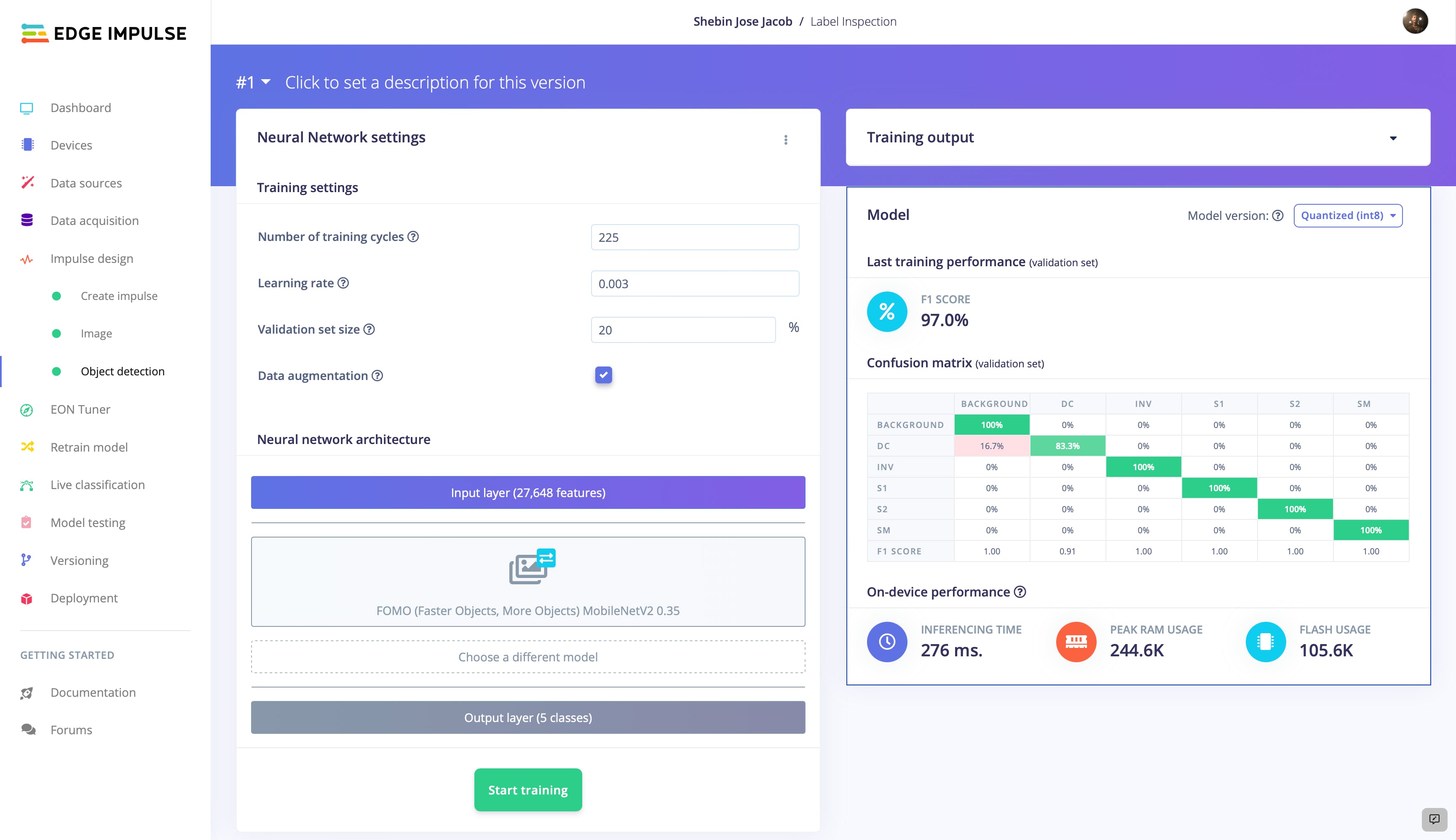
经过训练的模型准确率达到 97%,非常棒。现在让我们测试模型如何处理一些以前未知的数据。继续进行模型测试和全部分类以评估模型的性能。
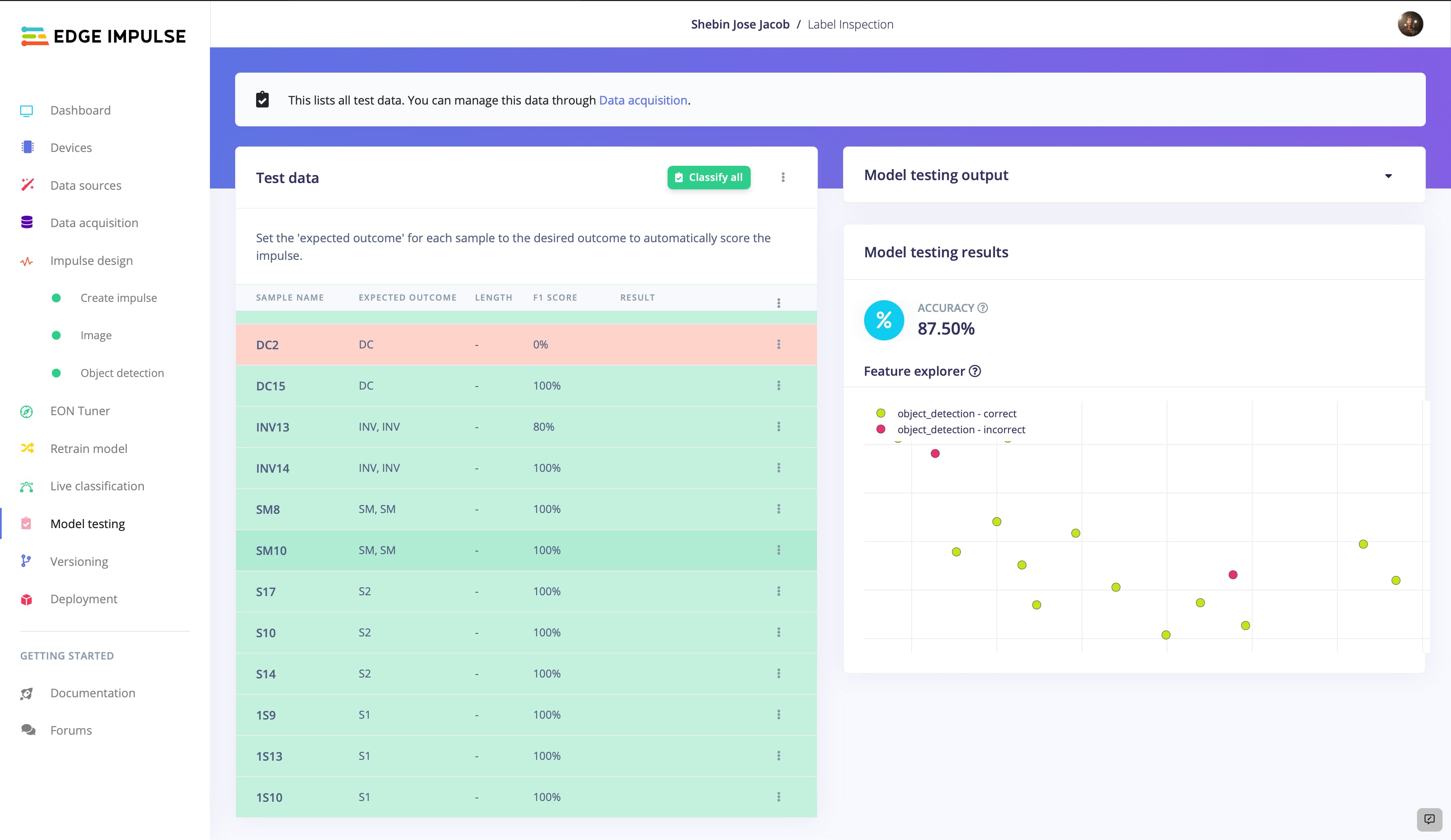
我们有 87.5% 的准确率,非常有前途。现在让我们用一些实时分类再次验证它。导航到实时分类并从您的开发板或上传的测试数据中收集一些图像样本。
4.直播分类
在这里,我们从 RPI 4 收集一些数据并进行测试。
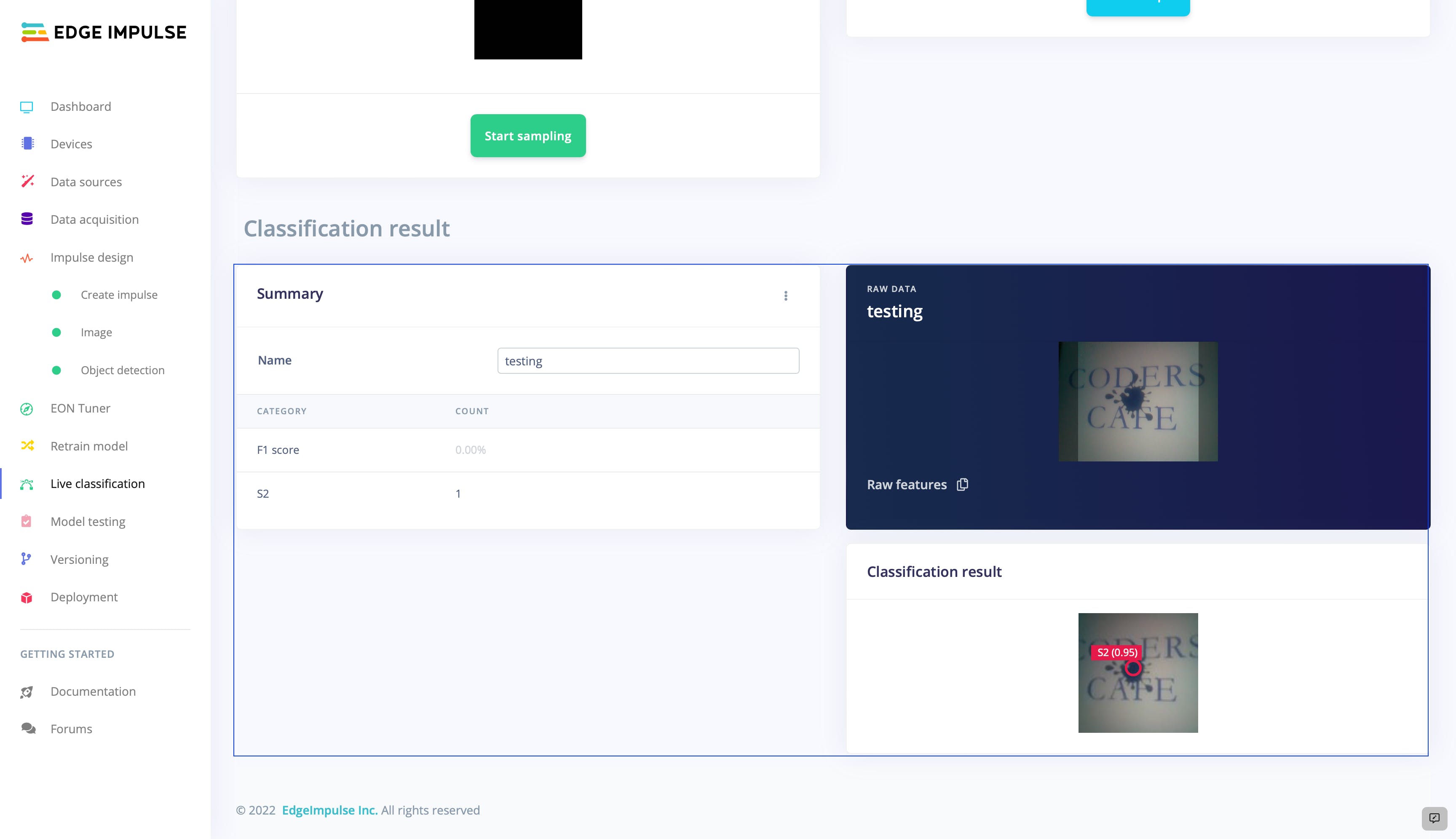
该模型运行良好。现在让我们将它部署回设备。
Firebase 实时数据库
对于我们的项目,我们使用了 Firebase 实时数据库,它使我们无需等待即可快速上传和检索数据。在这种情况下,我们利用了 Pyrebase 包,它是 Firebase 的 Python 包装器。
要安装 Pyrebase,
pip install pyrebase
在数据库中,按照给定的步骤操作。
- 创建项目
- 然后导航到构建部分并创建一个实时数据库。
- 以测试模式启动,因此我们可以在不进行任何身份验证的情况下更新数据
- 从项目设置中,复制配置。
现在通过替换配置详细信息将这段代码添加到您的 python 文件中以从 firebase 访问数据。
import pyrebase
config = {
"apiKey": "apiKey",
"authDomain": "projectId.firebaseapp.com",
"databaseURL": "https://databaseName.firebaseio.com",
"storageBucket": "projectId.appspot.com"
}
firebase = pyrebase.initialize_app(config)
网络界面
我们正在使用一个使用 HTML、CSS 和 JS 创建的网页来实时显示缺陷。Firebase 实时数据库中更新的数据在网页上实时更新。该网页显示各种缺陷及其发生情况,以便操作员可以轻松查找特定问题。
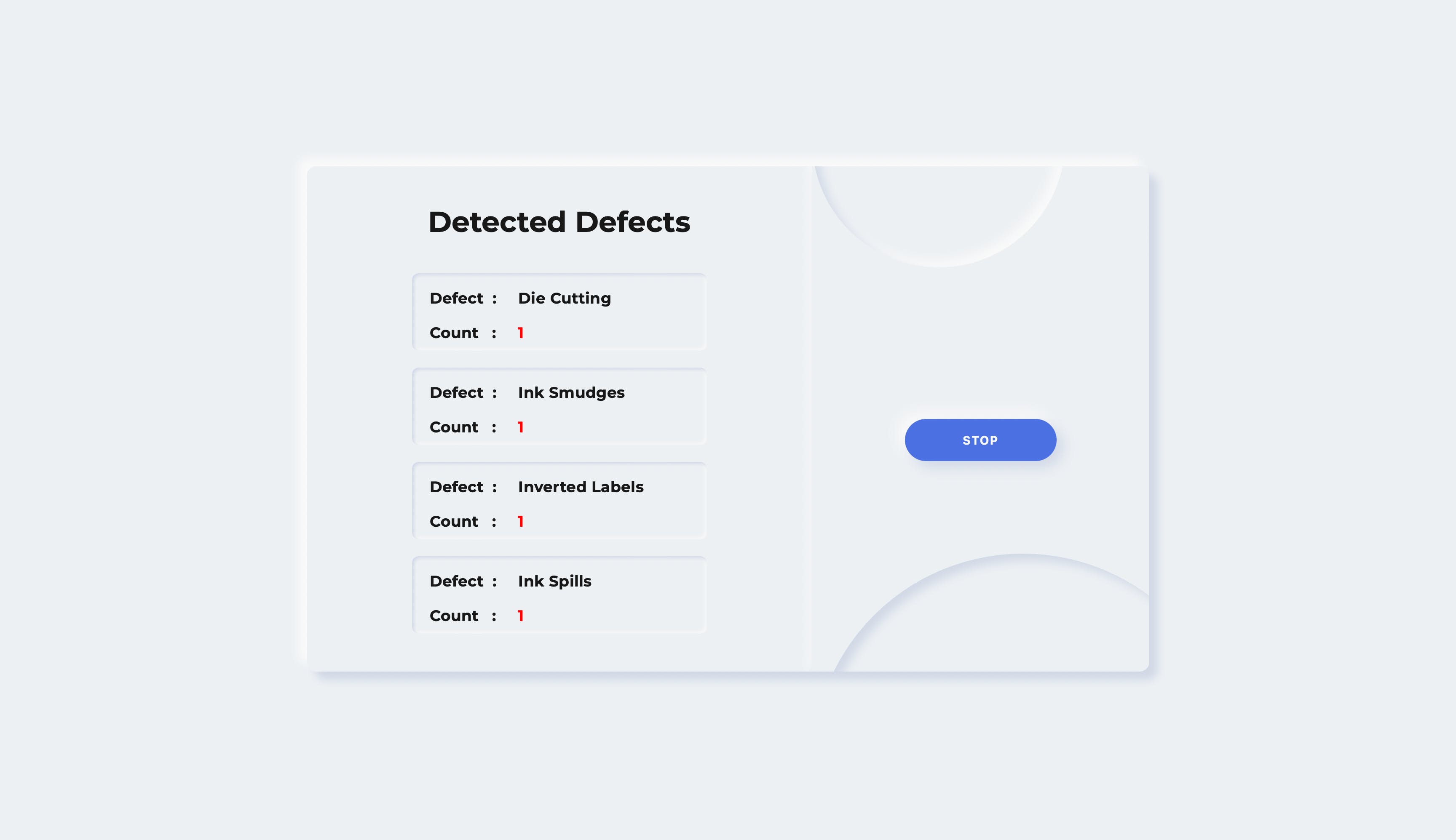
代码
该项目的代码是使用 Python 和 Edge Impulse Python SDK 开发的。整个代码和资产在 github 存储库中可用。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章







