
资料下载


如何使用多分形谱及特征来优选说话人识别系统的资料说明
分享资料个
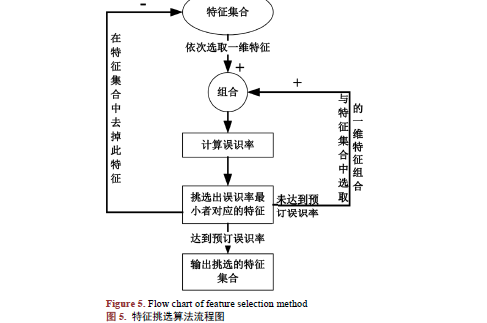
语音是复杂的非线性信号,这使得基于线性理论的传统说话人识别系统性能难以进一步提高。结合语音特点,基于小波极大模方法(Wavelet Transform Modulus-Maxima Method, WTMM),提出一种语音多分形谱特征(Multifractal Spectrum Feature, MSF)提取方法,并将语音多分形谱特征与传统特征结合用于说话人识别,实验表明,在短语音说话人识别中,6维MSF与LPC结合,误识率相比单独使用LPC降低了6.4个百分点;而MSF与MFCC、LPC组合,误识率降至1.2%左右。采用贪婪策略对说话人识别的特征进行优选,从101维特征中优选出13维特征用于识别,实验结果表明优选后的特征参数能有效降低系统误识率,提高识别速度,误识率最低降至1.6%,识别时间减少约86%。
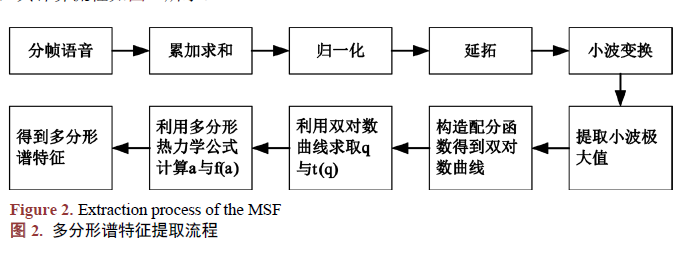
传统的语音信号处理是基于线性理论的,它基于这样一个假设,即当分段足够小时,非线性系统可以用线性系统来近似,但这种近似必然会损失一些有用的信息,使得基于线性理论的系统性能难以进一步提高。从声学和空气动力学角度看,语音信号既非确定性的,也非完全随机的,而是一个非线性过程,因而目前研究的注意力转向非线性信号分析方法,其中的一个方向就是用分形理论。本文尝试用多分形理论分析语音信号,从而在一定程度上弥补线性理论描述语音信号的不足,基于统计理论的GMM (Gaussian Mixture Model,高斯混合模型)模型在训练和识别时都需要充分的数据,才能达到较高的识别率,当进行短语音(2秒左右)说话人识别时,往往难以满足这一要求,为了从有限的数据中,提取出更丰富的信息,以增加模型的识别能力,我们引入了基于分形理论的说话人特征。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






