
资料下载


×
基于Spark机器学习工具来分析信用风险问题
消耗积分:1 |
格式:rar |
大小:0.17 MB |
2017-10-10
分享资料个
在本文中,我将向大家介绍如何使用Apache Spark的spark.ml库中的随机森林算法来对银行信用贷款的风险做分类预测。Spark的spark.ml库基于DataFrame,它提供了大量的接口,帮助用户创建和调优机器学习工作流。结合dataframe使用spark.ml,能够实现模型的智能优化,从而提升模型效果。
分类算法
分类算法是一类监督式机器学习算法,它根据已知标签的样本(如已经明确交易是否存在欺诈)来预测其它样本所属的类别(如是否属于欺诈性的交易)。分类问题需要一个已经标记过的数据集和预先设计好的特征,然后基于这些信息来学习给新样本打标签。所谓的特征即是一些“是与否”的问题。标签就是这些问题的答案。在下面这个例子里,如果某个动物的行走姿态、游泳姿势和叫声都像鸭子,那么就给它打上“鸭子”的标签。
我们来看一个银行信贷的信用风险例子:
我们需要预测什么?
某个人是否会按时还款这就是标签:此人的信用度
你用来预测的“是与否”问题或者属性是什么?
申请人的基本信息和社会身份信息:职业,年龄,存款储蓄,婚姻状态等等……这些就是特征,用来构建一个分类模型,你从中提取出对分类有帮助的特征信息。
决策树模型
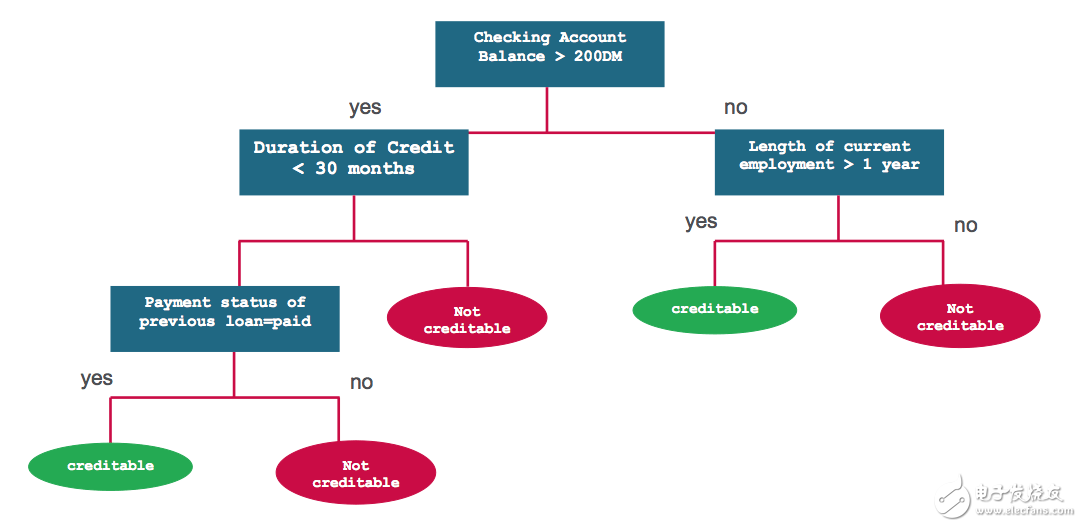
决策树是一种基于输入特征来预测类别或是标签的分类模型。决策树的工作原理是这样的,它在每个节点都需要计算特征在该节点的表达式值,然后基于运算结果选择一个分支通往下一个节点。下图展示了一种用来预测信用风险的决策树模型。每个决策问题就是模型的一个节点,“是”或者“否”的答案是通往子节点的分支。
问题1:账户余额是否大于200元?
否问题2:当前就职时间是否超过1年?
否不可信赖
随机森林模型
融合学习算法结合了多个机器学习的算法,从而得到了效果更好的模型。随机森林是分类和回归问题中一类常用的融合学习方法。此算法基于训练数据的不同子集构建多棵决策树,组合成一个新的模型。预测结果是所有决策树输出的组合,这样能够减少波动,并且提高预测的准确度。对于随机森林分类模型,每棵树的预测结果都视为一张投票。获得投票数最多的类别就是预测的类别。
分类算法
分类算法是一类监督式机器学习算法,它根据已知标签的样本(如已经明确交易是否存在欺诈)来预测其它样本所属的类别(如是否属于欺诈性的交易)。分类问题需要一个已经标记过的数据集和预先设计好的特征,然后基于这些信息来学习给新样本打标签。所谓的特征即是一些“是与否”的问题。标签就是这些问题的答案。在下面这个例子里,如果某个动物的行走姿态、游泳姿势和叫声都像鸭子,那么就给它打上“鸭子”的标签。
我们来看一个银行信贷的信用风险例子:
我们需要预测什么?
某个人是否会按时还款这就是标签:此人的信用度
你用来预测的“是与否”问题或者属性是什么?
申请人的基本信息和社会身份信息:职业,年龄,存款储蓄,婚姻状态等等……这些就是特征,用来构建一个分类模型,你从中提取出对分类有帮助的特征信息。
决策树模型
决策树是一种基于输入特征来预测类别或是标签的分类模型。决策树的工作原理是这样的,它在每个节点都需要计算特征在该节点的表达式值,然后基于运算结果选择一个分支通往下一个节点。下图展示了一种用来预测信用风险的决策树模型。每个决策问题就是模型的一个节点,“是”或者“否”的答案是通往子节点的分支。
问题1:账户余额是否大于200元?
否问题2:当前就职时间是否超过1年?
否不可信赖
随机森林模型
融合学习算法结合了多个机器学习的算法,从而得到了效果更好的模型。随机森林是分类和回归问题中一类常用的融合学习方法。此算法基于训练数据的不同子集构建多棵决策树,组合成一个新的模型。预测结果是所有决策树输出的组合,这样能够减少波动,并且提高预测的准确度。对于随机森林分类模型,每棵树的预测结果都视为一张投票。获得投票数最多的类别就是预测的类别。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



下载排行榜
- 暂无相关数据

