PowerVR上的LLM加速:LLM性能解析
探索无限可能:生成式推荐的演进、前沿与挑战

TensorRT-LLM的大规模专家并行架构设计
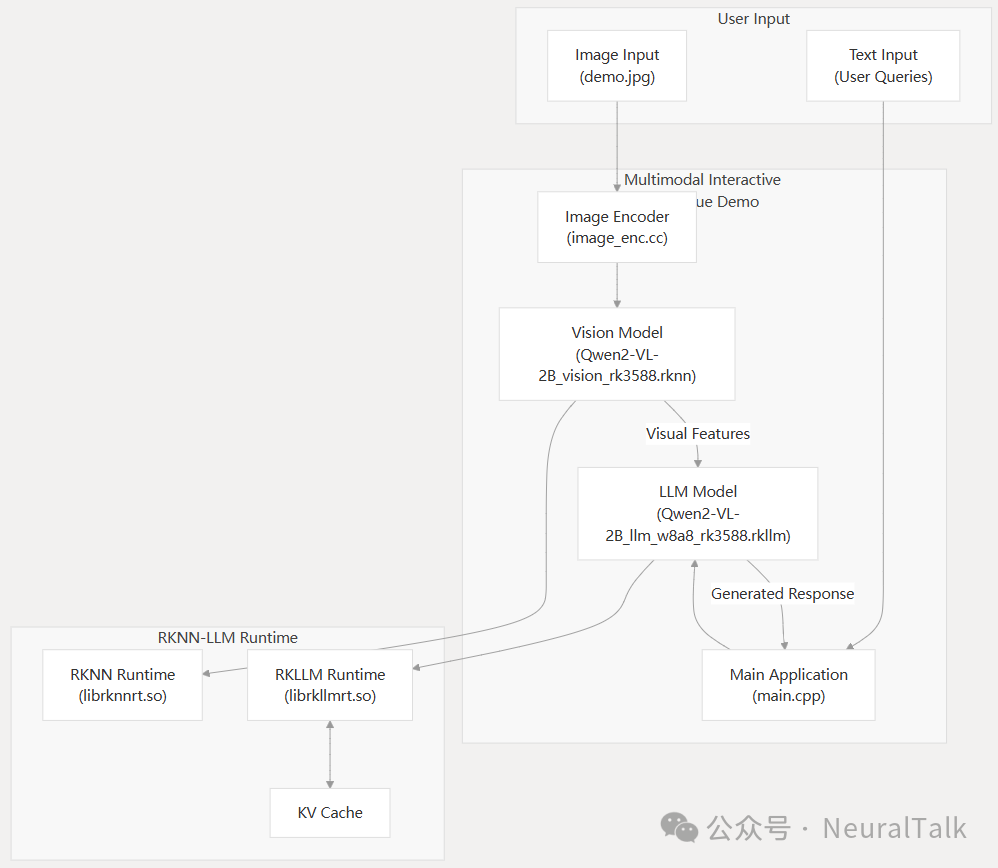
6TOPS算力驱动30亿参数LLM,米尔RK3576部署端侧多模态多轮对话
3万字长文!深度解析大语言模型LLM原理

DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

TensorRT-LLM中的分离式服务

AI生成的测试用例真的靠谱吗?
利用自压缩实现大型语言模型高效缩减

RK3568自制底板狂丢包?教你5分钟用Delayline一键复活网口

NVIDIA Blackwell GPU优化DeepSeek-R1性能 打破DeepSeek-R1在最小延迟场景中的性能纪录

使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践
LM Studio使用NVIDIA技术加速LLM性能
小白学大模型:从零实现 LLM语言模型
详解 LLM 推理模型的现状

树莓派秒变编程助手:Ollama+Continue的简易搭建教程!
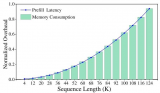
基于DBFP与DB-Attn的算法硬件协同优化方案

内部业务支撑&前瞻技术布局 One4All下一代生成式推荐系统
利用OpenVINO GenAI解锁LLM极速推理

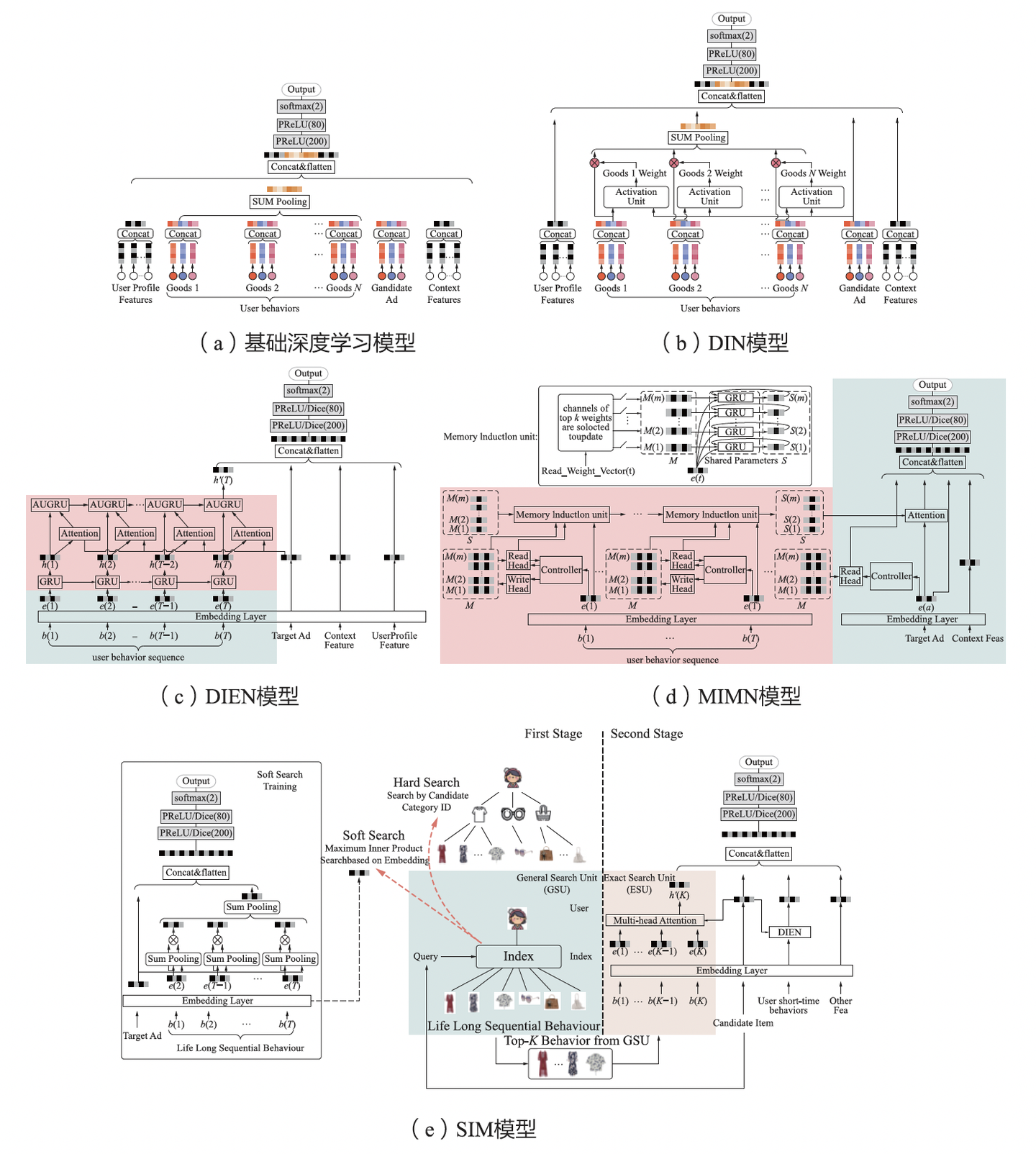
NVIDIA大语言模型在推荐系统中的应用实践

 下载APP
下载APP
 搜索内容
搜索内容