
资料下载


几种隐私保护信息熵模型
分享资料个
隐私保护的研究起步较早,但近年来突然受到产业界和学术界的广泛关注,是因为大数据的不期而至.大数据的迅速发展让学术界始料未及,大数据的理论研究已经落后于产业需求,尤其是隐私保护成为了大数据应用的主要瓶颈,移动网络、社交网络、位置服务等新型应用的推进,使隐私问题更加突出.关于隐私保护目前有两个方向值得关注:一是研究更有效的隐私保护算法:二是研究隐私泄露风险分析与评估,以解决数据的可用性与隐私保护之问的平衡.隐私保护算法目前主要集中在匿名方法,包括K-匿名(K-anonymity)、三一多样性(三一diversity)匿名和t接近(t-close)匿名及其衍生的方法,隐私度量最早起源于相关匿名算法.在匿名隐私保护算法的研究中,不时有学者关注隐私量化问题,尤其是在定位服务领域,位置匿名和轨迹匿名算法已有不少涉及隐私度量的初步研究.然而隐私泄露涉及因素众多,设计有效的隐私保护算法仍然是挑战性问题.但政府及企业数据开放共享中迫切的隐私保护需求,促使我们不得不在可用性与隐私泄露之间寻求一种平衡.要解决这个问题,隐私风险分析及评估不失为一种可行解决方案.但隐私风险分析及评估,尤其是量仳隐私风险,势必会涉及隐私度量问题.从这些分析来看,隐私度量的研究具有十分重要的理论意义和应用价值.
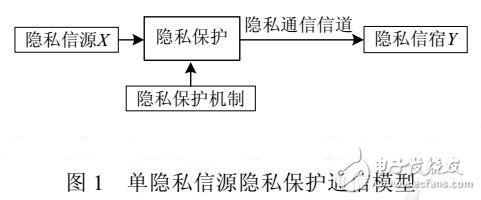
信息熵作为信息度量的有效工具,在通信领域已展现出其重要的贡献.隐私作为一种信息。自然可以考虑用熵来量化.为此,不少学者或多或少进行了探索,比如事件熵、匿名集合熵、条件熵等.但其研究还较为零散,更多地是针对某一特定领域,如位置隐私保护,目前还尚未形成统一的模型及体系.其应用范围也受到限制,特别是隐私是具有时空性的,与人的主观感受也有关系,不同的人对同一隐私的认同可能不同.鉴于以上分析,本文旨在参考Shannon信息论的通信框架,提出几种隐私保护信息熵模型,包括隐私保护基本信息熵模型、含敌手攻击的隐私保护信息熵模型、带主观感受的信息熵模型和多隐私信源的隐私保护信息熵模型.在这些模型中,将信息拥有者假设为发送方,隐私谋取者假设为接收方,隐私的泄露渠道假设为通信信道.基于这样的假设,分别引入隐私信息熵、平均互信息量、条件熵及条件互信息等来分别描述隐私保护系统信息源的隐私度量、隐私泄露度量、含背景知识的隐私度量及泄露度量.以此为基础,进一步提出了隐私保护方法的强度和敌手攻击能为的量化测评,力图为隐私泄露的量化风险评估提供一种理论支持.
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




