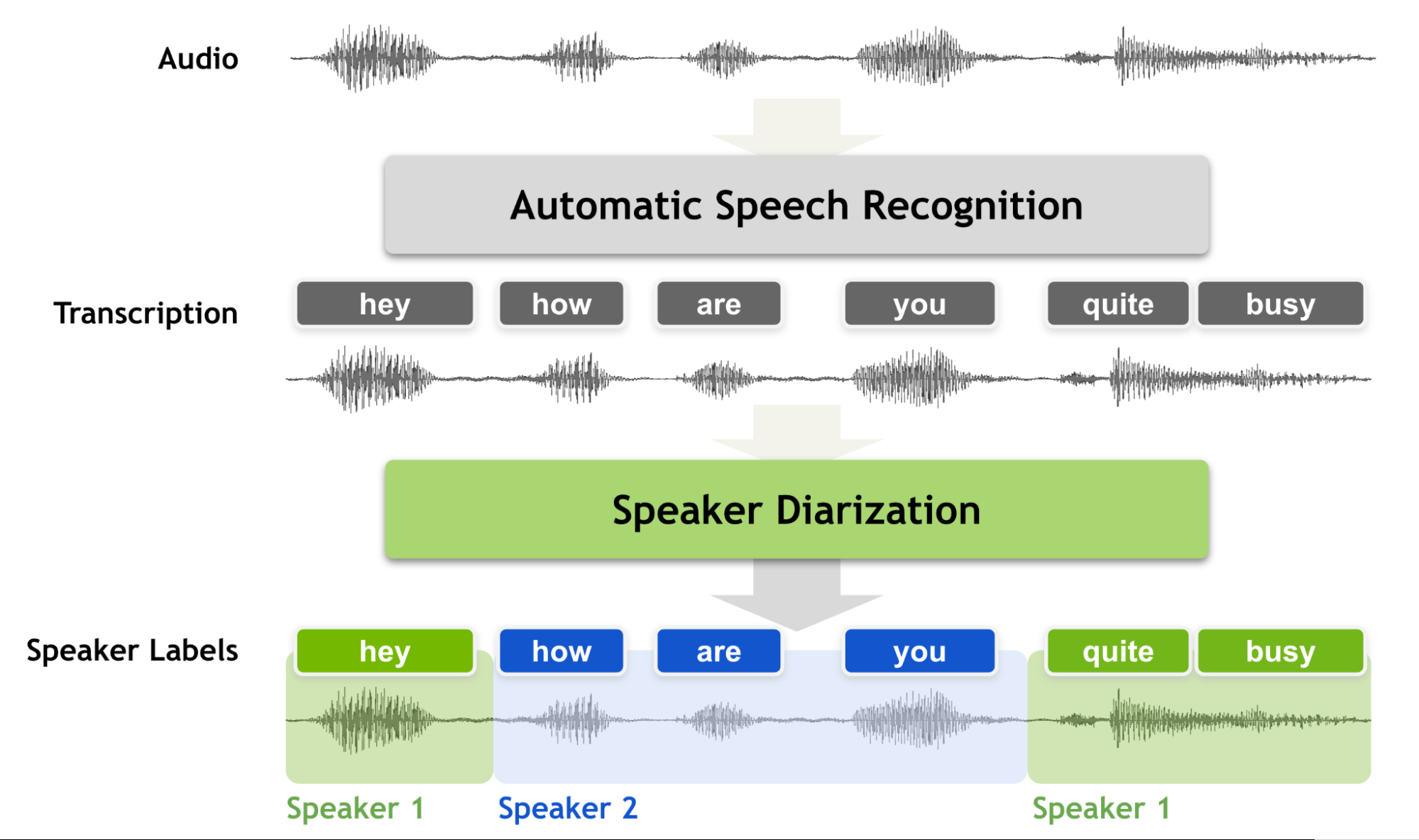
通过多尺度说话人分解实现动态尺度加权
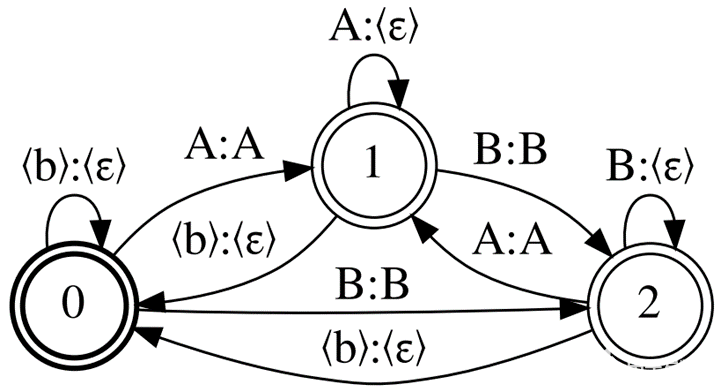
更改CTC规则以减少训练和解码中的内存消耗
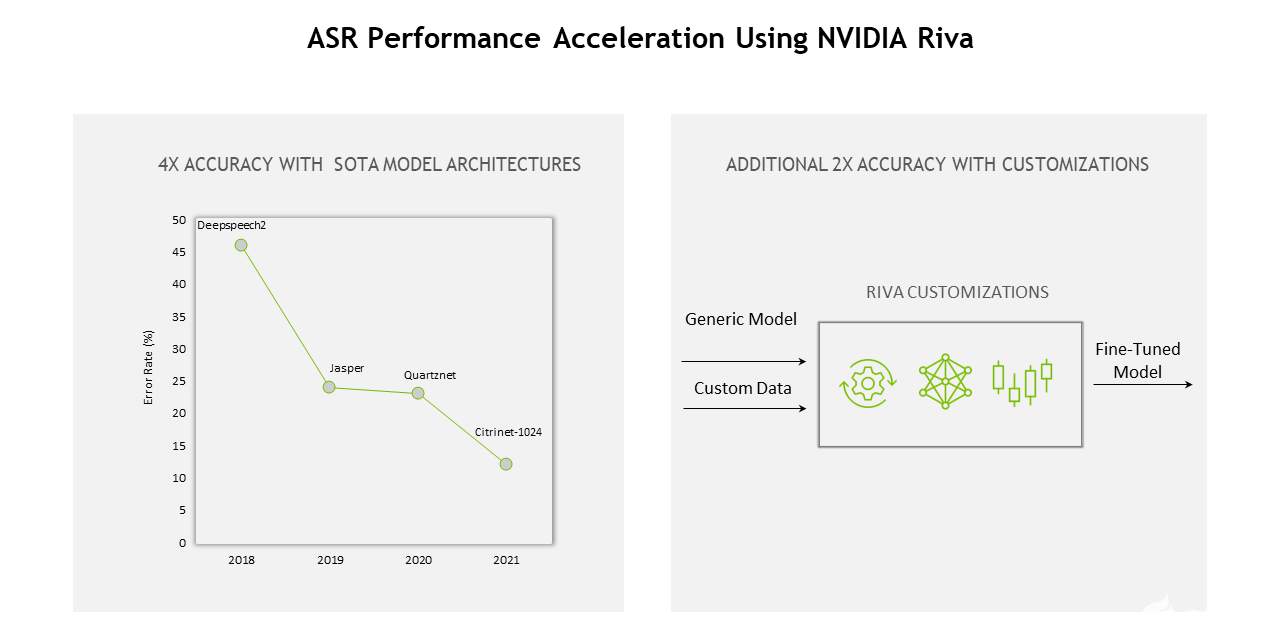
解决自动语音识别部署难题
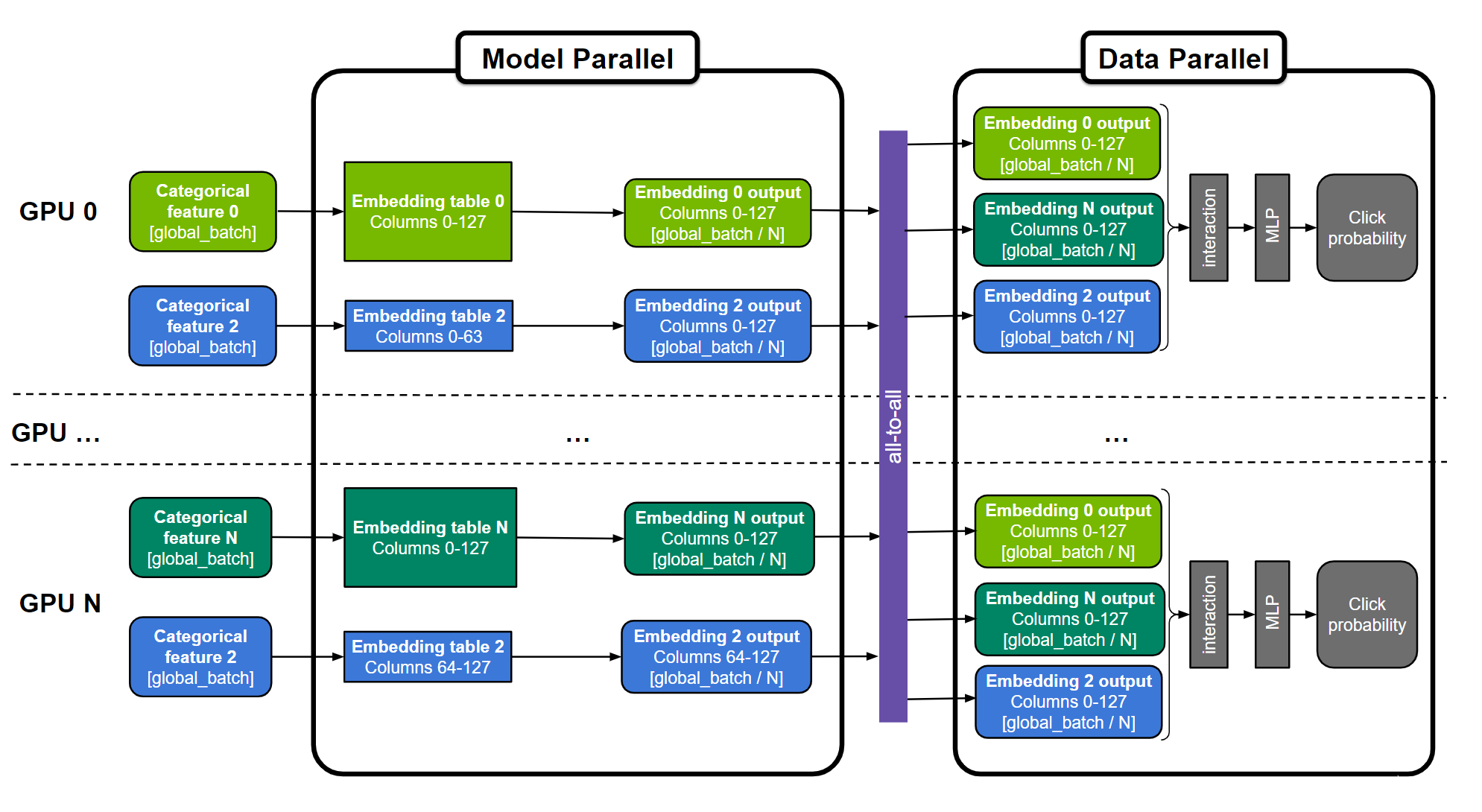
NVIDIA Merlin分布式嵌入使快速、TB级推荐培训变得简单
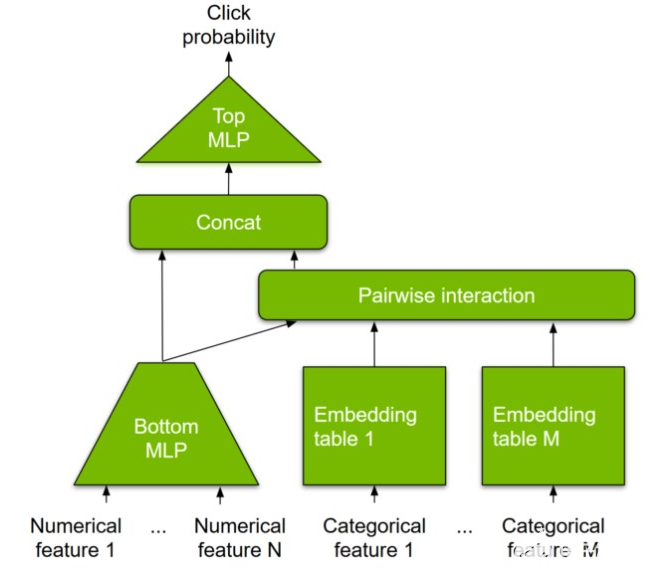
使用Merlin分层参数服务器扩展推荐系统推理
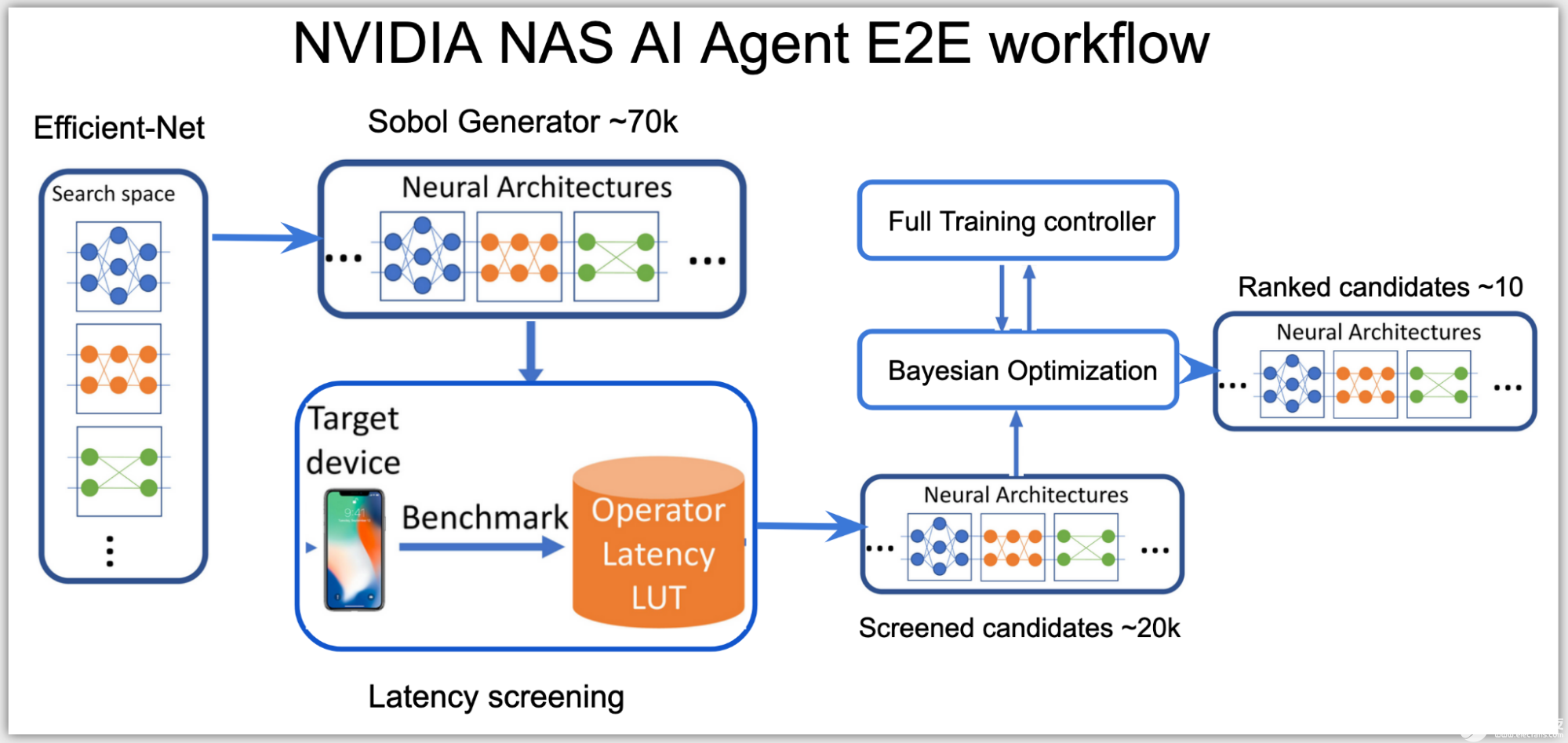
使用GPUNet在NVIDIA GPU上击败SOTA推理性能
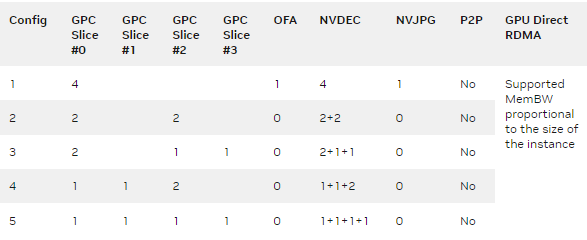
分割NVIDIA A30 GPU并征服多个工作负载

构造具有动态参数的CUDA图表
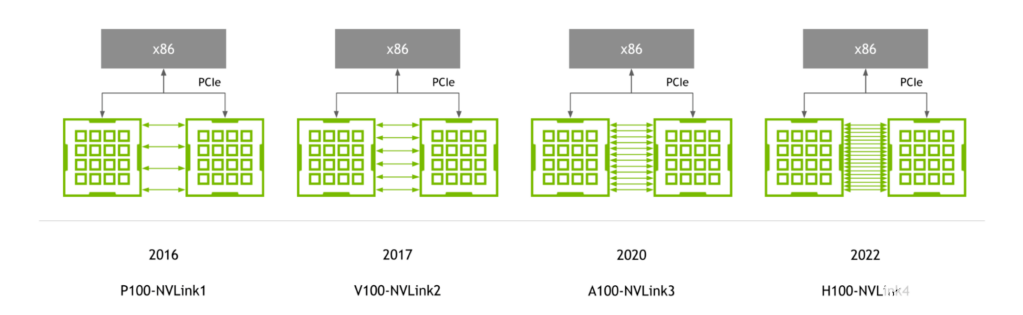
使用第三代NVIDIA NVSwitch升级多GPU互连
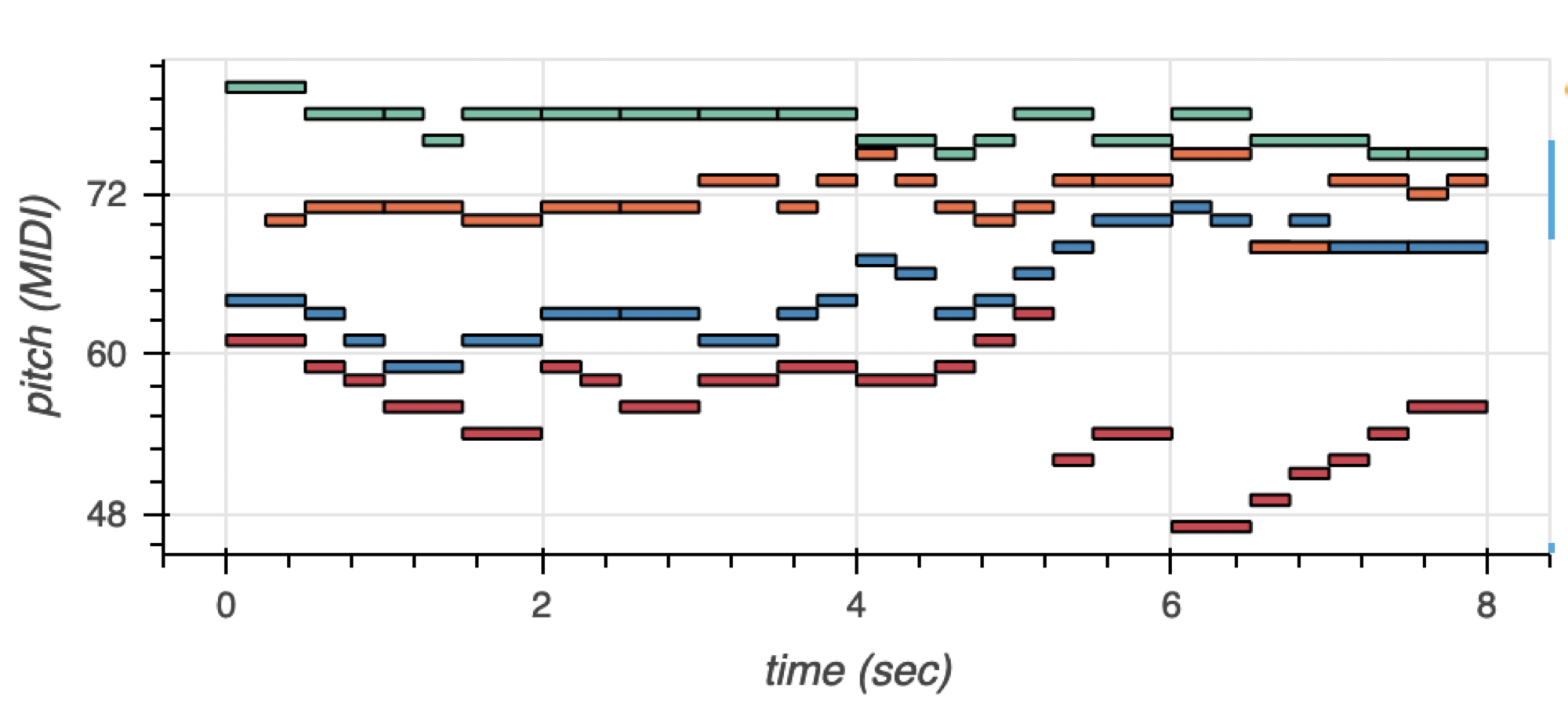
应用语言模型技术创作人工智能音乐
使用Memgraph和NVIDIA cuGraph算法运行大规模图形分析
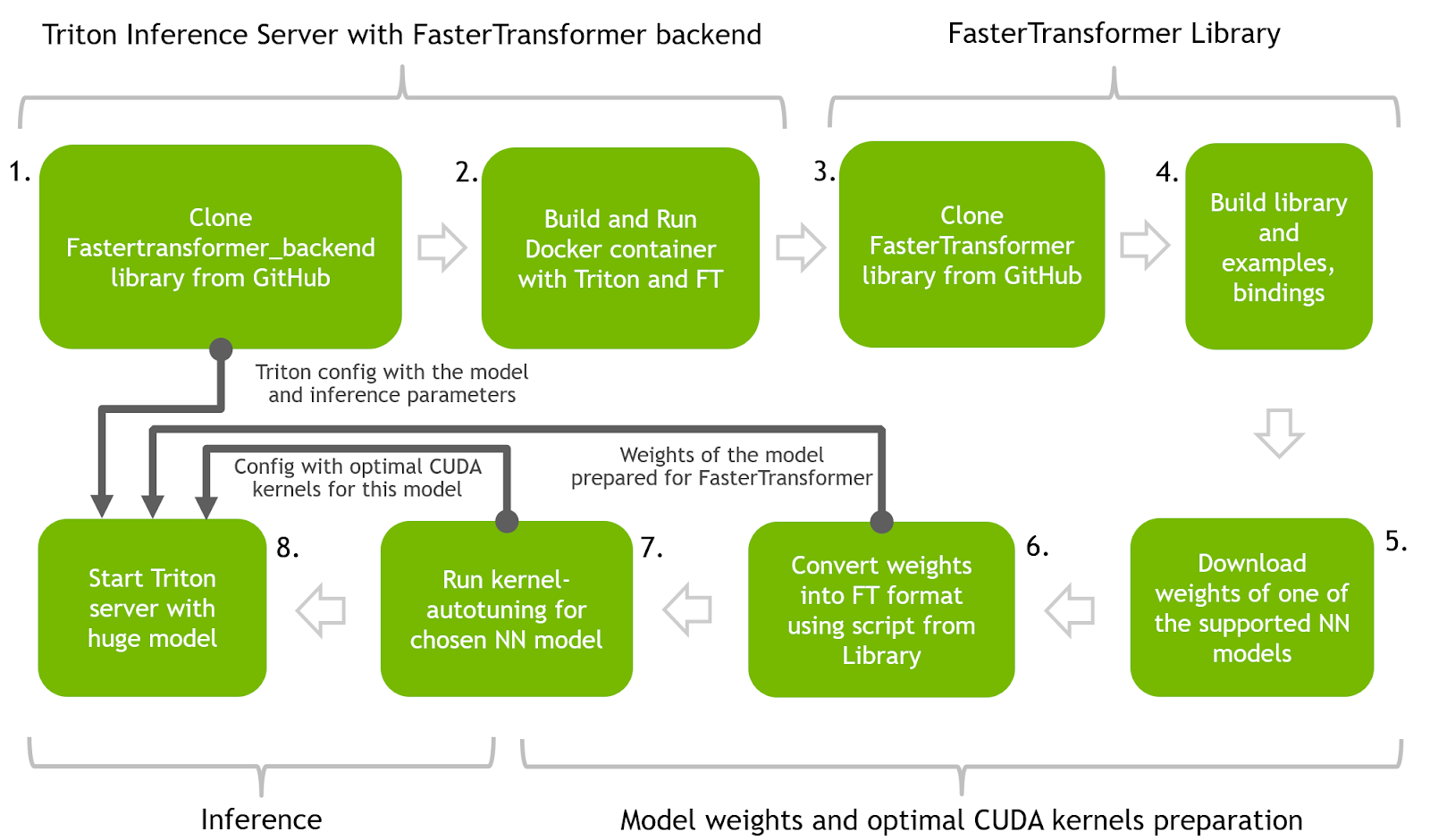
使用FasterTransformer和Triton推理服务器部署GPT-J和T5
使用NVIDIA Riva构建语音支持的人工智能虚拟助手
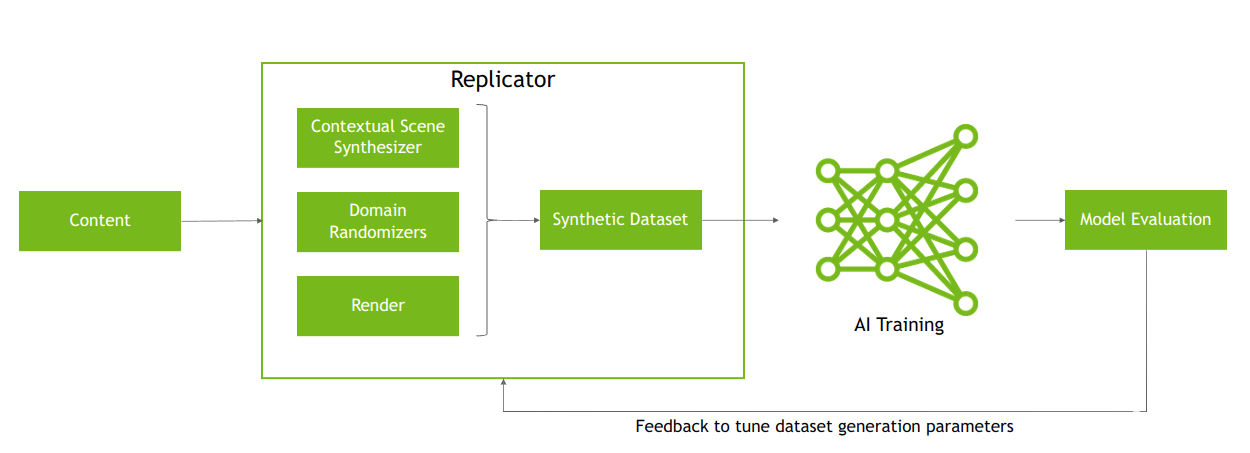
使用NVIDIA ISAAC Sim和NVIDIA ISAAC Replicator缩小Sim2Real差距
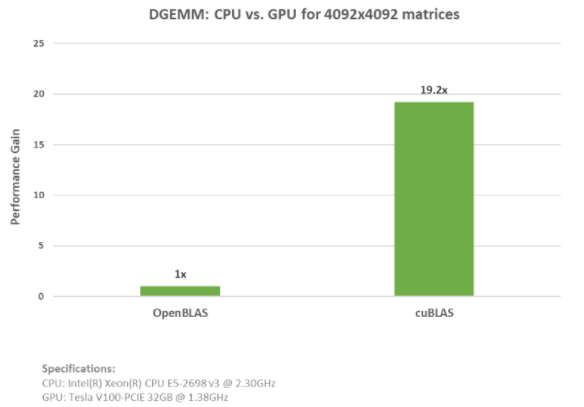
使用NVIDIA数学库加速GPU应用程序

使用DirectX 12在分布式系统上的应用程序之间同步当前调用

在中国移动Bigcloud加速云原生应用
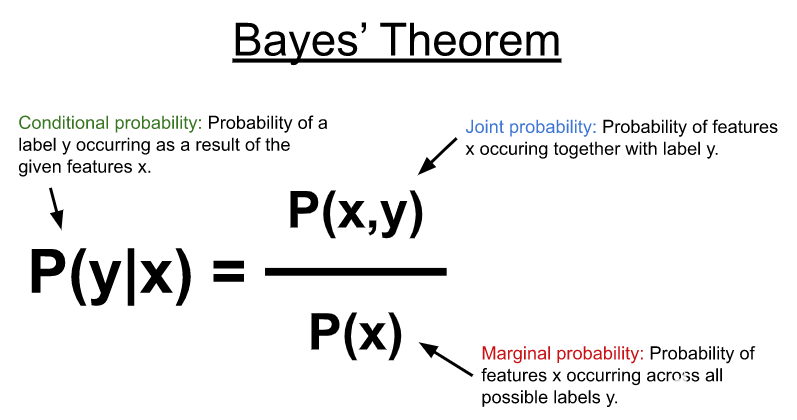
使用朴素贝叶斯和GPU进行更快的文本分类
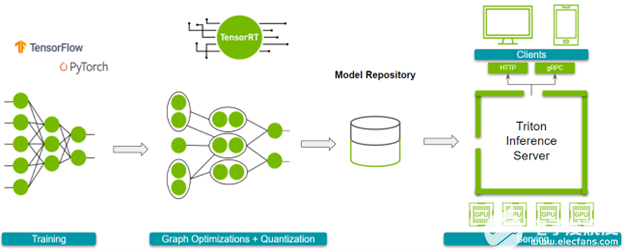
使用NVIDIA TensorRT和NVIDIA Triton优化和提供模型

利用深度强化学习设计算术电路

 下载APP
下载APP
 搜索内容
搜索内容