搜索内容
登录
爬虫
0人关注
在互联网领域,爬虫一般指抓取众多公开网站网页上数据的相关技术。目前,爬行是获取数据的主要方式。正如爬虫工作者所知,爬虫时IP很容易被封堵,这是因为有了反爬虫机制,所以才使用代理IP。
...展开
67
文章
1201
视频
36
帖子
6526
阅读
关注标签,获取最新内容
全部
技术
资讯
资料
帖子
视频
爬虫的基本工作原理 用Scrapy实现一个简单的爬虫
2023-12-03
489阅读
python的insert方法
2023-11-21
639阅读
Python 一个超快的公共情报搜集爬虫
2023-11-03
294阅读
crawlerdetect:Python 三行代码检测爬虫
2023-11-02
293阅读
feapder:一款功能强大的爬虫框架
2023-11-01
640阅读
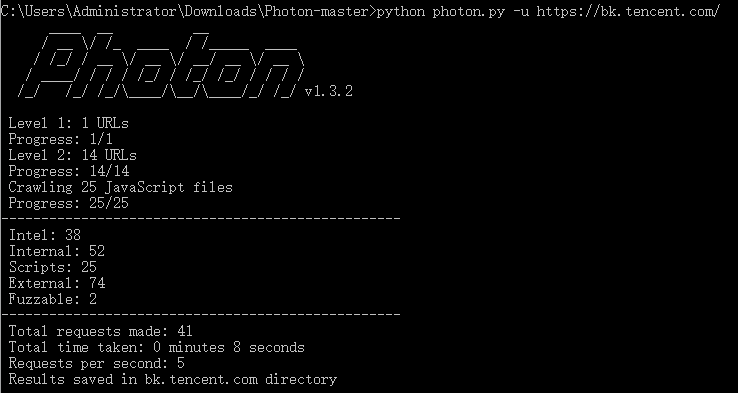
Photon:一个超快的公共情报搜集爬虫
2023-10-31
248阅读
新一代爬虫工具katana
2023-04-20
743阅读
python可以做什么?
2023-03-29
749阅读
基于Python的简便易用的数据接口
2023-03-10
555阅读
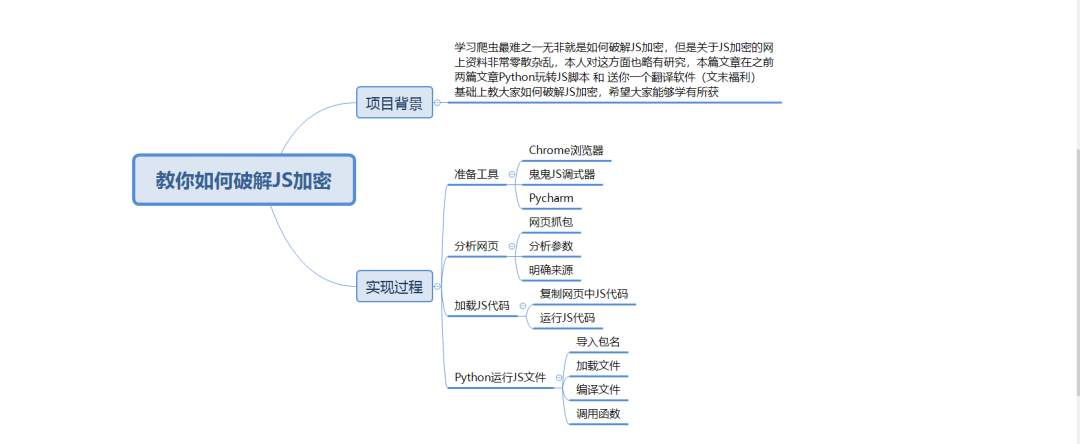
如何破解JS加密?
2023-02-24
1295阅读
爬虫的学习方法
2023-02-23
560阅读
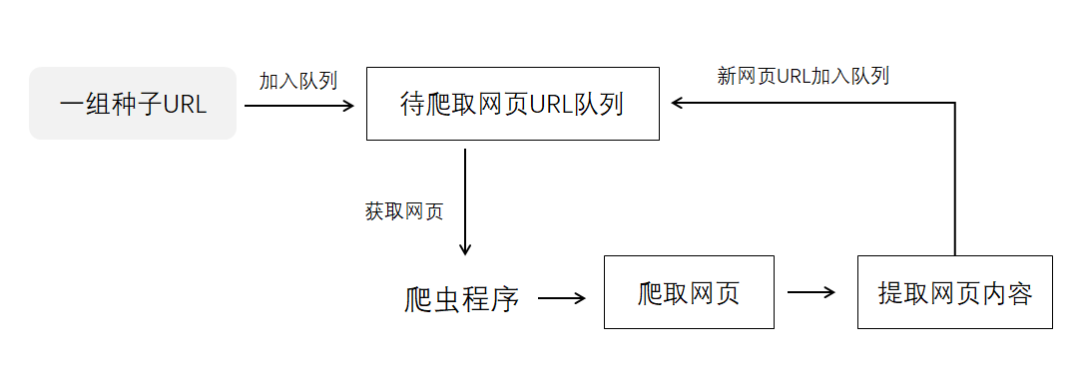
Python技术之爬虫的基本流程和原理
2022-12-14
946阅读
网页爬虫及其用到的算法和数据结构
2022-12-02
586阅读
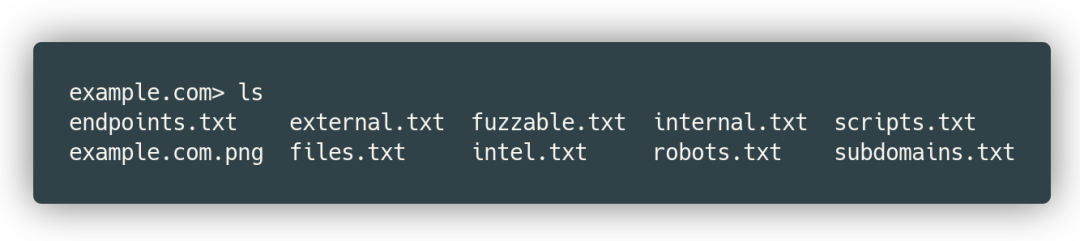
FOFA联动XRAY小工具:XRAY-F
2022-10-26
636阅读
用炫酷大屏展示爬虫数据!
2022-08-05
982阅读
反爬虫组件kk-anti-reptile的工作流程与使用方法
2022-07-14
1244阅读
Photon情报搜集爬虫的主要功能与安装使用说明
2022-06-23
857阅读
RuiJi Scraper可视化浏览器爬虫扩展
2022-05-19
216阅读
通过分析ajax中信息爬取图片
2022-03-23
1233阅读
豆瓣电影Top250信息爬取
2022-03-23
1939阅读
上一页
1
/
4
下一页
相关推荐
更多 >
IOT
海思
STM32F103C8T6
数字隔离
硬件工程师
wifi模块
74ls74
UHD
MPU6050
Protues
STC12C5A60S2
×
20
完善资料,
赚取积分


 下载APP
下载APP
 搜索内容
搜索内容