
资料下载


AXU2CGB Zynq UltraScale板上的GNU Radio工具包 第4部分
h1654155273.0656
分享资料个
描述
这是如何为 Alinx 制造的AXU2CGA/B Zynq UltraScale+ FPGA 开发板创建硬件加速器平台的分步教程,该平台 可用于在 Xilinx Vitis 工具集下运行具有加速功能的 GNU Radio 应用程序。
添加 EA4GPZ 开发的gr-satellites并构建您自己的 OOT 模块也包含在这套教程中。
这是第 4/4 部分:在 Colab 和 Vitis-AI 中构建 AI 模型
如果你正在寻找这组教程的其他部分,你可以直接去那里:
- 第 1 部分 - 创建 Vivado 硬件设计
- 第 2 部分 - 软件 - 构建 PetaLinux 和 GNU Radio
- 第 3 部分 - 使用 DPU 创建 Vitis 平台和应用程序
- 第 4 部分 - 在 Colab 和 Vitis-AI 中构建 AI 模型
获取射频数据集
RF 数据集可以从RF Datasets For Machine Learning网站免费下载。选择RADIOML 2018.01A数据集并下载2018.01.OSC.0001_1024x2M.h5.tar.gz文件。
您应该提供您的联系信息以供下载,但该数据集是免费的。您需要大约 20 GB 的磁盘可用空间来下载。
还有另一个选项可以将数据集的大小减少到仅约 6%。这足以开始。本教程使用精简的数据集(仅约 1.2 GB),可以从随附的 Jupyter Notebook 脚本中提供的链接下载。
这是用于减少原始大型数据集的脚本:
您可以跳过此下载步骤并直接跳到下一步,以防万一您不想下载和使用整个数据集。
否则,如果您想将原始数据集作为一个整体使用,请跳转到Xilinx 教程 - RF 调制识别GitHub 页面并使用他们的原始脚本来构建模型。在这种情况下,您可以跳过本教程的剩余部分。
获取 Jupyter Notebook Scrips
本教程中提供了两个 Jupyter 脚本。第一个将在Google Colab上运行,第二个将在Xilinx Vitis-AI Docker 映像上运行。
克隆s59mz/test-dpu GitHub 存储库并记下 Jupyter 子目录中的两个 Jupyter 笔记本脚本。我们稍后会需要它。
- rf_classification-Colab.ipynb
- rf_classification-Vitis-AI.ipynb
$ git clone http://github.com/s59mz/test-dpu
$ cd test-dpu/
$ ls jupyter/
rf_classification-Vitis-AI.ipynb
rf_classification-Colab.ipynb
reduce_dataset.ipynb
注意:reduce_dataset.ipynb可用于手动减少原始数据集,如上一节所述。
获取 arch.json 文件
这是为 DPU 编译模型的非常重要的文件。该文件位于模型目录中:
$ ls models/*.json
models/arch_b1152.json
$ cat models/arch_b1152.json
{"fingerprint":"0x100002062010103"}
注意:指纹可以通过在 FPGA 板上运行以下命令直接从目标板上读取:
$ export XLNX_VART_FIRMWARE=/media/sd-mmcblk1p1/dpu.xclbin
$ xdputil query
注意:编辑arch.json文件并手动更新指纹参数,以防您更改 DPU 构建配置(dpu_conf.vh 文件)
构建和训练 AI 模型
我们将构建的 AI 模型使用TensorFlow框架。我们使用Google Colab服务来训练模型,因为我们可以免费使用他们非常强大的显卡进行计算,但仅限于有限的时间(几个小时)。
在 Colab 断开您与他们的服务之间的连接之前,请务必将您训练的模型下载并保存到您的计算机上。您可以在第二天重复整个过程,任意多次,但每次都必须从头开始。
- 打开您的网络浏览器(推荐使用 Google Chrome 或 Firefox)并打开Google Colab网页。
- 将第一个脚本rf_classification-Colab.ipynb上传到 Colab(文件 > 上传笔记本)。如果您还没有登录,您应该使用您的 Google 帐户登录。
- 展开窗口左侧的文件图标,这样您就可以在那里看到一些新创建的文件 (sample_data)。
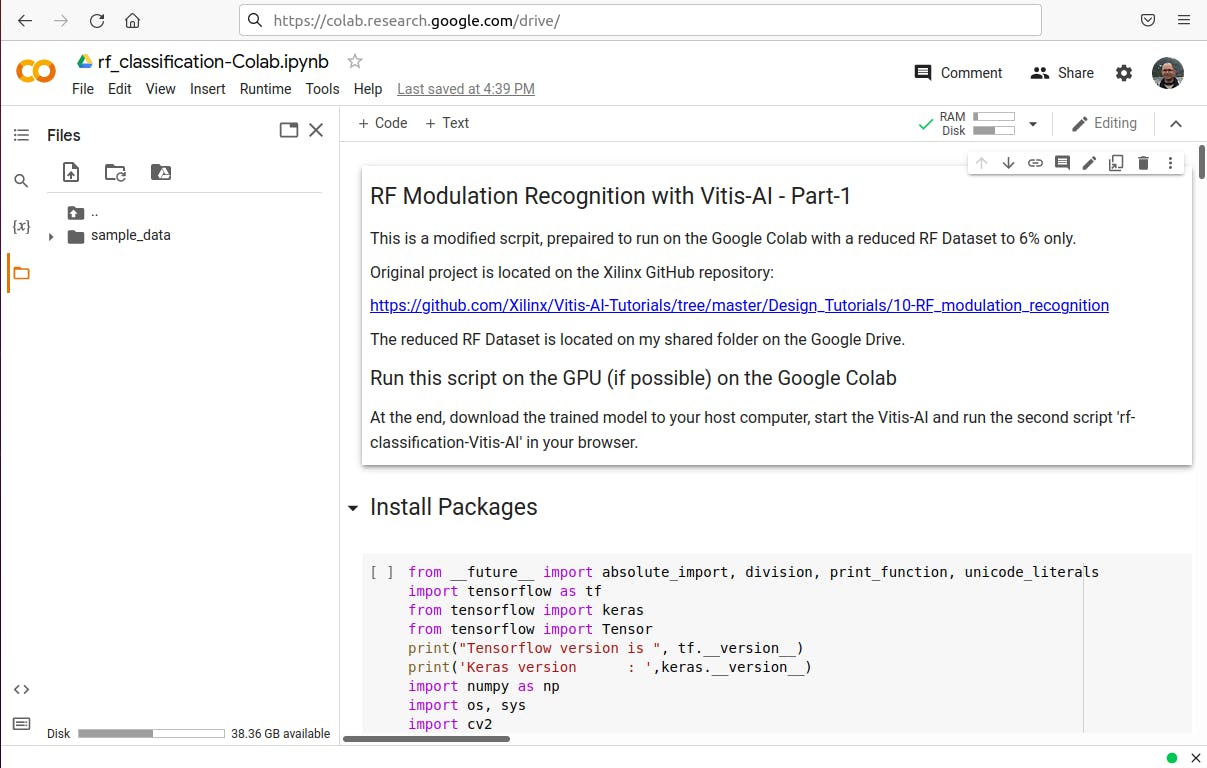
- 将 Runtime 设置为 GPU:Runtime > Change Runtime type > GPU并保存,如果可用,否则使用 CPU,但训练时间会更长。
- 启动脚本:Runtime > Run all并等待大约半小时。
刚刚发生了什么?
- 该脚本首先从我的 Google Drive 下载缩减的数据集。您可以更改 Cell #2 (!wget...) 中的路径以使用您自己的数据集。您应该会看到一个新文件reduce_rf_dataset_XYZ.hdf5出现在左侧。
- 经过一些数据处理和准备后,模型将被训练,您可以在检查点文件夹中看到一些保存的检查点状态。
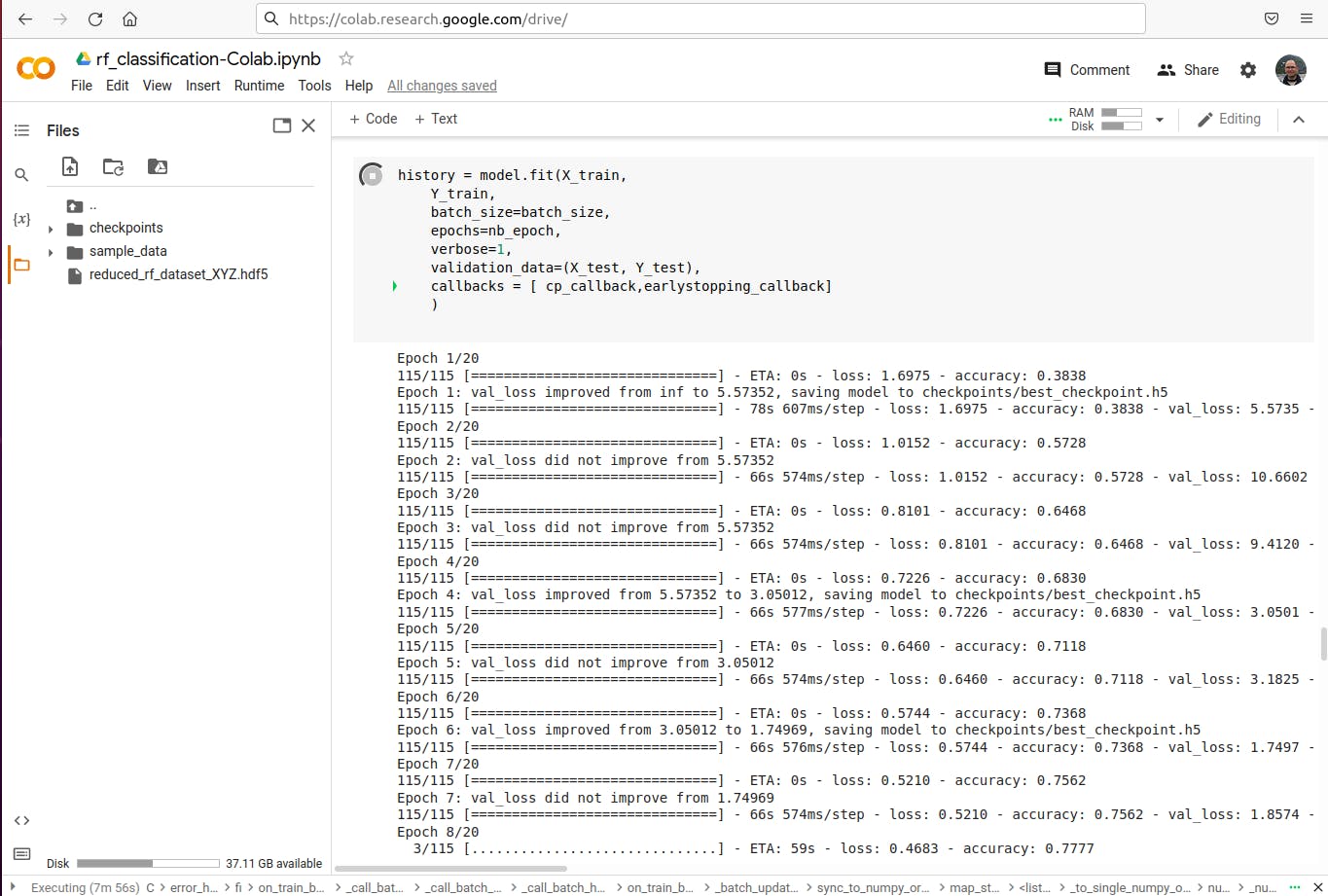
- 脚本完成后,您会注意到另一个新文件:保存的最佳训练模型,名为rf-model-best.h5 。
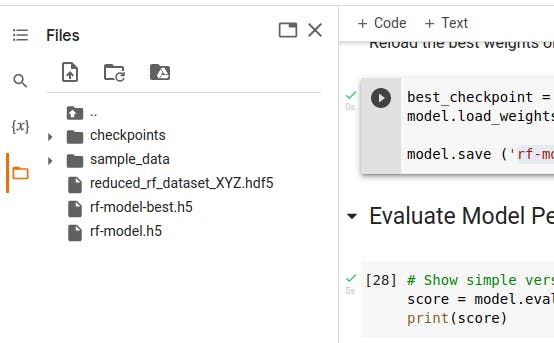
- 将经过训练的模型rf-model-best.h5 下载到您的计算机,然后 Colab 会因不活动而断开您与服务的连接。
- 训练后的模型也可以在GitHub存储库中找到(使用不同的名称):rfClassification_fp_model.h5
- 探索结果。这是一个混淆矩阵,我们仅使用数据集中 6% 的样本得到了 10 个 epoch 的训练。
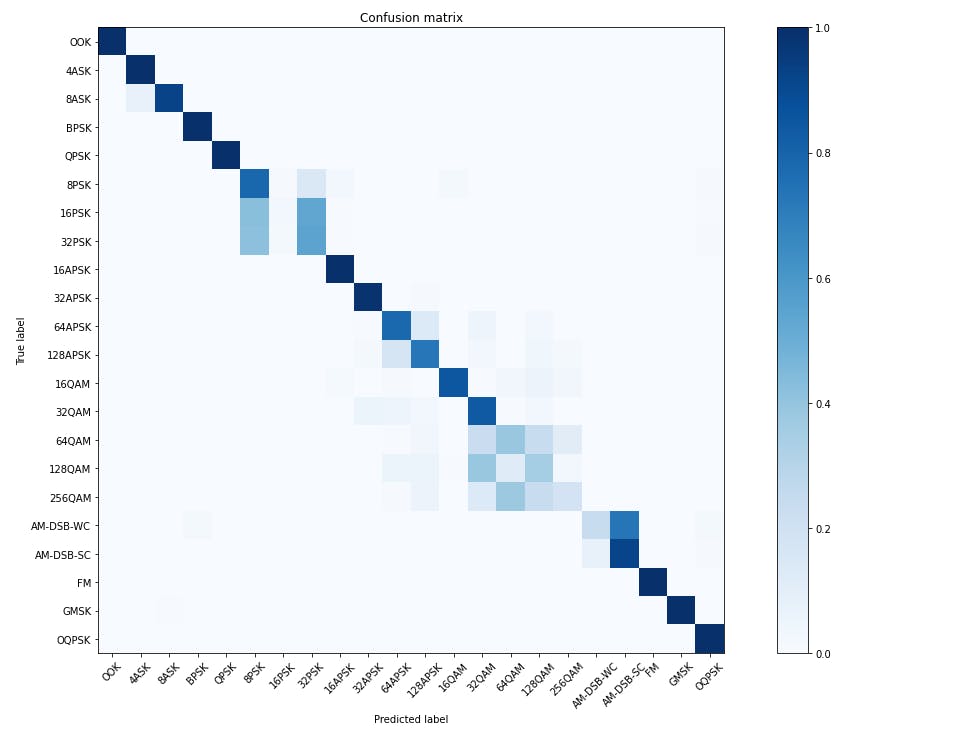
- 不完美,但足以作为在真实 FPGA 上测试模型的起点。
- 随意使用来自数据集的更多数据样本或更长的训练时间(epochs)再次重复整个过程,甚至可以根据需要改进模型以获得更准确的结果。
- 但是,请记住:您每天使用 Google Colab 的时间是有限的(大概 2 小时左右)。因此,每次下载模型后都要关闭会话(连接 > 管理会话 > 终止)。
在 Vitis-AI 上编译模型
现在,由于我们有一个名为rf-model-best.h5的浮点模型,我们需要对其进行量化、校准和编译,以便在真实 FPGA 的 DPU 单元上使用它。
此过程的详细信息超出了本教程的范围。随意地:
- 探索提供的脚本rf_classification-Vitis-AI.ipynb
- 阅读Vitis-AI的官方 GitHub 页面。
以下是主要步骤:
- 如果您还没有 Docker,请在您的主机上安装Docker 。
- 使用以下命令下载最新的 Vitis AI Docker 映像:
docker pull xilinx/vitis-ai-cpu:latest
- 将Vitis-AI GitHub 存储库克隆到您的主机。
git clone --recurse-submodules https://github.com/Xilinx/Vitis-AI
- 将先前克隆的rf_classification-Vitis-AI.ipynb脚本复制到 Vitis-AI 存储库以及上一节中训练好的模型rf-model-best.h5 。您可以创建一个新的my_model目录和一个子目录fp_model来复制您的训练模型。
- 还将arch_b1152.json文件复制到同一目录,除非您也更新 Jupyter 脚本,否则不要更改文件名。
$ cd Vitis-AI
$ mkdir -p my_model/fp_model
$ cp ~/test-dpu/jupyter/rf_classification-Vitis-AI.ipynb my_model
$ cp ~/Downloads/rf-model-best.h5 my_model/fp_model
$ cp ~/test-dpu/models/arch_b1152.json my_model
$ cd my_model
$ ls
arch_b1152.json fp_model rf_classification-Vitis-AI.ipynb
- 使用 bash 脚本从my_model目录启动 Docker 映像。
$ ../docker_run.sh xilinx/vitis-ai
- 当 Docker 启动时,通过执行conda activate命令切换到 TensorFlow2。
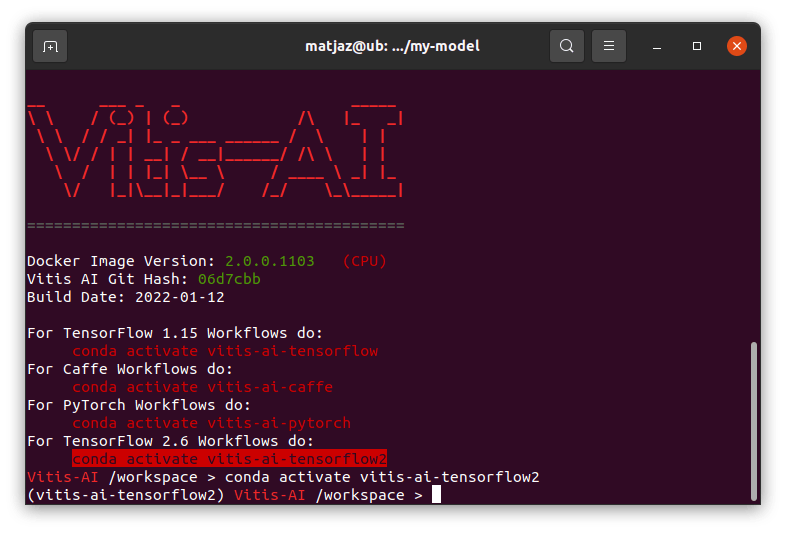
- 通过运行以下命令(在 Docker 内部)启动Jupyter Notebook :
$ jupyter notebook --no-browser --ip=0.0.0.0 --NotebookApp.token='' --NotebookApp.password=''
- 现在,打开主机上的 Web 浏览器并打开名为http://localhost:8888/的网页
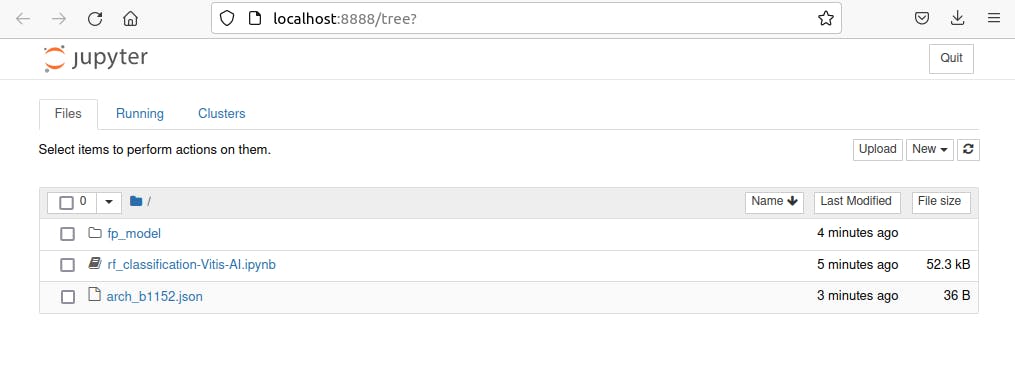
- 点击之前复制的脚本rf_classification-Vitis-AI.ipynb
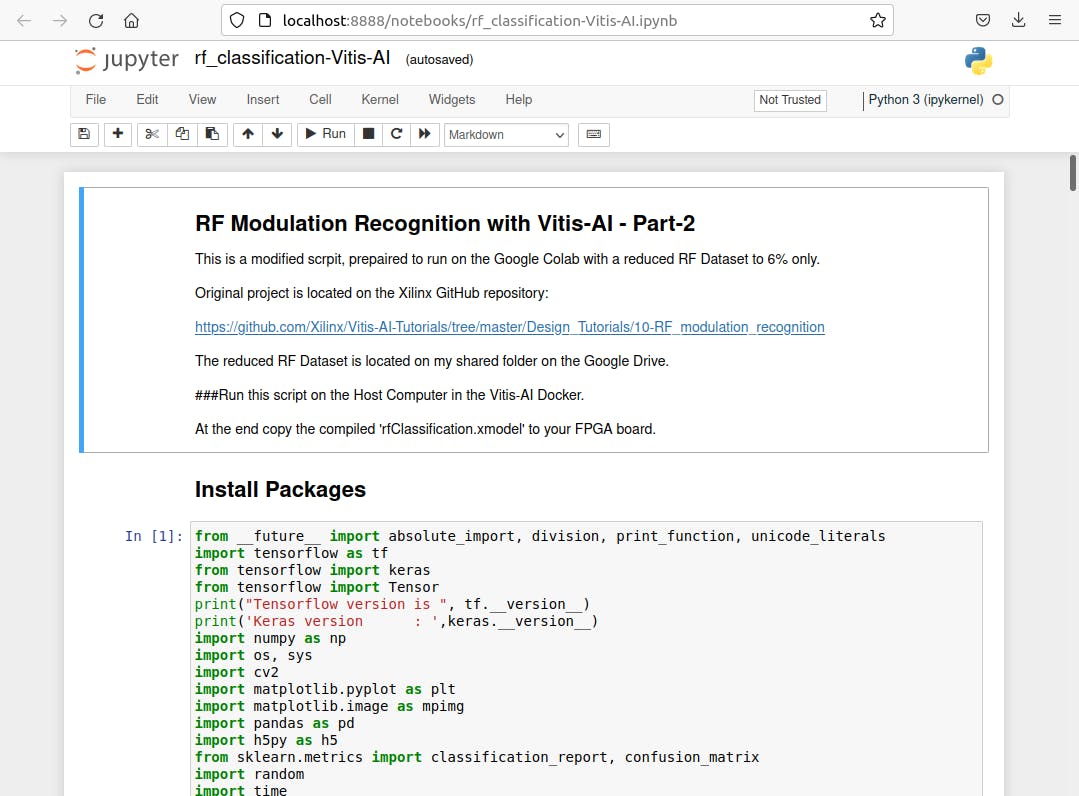
- 运行脚本:Kernel > Restart & Run All并等待几分钟得到编译好的模型。
- 注意:校准所需的缩减数据集(1.2 GB) 将从我的 Google Drive 下载到您的计算机。您可以修改脚本并使用自己的数据集进行校准。
- 然后,将创建一个新的量化模型,该模型由先前下载的校准数据集进行优化。它位于quantize_results/quantized_model.h5目录中。
- 最后,将创建一个新目录vai_c_output 。
- 里面是我们的rfClassification.xmodel文件,准备上传到我们的目标板。
在目标板上测试模型
现在,我们准备在真实硬件上测试模型。
- 将SD 卡上的原始rfClassification.xmodel文件复制或替换为新文件。它位于 test-dpu/models 目录的引导分区中。
$ pwd
/media/sd-mmcblk1p1/test-dpu/models
- 如果您更改模型的名称,您还应该更新测试脚本以及 RF Claasification GNU Radio 模块。否则,只需将原始文件替换为新文件即可。
- 从第 3 部分运行准确性测试:
$ pwd
/media/sd-mmcblk1p1/test-dpu
$ ./run_test_accuracy.sh
Number of RF Samples Tested is 998
Batch Size is 1
Top1 accuracy = 0.53
最后...
再次在 GNU Radio 上启动RF 调制分类应用程序。
$ pwd
/media/sd-mmcblk1p1/test-dpu
$ ./run_rf_classification.sh
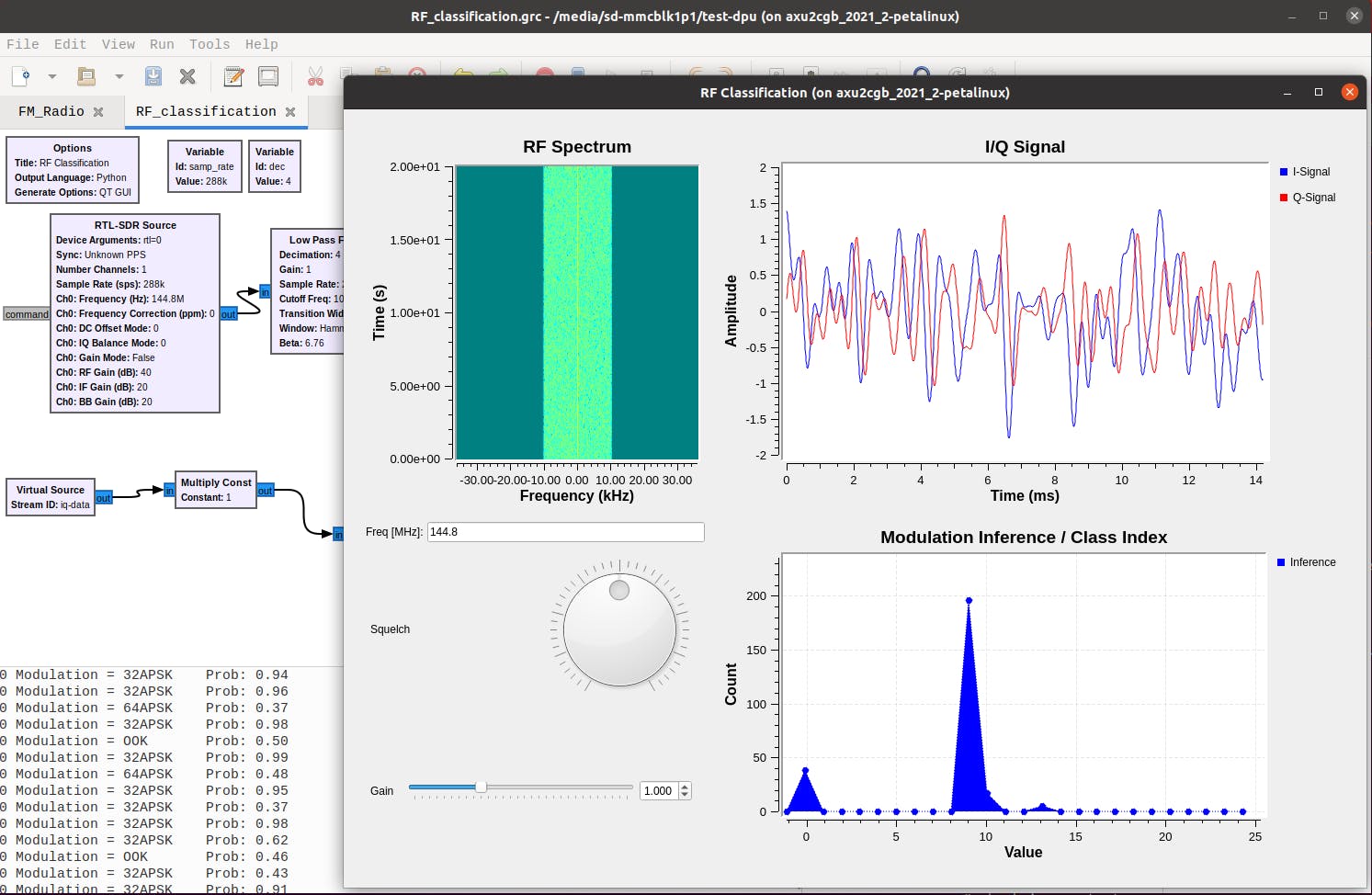
就这样 !
如果您成功通过所有四个部分来到这里,恭喜!
随时在此博客上发表评论。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





