
资料下载


合成数据的不合理有效性
池鹄展
分享资料个
描述
介绍
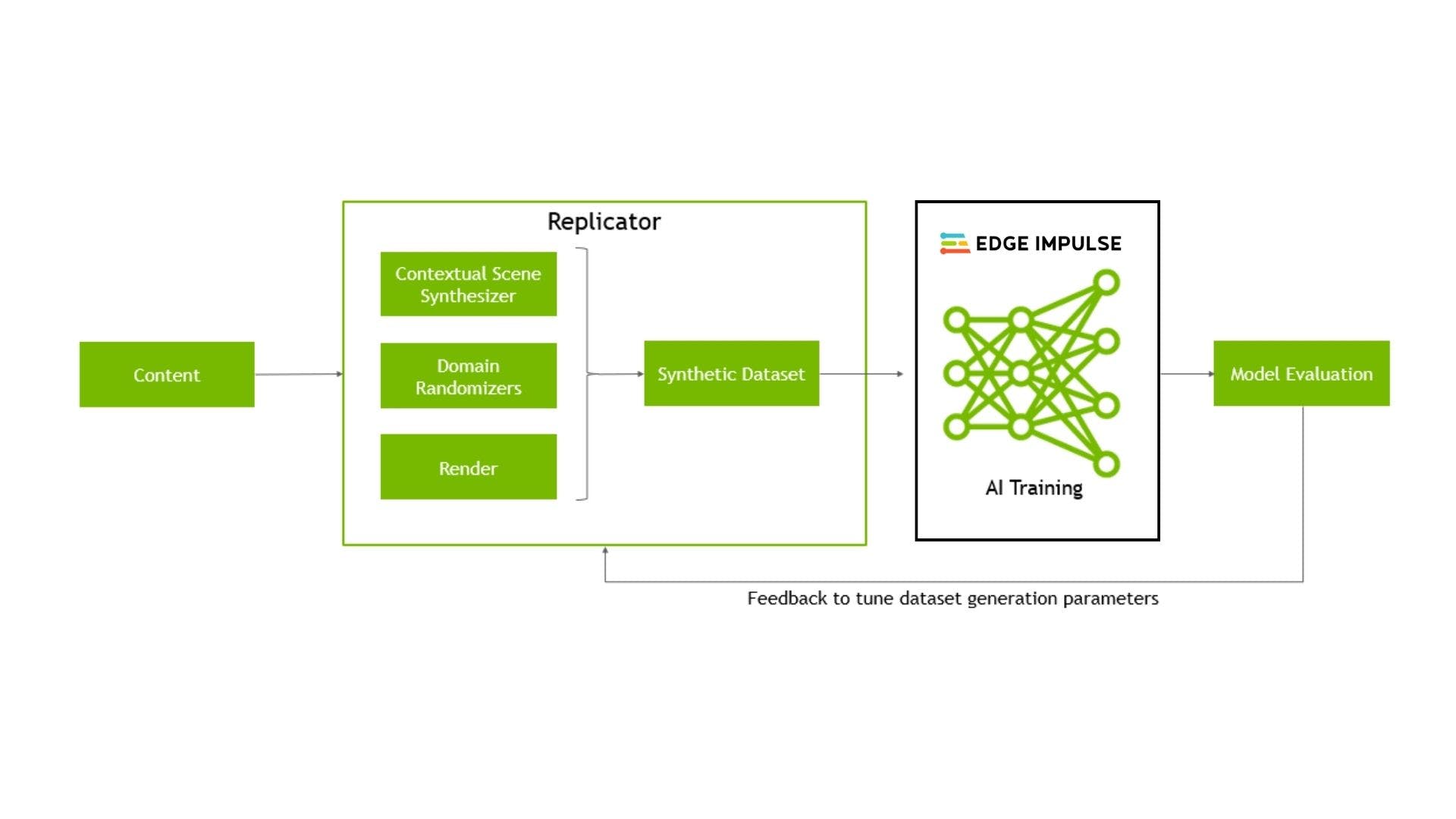
构建对象检测模型可能很棘手,因为它需要大型数据集。有时,数据可能很少或不够多样化,无法训练出稳健的模型。合成数据提供了一种替代方法,可以生成具有良好代表性的数据集来构建质量模型。通过应用域随机化,我们开发了逼真的数据集,训练了神经网络,并使用真实数据集验证了模型。为了创建多样化的数据集,我们创建了各种具有随机属性的模拟环境:不断变化的光照条件、相机位置和材料纹理。我们还表明,合成的随机数据集可以帮助推广模型以适应现实环境。
描述
我们想复制Louis Moreau 的物体检测工作,但这次使用合成数据而不是真实数据。该项目旨在演示如何使用 Nvidia Omniverse Replicator 生成的合成数据集构建和部署 Edge Impulse 对象检测模型。Replicator 是 Nvidia Omniverse 的扩展,它提供了生成物理上准确的合成数据的方法。
为什么要合成数据?
分类、对象检测和分割等计算机视觉任务需要大规模数据集。从一些现实世界的应用程序中收集的数据往往范围狭窄且多样性较低,通常是从单一环境中收集的,有时是不变的并且在大多数时间保持不变。此外,从单一领域收集的数据往往具有较少的尾端场景和罕见事件的示例,我们无法轻易地将这些情况复制到现实世界中。
因此,在单个域中训练的模型很脆弱,并且在部署到另一个环境时经常会失败;因此,它需要另一个训练周期来适应新环境。这就提出了一个问题,我们如何才能有效且廉价地跨多个领域收集广义数据?一个简单但不合理的有效解决方案是Domain Randomization,改变前景物体的纹理和颜色,背景图像,场景中的灯光数量,灯光的姿态,相机位置等。Domain randomization可以进一步提高模拟器中生成的罕见事件的合成数据结构的可变性。
“域随机化的目的是在训练时提供足够的模拟可变性,以便在测试时模型能够推广到真实世界的数据。” - Tobin 等人,用于将深度神经网络从模拟转移到现实世界的域随机化,2017 年
Nvidia Replicator 使我们能够执行域随机化。Replicator 是 Omniverse 系列中的一个模块,它提供工具和工作流程来为各种计算机视觉和非视觉任务生成数据。Replicator 是一种高度互操作的工具,可与 40 多个不同垂直领域的建模/渲染应用程序集成。由于 Pixar 的通用场景描述 (USD),无缝集成成为可能,它作为 Blender、3DMax、Maya、Revit、C4D 等各种应用程序的协议,与 Nvidia Replicator 一起工作。
以数据为中心的工作流程
传统的机器学习工作流程往往以模型为中心,通过迭代改进算法设计等更多地关注模型的开发。在这个项目中,我们选择了以数据为中心的方法,我们固定模型并迭代提高生成的质量数据集。这种方法更加稳健,因为我们知道我们的模型与数据集一样好。因此,该方法系统地改变了 AI 任务的数据集性能。它的核心是从数据而非模型的角度考虑机器学习。
硬件和驱动程序设置
Nvidia Omniverse Replicator 是一个计算密集型应用程序,需要中等大小的 GPU 和不错的 RAM。我的硬件设置包括 32GB RAM、1TB 存储空间和 8GB GPU 以及 Intel i9 处理器。
该应用程序可以在 Windows 和 Linux 操作系统上运行。对于这个实验,我们使用了 Ubuntu 20.04 LTS 发行版,因为从 2022 年 11 月起 Nvidia Omniverse 不再支持 Ubuntu 18.04。此外,我们选择了合适的 Nvidia 驱动程序 v510.108.03 并将其安装在 Linux 机器上。

实验设置和数据生成
实验环境由可移动和不可移动的物体(动态和静态定位物体)组成。不可移动的物体由灯、一张桌子和两个相机组成。同时,可移动的物体是餐具,即勺子、叉子和刀子。我们将使用域随机化来改变一些可移动和不可移动物体的属性。包括对象和场景的资产在 Replicator 中表示为 USD。

Omniverse Replicator 中的每个对象都以美元表示。可以使用 Nvidia Omniverse 的 CAD Importer 扩展将具有不同扩展名(例如 obj、fbx 和 glif)的 3D 模型文件导入 Replicator。该扩展程序将 3D 文件转换为美元。我们通过指定资产路径将我们的资产(桌子、刀、勺子和叉子)导入到模拟器中。
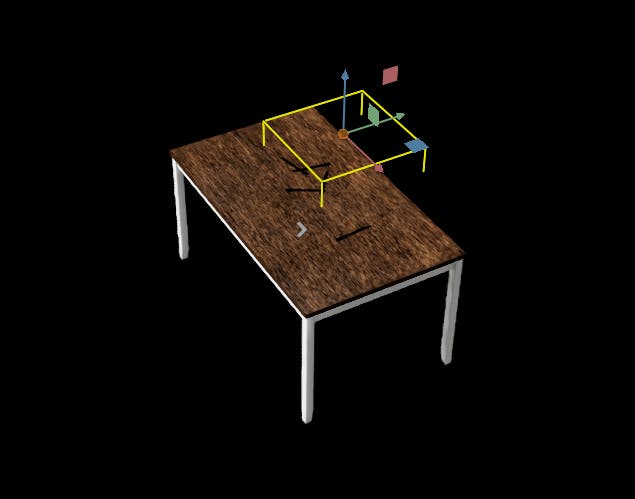
闪电在数据生成中起着至关重要的作用。Nvidia 复制器中有不同的内置照明类型。我们选择两个矩形灯和一个圆顶灯,因为它们为我们提供了更好的照明选项和生成逼真图像的能力。矩形灯模拟面板产生的光,圆顶灯让您动态照亮整个场景。我们随机化了一些光参数,例如温度和强度,并且这两个参数都是从正态分布中采样的。此外,比例参数是从均匀分布中采样的,同时保持灯光的旋转和位置固定。
# Lightning setup for Rectangular light and Dome light
def rect_lights(num=2):
lights = rep.create.light(
light_type="rect",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(0, 5000),
position=(-131,150,-134),
rotation=(-90,0,0),
scale=rep.distribution.uniform(50, 100),
count=num
)
return lights.node
def dome_lights(num=1):
lights = rep.create.light(
light_type="dome",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(0, 1000),
position=(0,0,0),
rotation=(270,0,0),
count=num
)
return lights.node
我们固定位置和旋转,选择桌面材料,选择额外的桃花心木材料,并在数据生成过程中交替使用材料。
# Import and position the table object
def table():
table = rep.create.from_usd(TABLE_USD, semantics=[('class', 'table')])
with table:
rep.modify.pose(
position=(-135.39745, 0, -140.25696),
rotation=(0,-90,-90),
)
return table
为了进一步提高我们数据集的质量,我们选择了两个不同分辨率的摄像机,我们将它们战略性地放置在场景中的不同位置。此外,我们在不同版本的数据生成过程中改变了摄像机的位置。
# Multiple setup cameras and attach it to render products
camera1 = rep.create.camera(focus_distance,focal_length,position,rotation...)
camera2 = rep.create.camera(focus_distance,focal_length2,position,rotation...)
# Will render 1024x1024 images and 512x512 images
render_product = rep.create.render_product(camera1, (1024, 1024))
render_product2 = rep.create.render_product(camera2, (512, 512))
最后,对于可移动的物体,包括刀、勺子和叉子,我们确保这些物体只能在桌子的边界内平移。所以我们选择了一个边界位置,在这个位置上,对象会随着桌子平移和旋转。我们从均匀分布中采样位置和旋转,同时将每次迭代生成的可移动对象的数量保持为五个。
# Define randomizer function for CULTERY assets.
def cutlery_props(size=5):
instances = rep.randomizer.instantiate(rep.utils.get_usd_files(knife), size=size, mode='point_instance')
with instances:
rep.modify.pose(
position=rep.distribution.uniform((-212, 76.2, -187), (-62.)),
rotation=rep.distribution.uniform((-90,-180, 0), (-90, 180, 0)),
)
return instances.node
此时此刻,我们已经实例化了场景中的所有对象。我们现在可以运行随机化器在每个合成生成周期生成 50 张图像。
# Register randomization
with rep.trigger.on_frame(num_frames=50):
rep.randomizer.table()
rep.randomizer.rect_lights(1)
rep.randomizer.dome_lights(1)
rep.randomizer.cutlery_props(5)
# Run the simulation graph
rep.orchestrator.run()
为确保生成逼真的图像,我们切换到 RTX 交互(路径追踪)模式,该模式提供高保真渲染。
数据分发和模型构建
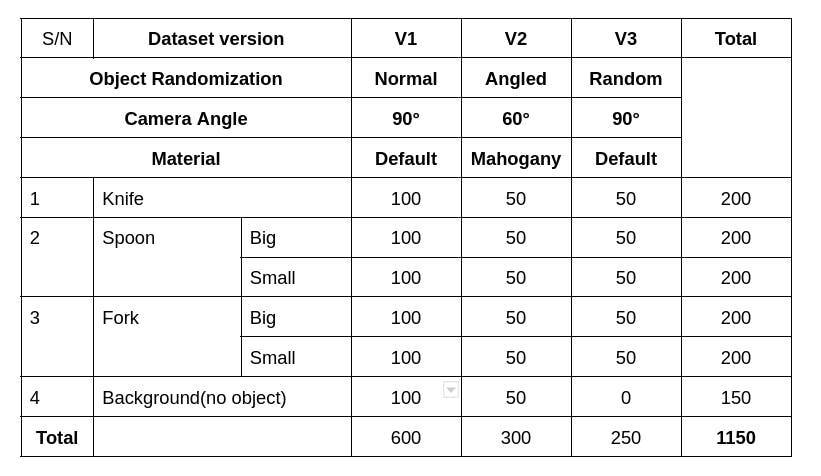
遵循以数据为中心的理念,我们生成了三个版本的数据集。第一个版本V1由垂直于相机位置的生成图像组成,而V2表示在桃花心木桌面上与相机位置成 60 度角生成的图像。V3包含垂直于相机位置的图像,同时餐具悬挂在空间中。




Edge Impulse:数据标注与模型构建
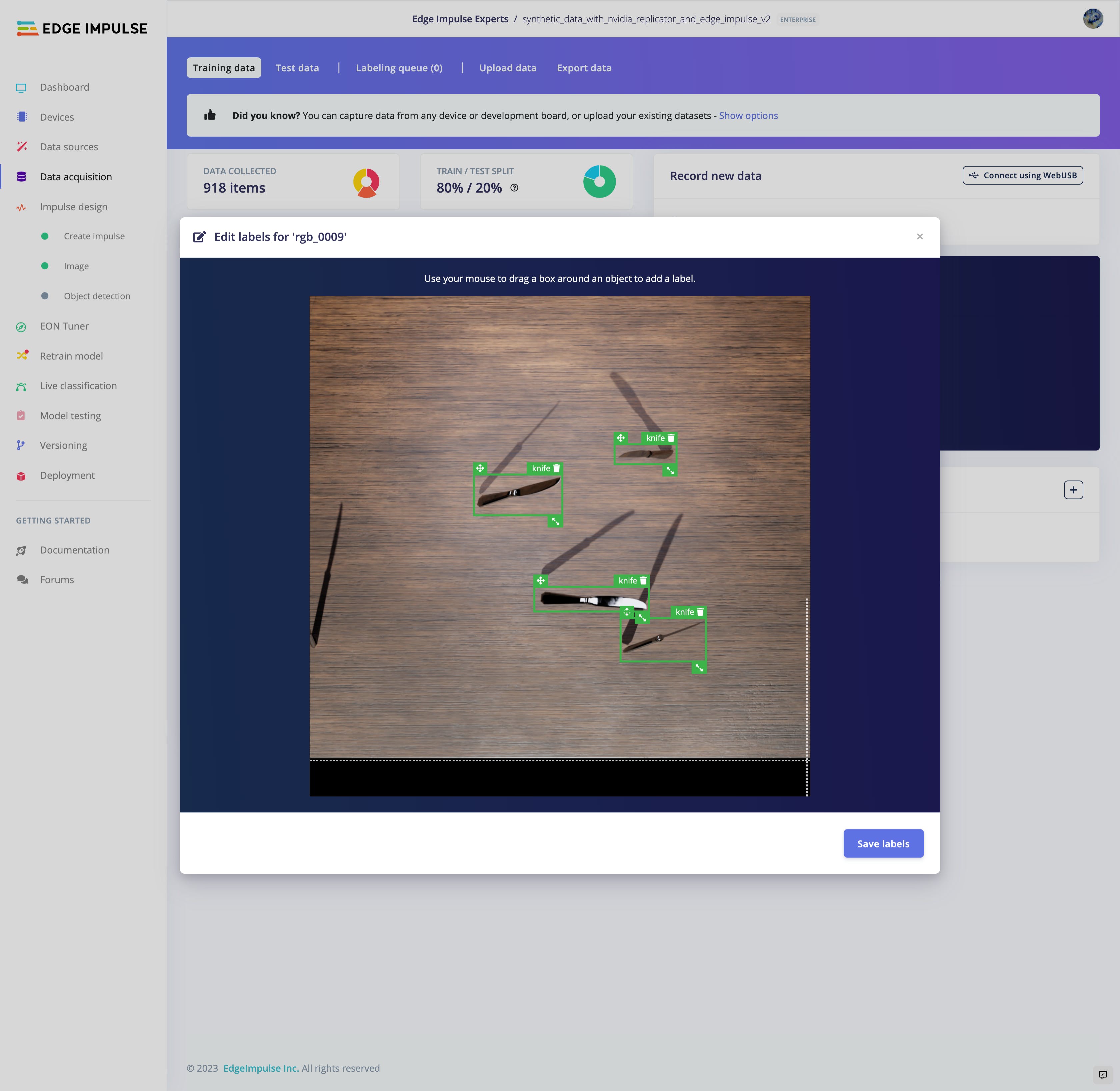
我们将生成的图像上传到 Edge Impulse Studio,我们在其中将数据集注释为不同的类。我们仔细注释了每个数据集版本,并使用Yolov5对象检测模型进行了训练。在确定为320之前,我们尝试了 320、512 和 1024 像素的几种输入尺寸。Edge Impulse 为模型提供了一个出色的版本控制系统,使我们能够跟踪不同数据集版本和超参数的模型性能。

用真实物体测试物体检测模型
我们使用 Edge Impulse CLI 工具通过在本地下载、构建和运行模型来评估模型的准确性。相机的位置在实验过程中保持固定。下面的片段显示经过训练的模型不能很好地泛化到真实世界的对象。因此,我们需要通过使用 V2 数据集上传、注释和训练模型来改进模型。
当使用 V2 数据集训练时,我们观察到模型性能有所提高。该模型可以清楚地识别各种物体,尽管当我们改变物体的方向时模型失败了。因此,我们使用剩余的 V3 数据集训练模型以缓解这些问题并增加其他超参数,例如从 500 到 2000 的纪元。我们还测试了我们的对象检测器在具有不同背景纹理的真实对象上的性能,模型表现良好在这些条件下。
在对各种超参数进行多次迭代之后,我们得到了一个可以很好地概括不同方向的模型。
解决 ML 问题的以数据为中心的方法背后的核心思想是围绕模型的故障点创建更多数据。我们通过迭代改进数据生成来改进模型,特别是在模型之前失败的区域。
结论
在这项工作中,我们了解了域随机化方法如何帮助为对象检测任务生成高质量和泛化良好的数据集。我们还展示了以数据为中心的机器学习工作流程在提高模型性能方面的有效性。虽然这项工作仅限于视觉问题,但我们可以将域随机化扩展到其他传感器,如激光雷达、加速度计和超声波传感器。
参考
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





