李飞飞等人ICLR2019论文构建人类眼睛感知评估(HYPE),带给你新的认知
CVPR 2019竞赛第一解决方案分享
3个神经网络,让蒙娜丽莎活起来
对抗性样本真的是不自然且无意义的吗?
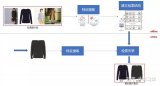
以图搜图背后的技术,你了解吗?
一种新型的GAN,在测试期间只需几张示例图像
一份深度学习“人体姿势估计”全指南,从DeepNet到HRNet
视觉系统的基础知识:关于摄像元件CCD
“位置/ 角度测量”是视觉检测的重要应用之一
基于GANs的新型自拍卡通化方法
解析你的手机是如何进行拍照的
前端不哭!最新优化性能经验分享
一个可以生成欺骗性补丁的系统模型,人们能够使自己在行人检测器中获得“隐身”的效果
OpenAl提出了一种适用于文本、图像和语音的稀疏Transformer
Facebook的研究人员提出了一个能从真实视频中抽取可控制主角的模型Vid2Game
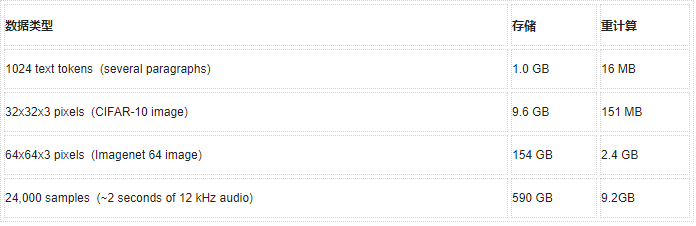
OpenAI新模型Sparse Transformer,预测长度超过去30倍
东京大学团队开源了一款名为「neural collage」的图像编辑工具
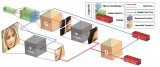
一个能通过空间条件坐标和隐变量生成图像片、并合成完整图片的网络模型
戴维斯分校提出实时分割框架YOLACT突破速度边界
多模态风格迁移——生成更加美丽动人的风格图像

 下载APP
下载APP
 搜索内容
搜索内容