
资料下载


婴幼儿语料库人工智能技术的详细中文资料概述
avsnest
分享资料个
人类婴儿由于出生时过于虚弱,不具备主动接近成人的行为能力,因此在9个月之前,其主要通过哭声吸引成人的注意,并向成人表达他的需求。婴幼儿语料库是按照一定采样标准采集的电子数据集合,随着大数据时代的到来,语音智能产品已经渗透到移动通信、智能家居、工业生产等很多领域。语音识别技术逐渐趋于成熟,然而,语音识别产品所依赖的语音数据价值变得更加显著,语料库成为重要的基础资源。独有核心技术,让AI更进一步。
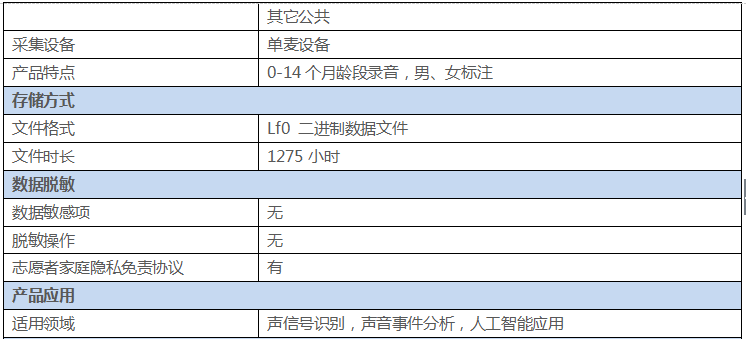
本语料库采集了近十六万条语音。录音采集人来自中国大陆各地,录制人数300多人,录制家庭300多家,采取0-14个月跟踪家庭录制,男女比例均衡,音频总时长1275小时,采集方式为单麦设备。每条音频单独存储为一个文件,并由专业标注人员手工进行两级标注。所有标注数据都是全检后再交付,以保证交付数据的质量。
随着以深度神经网络为代表的人工智能技术的发展,新一轮的人机交互技术热潮正在兴起。在机器视觉领域,由于海量图像和视觉场景数据库的诞生,催生了人脸识别、姿态识别、自动驾驶、无人机等领域的技术革新。目前世界上已有的典型的大规模海量图像和视觉场景数据库包括,ImageNet、MSCOCO等业界知名的数据库。
在声音场景和声音事件的识别领域,技术的发展已经成熟,然而商业应用滞后于机器视觉领域的应用。在声音领域,目前世界上最著名的音频数据库包括:欧洲的DCASE(声音场景和事件数据库)和谷歌的Audio Set(包括各类层次结构化的音频分类数据)等。
在家庭环境领域,能够用来服务于AI应用的声音数据极为缺乏,本产品旨在填补这一空白,为全球的智能家庭环境的AI应用落地做出贡献。
声音场景(Acoustic Scene)指的是室内、室外、火车站、餐厅、看电影、听音乐等实际生活中人们的有声的生活场景,通过声音信号的识别来辨识这类场景,就是声音场景识别;声音事件(Acoustic Event)指的是根据短时声学特征,利用统计学习的建模方法,对不同的声源所关联的事件,进行类别的分类。例如,对哭声、咳嗽声、脚步声,能够通过声音频率特征的分布规律,进行实时的检测,发现家居环境中的突发性事件、婴幼儿的行为事件、家庭成员的异常活动等。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





