NVIDIA Omniverse实现多应用工作流程中的实时协作

科创板的一束“海光”,正在让中国半导体发展之路更清晰
模型有助于实现最大的运营效率
使用加速WEKA加速机器学习模型
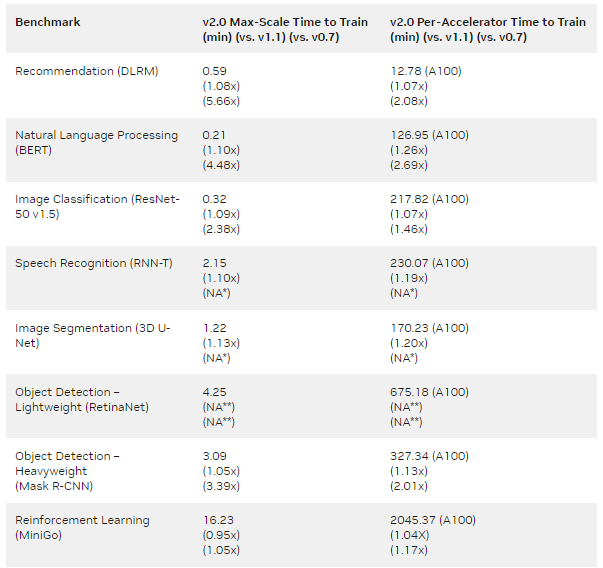
为NVIDIA MLPerf Training v2.0性能提供动力的全堆栈优化
通过GPU内存访问调整提高应用程序性能
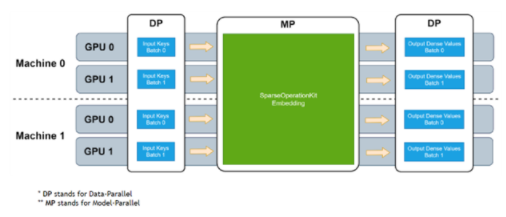
了解SOK的原理
MCM应用于GPU还需要多久
NVIDIA发布NeuralVDB 可将内存占用量减少高达100倍
量子处理单元(QPU)的定义及工作原理
壁仞科技发布首款通用GPU芯片 苹果智能指环专利曝光
芯动科技风华2号GPU与麒麟操作系统完成互认证
NVIDIA Studio技术如何加速创意工作流
NVIDIA Instant NeRF赢得SIGGRAPH最佳论文
IP平台支持云连接设备开发

GPU引擎增强了超声检测到的大脑运动计算
NVIDIA Jetson TX2 NX GPU助力微链DaoAI加速数据处理
NVIDIA发布Omniverse重要版本

摩尔定律为处理器创新让路
AI GPU计算在工厂车间提供数据中心性能

 下载APP
下载APP
 搜索内容
搜索内容