
资料下载


实例分析Schemaless的主要功能
分享资料个

本文介绍Schemaless的主要功能:Schemaless trigger的细节与案例。本文是系列文章的第三部分;第一部分是关于Schemaless的设计,第二部分是讨论其架构。
Schemaless trigger是一项具有可扩展性、容错性和无损性的技术,监听Schemaless实例中的变更。在行程(trip)流程中起到引擎的作用,从司机按下“结束行程”并向系统提交费用,直到相应数据进入数据库等待分析。在Schemaless系列的最后一篇中,我们将深入讲解Schemaless trigger的功能,以及如何开发出这个可扩展的容错系统。
简单来说,在Schemaless数据的基本单位被命名为单元(cell)。它是不可变的,一旦写入,便无法被覆盖。(在特殊情况下,我们可以删除旧记录);单元可以被行键(row key)、列名(column name)和引用键(ref key)来引用;单元内容通过编写引用键更高的新版来执行更新,但行键和列名保持不变。Schemaless不对其中存储的数据执行任何操作(故而命名schemaless)。从Schemaless的观点来看,它只负责存储JSON对象。
Schemaless Trigger案例
我们来看一下实践中Schemaless trigger的运作方式。下面的代码是简化版的异步计费方式(大写标注Schemaless的列名)。案例Python代码:
#我们实例化一个客户端,以便与Schemaless实例通讯schemaless_client = SchemalessClient(datastore=’mezzanine’) #为BASE列注册一个bill_rider功能@trigger(column=’BASE’)defbill_rider(row_key):# row_key是行程的UUIDstatus = schemaless_client.get_cell_latest(row_key, ‘STATUS’) ifstatus.is_completed: #也就是说我们已经提交了乘客的账单return#否则就尝试提交账单#我们从BASE列拿到了基本行程信息trip_info = schemaless_client.get_cell_latest(row_key, ‘BASE’) #提交乘客账单result = call_to_credit_card_processor_for_billing_trip(trip_info) ifresult != ‘SUCCESS’: #提交例外,让Schemaless trigger稍后重试。raiseCouldNotBillRider() #成功提交乘客账单,写入Mezzanineschemaless_client.put(row_key, status, body={‘is_completed’: True, ‘result’: result})
在Schemaless实例中,我们在函数中通过添加decorator@trigger来定义trigger,并指定列。如果指定列的单元中有内容,通知Schemaless trigger框架调用函数——本例是bill_rider。这里通过BASE中的一个新单元表明行程结束。触发trigger,然后通过函数来发送行键——本例是行程UUID。如果需要更多数据,必须从Schemaless实例——本例是从行程存储Mezzanine中获取真实数据。
bill_rider trigger函数的信息流见下表(这里是乘客结账)。箭头方向指明调用方与被调方,旁边的数字指明流程的顺序:
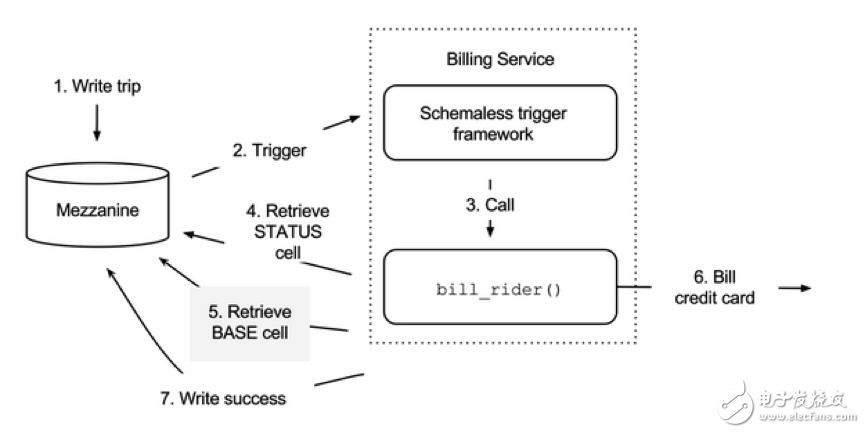
首先将行程输入Mezzanine,Schemaless Trigger框架调用bill_rider。在调用时,函数向行程存储请求STATUS列的最新信息。本例中is_completed字段不存在,也就是说乘客尚未结账。然后获得BASE列的行程信息,通过函数调用信用卡provider来结账。在本例中,我们成功用信用卡付费,并返回成功信息到Mezzanine,然后设置STATUS列的is_completed为True。
Trigger框架确保在每个Schemaless实例中的每个单元至少调用bill_rider一次。一般来说只触发trigger函数一次,不过在出错的情况下(无论是trigger功能还是其他功能短暂出错),都可能需要多次调用该函数。也就是说trigger函数是幂等的,在本例中要检查单元是否处理完毕。如果答案为是,则返回函数。
在查看下文中Schemaless如何在流程中提供支持时,要记得这个案例。我们将会解释Schemaless如何被看作变更日志,并讨论与Schemaless相关的API,分享让流程支持可扩展和可容错的技术。
将Schemaless视为日志
Schemaless包含所有单元,也就是说包含指定行键、列keypair的所有版本。由于包含单元的所有历史版本,除了随机访问key-value存储外,Schemaless还可作为变更日志。事实上它就是一个分区日志,每个分片都是自己的日志,如下图:
根据行键(也就是UUID)将每个单元写入特定的分片。分片中的所有单元都有唯一标识符,称为添加ID。添加ID是一个自动递增的字段,代表着单元的插入顺序(越新的单元,添加ID的数字越大)。除了添加ID之外,每个单元都有单元写入的时间(datetime)。在所有分片备份中,单元的添加ID是唯一的,这点对于故障时转移非常重要。
Schemaless的API支持随机访问和日志类访问。随机访问API是针对单独的单元,均由row_key、column_key和ref_key一同定义。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





下载排行榜
- 暂无相关数据

