
资料下载


×
基于Hadoop的FP-Growth改进算法
消耗积分:1 |
格式:rar |
大小:1.06 MB |
2018-01-14
分享资料个
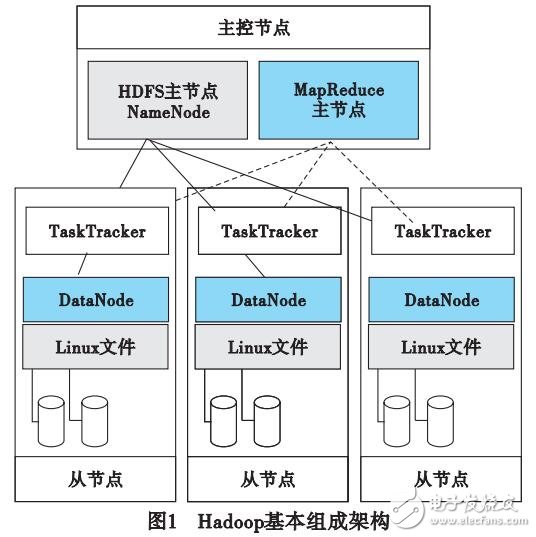
大数据环境下,传统的串行FP-Crowth算法在处理海量数据时,占用内存过大、频繁项多,适用于大数据情况的PFP( parallel FP-Crowth)算法存在数据量增大无法处理的缺陷。针对这些问题,提出了基于Hadoop的负载均衡数据分割FP-Growth并行算法。在Hadoop平台下,使用负载均衡和数据分割相结合的方式对原始事务数据集分片实现并行化。实验证明,基于Hadoop的负载均衡数据分割FP-Crowth并行算法在处理数据量和效率上有所提高。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

