
资料下载


×
嵌入式Linux系统中MMC卡驱动程序研究
消耗积分:1 |
格式:rar |
大小:0.3 MB |
2017-11-06
分享资料个
引 言
MMC(Multitmedia Card)是一种体积小巧、容量大、使用方便的存储器,目前在手机等嵌入式系统中有着广泛的应用。MMC通过卡内的一个集成片内控制器对MMC卡进行控制和管理,当主机正确地驱动MMC卡后,就可以像磁盘一样方便地存取数据。本文所研究与实现的Linux驱动程序,以Intel XScale的PXA250为硬件平台,在遵循MMC卡通信协议规范的基础上,实现了卡的底层读写。然后对传统的块设备驱动程序中的单块读写进行了改进,实现了集群读写技术,提高了卡的读写速度;同时增加了电源管理功能,满足了嵌入式系统低功耗的需求;增加了即插即用功能,方便了用户的使用。
1 MMC卡驱动程序的体系结构
MMC卡仅通过5个引脚与主机的控制器相连,通过串行协议与主机通信。MMC卡在硬件上的简单构造必然导致在实现驱动程序上的复杂。依据MMC卡的通信掷议规范和Linux驱动程序的结构,把驱动程序原有的底层驱动、守护线程、单块读写进行改进和扩展,其结构层次再划分为底层驱动、守护线程、集群读写、电源管理及热拔插管理5个部分,如图l所示。
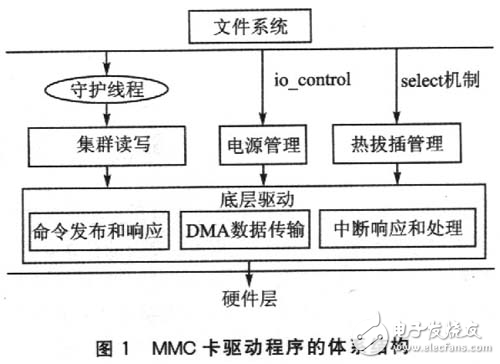
图1中各部分的功能为:
①底层驱动——处理直接涉及与MMC卡硬件寄存器端口的操作,包括:命令的发布和响应、中断响应和处理、PIO或者DMA通道数据传输等。
②集群读写——将磁盘相邻数据块的读写请求合并起来一起发布读写命令,以加快数据读写,并在读写中实现并发控制。
③电源管理——实现MMC卡的低功耗管理。
④热拔插管理——实现MMC卡的即插即用功能。
⑤守护线程——响应文件系统的读写请求并启动对卡的1/O。
2 MMC卡驱动程序的实现
2.1 底层驱动
底层驱动指的是直接对MMC卡进行操作。MMC卡采用串行的数据传输方式;是一种比较“精细”的卡,对它的操作比较复杂而且必须有准确的时序安排。以下从命令的发布和响应、中断响应和处理、DMA数据传输3个方面讲述如何进行底层读写驱动。
(1)命令发布和响应
MMC卡的操作是通过对其18个控制寄存器的读写实现的。首先,设置时钟起停寄存器MMC_STRCPL的最低两位为01.关闭MMC卡内部时钟。然后,设置中断屏蔽寄存器MMC_LMASK的最低7位都为1,屏蔽所有对MMC控制器的中断,再向指定的MMC控制寄存器中写入命令参数,如时钟频率设置寄存器MMC_CLKRT,读写块数寄存器MMC_NOB,命令寄存器MMC_CMD等。最后,打开内部时钟,解除屏蔽的中断。这时,当前读写进程进入睡眠状态,等待中断处理程序的唤醒。
(2)中断响应和处理
MMC卡在数据传输请求、内部时钟关闭、命令发布完毕、数据传输完毕的情况下都会产生中断,但足MMC卡的控制器只通过1裉GPIO23的引脚与CPU相连,用于中断信号线的复用;因此在中断处理程序中,必须首先判断到底是哪种原因产生的中断,然后再进行相应的处理。这里,MMC卡在正确发布读写命令以后,系统会产生1次中断,中断处理程序中读取MMC_IREG的值,判断命令已经发布成功,同时唤醒等待命令完成的进程。
读写进程被中断唤醒后,首先读取MMC卡响应寄存器MMC_RES中的状态信息,再根据这些状态信息判断命令是否发布成功和卡的当前状态。如果这些状态信息表示命令执行成功,则通过读写缓冲寄存器MMC_RXFIFO和MMC_TXFIFO进行数据的读写(这里使用DMA进行数据传输,提高了数据的传输速度);如果返回的状态信息表明命令执行不成功,则根据状念信息进行相应的出错处理。
(3)DMA数据传输
驱动程序中对MMC卡的数据读写是通过DMA通道进行传输的。为了保汪操作的连续性,驱动程序对MMC卡的输入和输出缓冲各设置1个DMA通道,在进行实际数据传输时,读写进程也进入睡眠状态,等待DMA数据传输完毕后,被DMA中断唤醒。实现一次读操作的伪代码如下:
Pxa_read_mmc(){
关闭时钟,屏蔽中断;
设置读写寄存器的内容; /*读写块数,起始块数,读写速度等*/
打开时钟,发布读写命令;
Interruptible_sleep_on(); /*进入可打断睡眠状态,等待中断程序的唤醒*/
被中断程序唤醒,打开DMA通道,进行数据传输,再次进入可打断睡眠状态;
被DMA传输完毕中断唤醒,发布结束传输命令,结束数据传输;
2.2 集群(clustering)读写和并发控制
2.2.1 传统的块设备驱动程序结构和不足
块没备驱动程序是Linux系统中最复杂的驱动程序之一,参阅文献[3,4]可以详细了解Linux块设备驱动程序。这里简单介绍与集群读写相关的数据结构和操作。扇区(seetor)是块设备硬件传输数据的基本单位,而块(block)是块设备请求1次I/O操作所涉及的一组相邻扇区,每个块都需要有自己的内存缓冲区。缓冲区首部(buffer_head)是与每个缓冲区相关的数据结构,每次对块没备的I/O传输都必须经过块的缓冲区。
Linux块没备驱动程序采取一种延迟I/O策略。当进程有I/O请求时,驱动程序延迟一段时间,把块设备上相连续的buffer_head结构关联在一起形成一个I/O请求描述符(struct request),再把request结构按照电梯算法排队到设备的请求队列(request_queue_t)。这样实际执行I/O传输时,顺次处理对应块设备的请求队列。
对于request结构的电梯排队算法,避免由于频繁的移动磁头而导致块设备性能下降;然而,目前在Linux块设备驱动程序中,对一个request结构中的
各个buffer_head结构分别发布I/O读写命令,会导致每次对一个buffer_head的输入/输出时,磁头都会停顿一段时间,进行DMA数据读写。这样频繁的磁头启停会导致磁盘性能下降。
2.2.2 集群读写的实现
传统的块设备驱动程序中每次发布读写命令都只对一个buffer_head缓冲而导致块设备性能下降。针对这一问题,我们对传统块设备进行改进,实现了集群读写。由于每一个request结构的buffer_head结构链对应的物理块都是相邻的,因此为进行集群读写创造了条件。request结构中的nr_sectors表示该request结构需要读写的块数。进行读写时,一次性发布读写块数为nr_seetors,读入块设备内容到requem结构指向的第一个buffer_head结构对应的内存区域。在一个buffer_head结构的缓冲区读写满了以后,就调整读写缓冲区地址为下一个buffer_head所指向的缓冲区,同时配合DMA进行数据传输,提高了读写速度。对一个request结构操作完成以后,释放request结构资源。实现集群读操作伪码如下:
Read_mmc(){
发布读写命令,读入的数据块数为一个rcquest一》nr_sectors的块数;
缓冲区的指针指向第1个bh结构所指的缓冲区;
while(数据还没有读完){
读入数据到buffer_head结构所指定的缓冲区;/*调用Pxa_read_mmc()*/
调整缓冲区的指针到下一个buffer_head结构所指向的缓冲区;
}
}
2.2.3集群读写中的并发控制
如果I/O请求队列request_queue_t是在内核中的许多地方都被访问的,则该队列就成为了临界资源。为了对该队列进行互斥保护,Linux2.4中所有的请求队列都受一个单独的全局自旋锁io_request_lock的保护。所有对清求队列的操作必须要求拥有该锁并禁止中断,然而,在驱动程序拥有这个锁的同时,其他任何读写请求不能排队到系统的任何块设备上,其他读写处理函数也不能运行。为了尽量减轻由于驱动程序长期的拥有该锁而导致系统性能下降的问题,在实现集群读写时必须遵循以下原则:
①对请求队列进行读写操作时要获得锁;
②对请求队列操作完毕后释放请求锁;
③为了减少占用锁的时间,可先把队列中的request结构从队列中取下来,再打开锁,然后在开锁的情况下对取下的request结构进行操作。
基于以上原则,读/写处理函数的伪码如下所示:
mmc_request_fn()
whilc(1){
加锁io_request_lock;
读取当前MMC卡请求队列的第一个请求结构request;
释放锁io_request_lock;
if(request为空)
cxit(O); /*没有可以处理的队列,返回*/
read_mmc(); /*调用集群读写函数*/
加锁io_request_lock;
在queue结构中取处理完毕的request结构,释放request资源;
释放锁io_request_lock;
}
}
2.3 守护线程
在MMC卡驱动程序初始化的时候,启动守护线程mme_block_thread。它平时处于睡眠状态,当有对MMC卡的读/写请求时,mmc_blok_thread被唤醒。该线程调用上述读/写处理函数mmc_request_fn(),处理完毕后再进入睡眠状态。
MMC(Multitmedia Card)是一种体积小巧、容量大、使用方便的存储器,目前在手机等嵌入式系统中有着广泛的应用。MMC通过卡内的一个集成片内控制器对MMC卡进行控制和管理,当主机正确地驱动MMC卡后,就可以像磁盘一样方便地存取数据。本文所研究与实现的Linux驱动程序,以Intel XScale的PXA250为硬件平台,在遵循MMC卡通信协议规范的基础上,实现了卡的底层读写。然后对传统的块设备驱动程序中的单块读写进行了改进,实现了集群读写技术,提高了卡的读写速度;同时增加了电源管理功能,满足了嵌入式系统低功耗的需求;增加了即插即用功能,方便了用户的使用。
1 MMC卡驱动程序的体系结构
MMC卡仅通过5个引脚与主机的控制器相连,通过串行协议与主机通信。MMC卡在硬件上的简单构造必然导致在实现驱动程序上的复杂。依据MMC卡的通信掷议规范和Linux驱动程序的结构,把驱动程序原有的底层驱动、守护线程、单块读写进行改进和扩展,其结构层次再划分为底层驱动、守护线程、集群读写、电源管理及热拔插管理5个部分,如图l所示。
图1中各部分的功能为:
①底层驱动——处理直接涉及与MMC卡硬件寄存器端口的操作,包括:命令的发布和响应、中断响应和处理、PIO或者DMA通道数据传输等。
②集群读写——将磁盘相邻数据块的读写请求合并起来一起发布读写命令,以加快数据读写,并在读写中实现并发控制。
③电源管理——实现MMC卡的低功耗管理。
④热拔插管理——实现MMC卡的即插即用功能。
⑤守护线程——响应文件系统的读写请求并启动对卡的1/O。
2 MMC卡驱动程序的实现
2.1 底层驱动
底层驱动指的是直接对MMC卡进行操作。MMC卡采用串行的数据传输方式;是一种比较“精细”的卡,对它的操作比较复杂而且必须有准确的时序安排。以下从命令的发布和响应、中断响应和处理、DMA数据传输3个方面讲述如何进行底层读写驱动。
(1)命令发布和响应
MMC卡的操作是通过对其18个控制寄存器的读写实现的。首先,设置时钟起停寄存器MMC_STRCPL的最低两位为01.关闭MMC卡内部时钟。然后,设置中断屏蔽寄存器MMC_LMASK的最低7位都为1,屏蔽所有对MMC控制器的中断,再向指定的MMC控制寄存器中写入命令参数,如时钟频率设置寄存器MMC_CLKRT,读写块数寄存器MMC_NOB,命令寄存器MMC_CMD等。最后,打开内部时钟,解除屏蔽的中断。这时,当前读写进程进入睡眠状态,等待中断处理程序的唤醒。
(2)中断响应和处理
MMC卡在数据传输请求、内部时钟关闭、命令发布完毕、数据传输完毕的情况下都会产生中断,但足MMC卡的控制器只通过1裉GPIO23的引脚与CPU相连,用于中断信号线的复用;因此在中断处理程序中,必须首先判断到底是哪种原因产生的中断,然后再进行相应的处理。这里,MMC卡在正确发布读写命令以后,系统会产生1次中断,中断处理程序中读取MMC_IREG的值,判断命令已经发布成功,同时唤醒等待命令完成的进程。
读写进程被中断唤醒后,首先读取MMC卡响应寄存器MMC_RES中的状态信息,再根据这些状态信息判断命令是否发布成功和卡的当前状态。如果这些状态信息表示命令执行成功,则通过读写缓冲寄存器MMC_RXFIFO和MMC_TXFIFO进行数据的读写(这里使用DMA进行数据传输,提高了数据的传输速度);如果返回的状态信息表明命令执行不成功,则根据状念信息进行相应的出错处理。
(3)DMA数据传输
驱动程序中对MMC卡的数据读写是通过DMA通道进行传输的。为了保汪操作的连续性,驱动程序对MMC卡的输入和输出缓冲各设置1个DMA通道,在进行实际数据传输时,读写进程也进入睡眠状态,等待DMA数据传输完毕后,被DMA中断唤醒。实现一次读操作的伪代码如下:
Pxa_read_mmc(){
关闭时钟,屏蔽中断;
设置读写寄存器的内容; /*读写块数,起始块数,读写速度等*/
打开时钟,发布读写命令;
Interruptible_sleep_on(); /*进入可打断睡眠状态,等待中断程序的唤醒*/
被中断程序唤醒,打开DMA通道,进行数据传输,再次进入可打断睡眠状态;
被DMA传输完毕中断唤醒,发布结束传输命令,结束数据传输;
2.2 集群(clustering)读写和并发控制
2.2.1 传统的块设备驱动程序结构和不足
块没备驱动程序是Linux系统中最复杂的驱动程序之一,参阅文献[3,4]可以详细了解Linux块设备驱动程序。这里简单介绍与集群读写相关的数据结构和操作。扇区(seetor)是块设备硬件传输数据的基本单位,而块(block)是块设备请求1次I/O操作所涉及的一组相邻扇区,每个块都需要有自己的内存缓冲区。缓冲区首部(buffer_head)是与每个缓冲区相关的数据结构,每次对块没备的I/O传输都必须经过块的缓冲区。
Linux块没备驱动程序采取一种延迟I/O策略。当进程有I/O请求时,驱动程序延迟一段时间,把块设备上相连续的buffer_head结构关联在一起形成一个I/O请求描述符(struct request),再把request结构按照电梯算法排队到设备的请求队列(request_queue_t)。这样实际执行I/O传输时,顺次处理对应块设备的请求队列。
对于request结构的电梯排队算法,避免由于频繁的移动磁头而导致块设备性能下降;然而,目前在Linux块设备驱动程序中,对一个request结构中的
各个buffer_head结构分别发布I/O读写命令,会导致每次对一个buffer_head的输入/输出时,磁头都会停顿一段时间,进行DMA数据读写。这样频繁的磁头启停会导致磁盘性能下降。
2.2.2 集群读写的实现
传统的块设备驱动程序中每次发布读写命令都只对一个buffer_head缓冲而导致块设备性能下降。针对这一问题,我们对传统块设备进行改进,实现了集群读写。由于每一个request结构的buffer_head结构链对应的物理块都是相邻的,因此为进行集群读写创造了条件。request结构中的nr_sectors表示该request结构需要读写的块数。进行读写时,一次性发布读写块数为nr_seetors,读入块设备内容到requem结构指向的第一个buffer_head结构对应的内存区域。在一个buffer_head结构的缓冲区读写满了以后,就调整读写缓冲区地址为下一个buffer_head所指向的缓冲区,同时配合DMA进行数据传输,提高了读写速度。对一个request结构操作完成以后,释放request结构资源。实现集群读操作伪码如下:
Read_mmc(){
发布读写命令,读入的数据块数为一个rcquest一》nr_sectors的块数;
缓冲区的指针指向第1个bh结构所指的缓冲区;
while(数据还没有读完){
读入数据到buffer_head结构所指定的缓冲区;/*调用Pxa_read_mmc()*/
调整缓冲区的指针到下一个buffer_head结构所指向的缓冲区;
}
}
2.2.3集群读写中的并发控制
如果I/O请求队列request_queue_t是在内核中的许多地方都被访问的,则该队列就成为了临界资源。为了对该队列进行互斥保护,Linux2.4中所有的请求队列都受一个单独的全局自旋锁io_request_lock的保护。所有对清求队列的操作必须要求拥有该锁并禁止中断,然而,在驱动程序拥有这个锁的同时,其他任何读写请求不能排队到系统的任何块设备上,其他读写处理函数也不能运行。为了尽量减轻由于驱动程序长期的拥有该锁而导致系统性能下降的问题,在实现集群读写时必须遵循以下原则:
①对请求队列进行读写操作时要获得锁;
②对请求队列操作完毕后释放请求锁;
③为了减少占用锁的时间,可先把队列中的request结构从队列中取下来,再打开锁,然后在开锁的情况下对取下的request结构进行操作。
基于以上原则,读/写处理函数的伪码如下所示:
mmc_request_fn()
whilc(1){
加锁io_request_lock;
读取当前MMC卡请求队列的第一个请求结构request;
释放锁io_request_lock;
if(request为空)
cxit(O); /*没有可以处理的队列,返回*/
read_mmc(); /*调用集群读写函数*/
加锁io_request_lock;
在queue结构中取处理完毕的request结构,释放request资源;
释放锁io_request_lock;
}
}
2.3 守护线程
在MMC卡驱动程序初始化的时候,启动守护线程mme_block_thread。它平时处于睡眠状态,当有对MMC卡的读/写请求时,mmc_blok_thread被唤醒。该线程调用上述读/写处理函数mmc_request_fn(),处理完毕后再进入睡眠状态。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





