
资料下载


TVM学习(五)schedule
分享资料个
作者:安平博,Xilinx高级工程师;来源:AI加速微信公众号
Schedule是和硬件体系结构相关的一些列优化,Halide在其文章中对其做了以下定义:
1 When and where should be the value at each coordinate in each function be computed?
2 Where should they be stored?
3 How long are values cached and communicated across multiple consumers, and when are they independently recomputed by each?
第一条是描述了数据计算顺序对性能的影响,第二条是数据的存储位置对性能影响,最后一条是多线程处理过程中,不同线程数据应该如何进行交互。
参考文章:https://zhuanlan.zhihu.com/p/94846767,常用的shcedule有:
1 cache_read
将数据存储到片上缓存,减少访问数据时间。
2 cache_write
将结果写入片上缓存,然后再写入片外缓存。当然这里的片上和片外并不是绝对的概念,也可以理解为不同层次的存储结构。
3 set_scope
为数据指定存储位置,相比于cache_read和cache_write提供了更灵活的指定数据存储方式。本质上是相同的。
4 storage_align
在我看的文章中,storage_align是针对GPU shared memory的一个优化,目的是为了减少同一个bank的访问冲突。在GPU中shared memory被分割成多个bank,这些bank可以被独立线程同时访问。Storage_align就是为了将数据和bank大小匹配,减少bank conflict的发生。AI芯片中也有类似的问题,只有尽量减少bank冲突的发生,才能最大化并行计算。
5 compute_at
不懂CUDA,所以对文章中的代码不是很理解,但是从其解释看,对于多次循环的计算(或者多维计算),可以通过并行计算来降维。
6 compute_inline
将独立操作转化为内联函数,有点类似FPGA上的流水线计算。转化成内联函数从上层层面减少了stage。在FPGA中也有类似问题,可以将具有相同迭代的多条指令放在一起执行。
7 compute_root
Compute_at的反操作。
8 fuse
将多个循环iter融合为一个iter。
9 split
Fuse的反操作,将一次循环迭代拆分为多次。
10 reorder
调整循环计算迭代顺序。
11 tile
Tile也是将循环迭代进行拆分,拆分多次计算。是split+reorder。
12 unroll
将循环展开,增加并发执行。
13 vectorize
将循环迭代替换成ramp,可以通过SIMD指令实现数据批量计算,也就是单指令多数据计算。这在AI加速中会很常用,每条指令都是多数据计算的。
14 bind
CUDA中使用的优化方法,将iter绑定到不同线程,实现并发计算。
15 parallel
实现多设备并行.
16 pragma
可以在代码中人为添加编译注释,人为干预编译优化。HLS中就是通过这样的方式来实现c的硬件编程的。
17 prefetch
将数据计算和load后者store数据重叠起来,在FPGA中是很常见优化方法。
18 tensorize
将tensor作为一个整体匹配硬件的计算核心,比如一个卷积运算就可以实现在FPGA上的一个匹配。
文章https://zhuanlan.zhihu.com/p/166551011 是通过官网的一个例子来介绍schedule的。在这个例子中,首先利用te的节点表达式建立了计算函数,然后调用create_schedule来创建schedule实例,然后再调用lower函数实现schedule优化。代码如下:
# declare a matrix element-wise multiply A = te.placeholder((m, n), nam) B = te.placeholder((m, n), nam) C = te.compute((m, n), lambda i, j: A[i, j] * B[i, j], nam) s = te.create_schedule([C.op]) # lower will transform the computation from definition to the real # callable function. With argument `simple_mode=True`, it will # return you a readable C like statement, we use it here to print the # schedule result. print(tvm.lower(s, [A, B, C], simple_mode=True))
我这里依然延续上一章的内容,看代码中关于schedule的处理。
在上一章我们在codegen生成中,通过以下调用链转到了schedule的处理。Codegen -> VisitExpr(CallNode* op) -> relay.backend._CompileEngineLower -> LowerInternal。LowerInternal函数为:
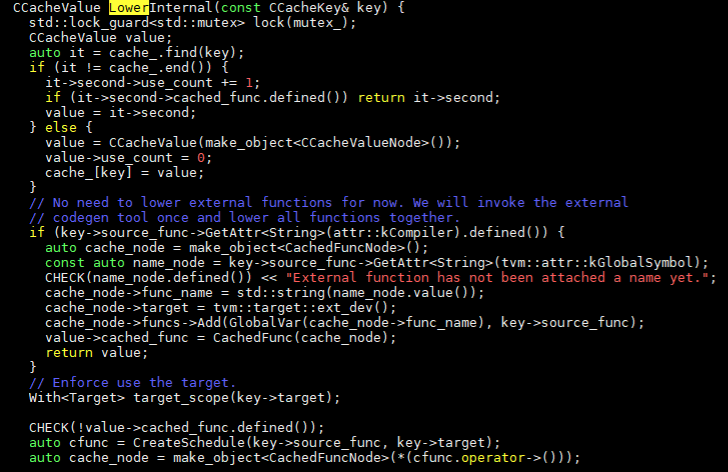
如果是外部定义的编译器,就只是建立cache_node节点和cache_func。如果是使用内部编译器,就会调用CreateSchedule建立schedule。接下来调用链为CreateSchedule -> ScheduleGetter.create -> te::create_schedule -> Schedule。create_schedule函数调用在文件re/schedule.h和te/schedule_lang.cc中。
create_schedule中主要有两件工作:
1 创建ReadGraph,获取post-dfs顺序的算符图。
2 初始化stage。
TVM中引入了stage的概念,一个op相当于一个stage,schedule优化是对stage的一个更改,可以增加,删减,更改其特性等。
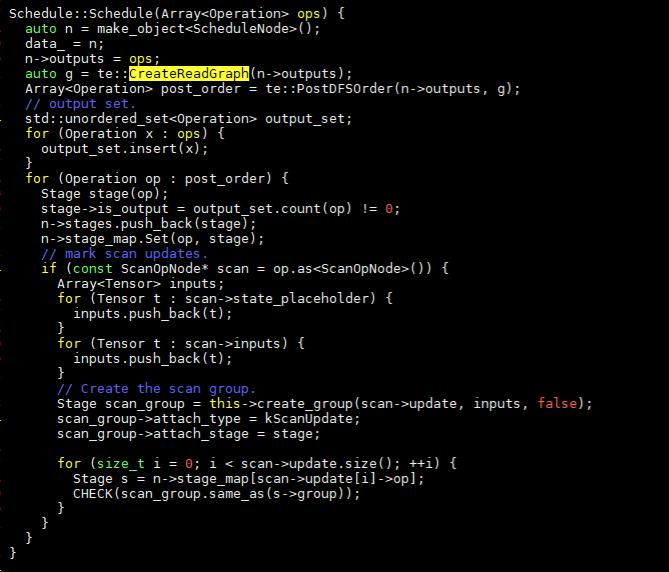
通过createReadGraph可以遍历op图,返回op和其依赖的tensor列表。和遍历有关的主要函数为:
Op -> InputTensors -> PostOrderVisit -> IRApplyVisit,在IRApplyVisit中定义了VisitExpr和VisitStmt函数用于遍历节点。
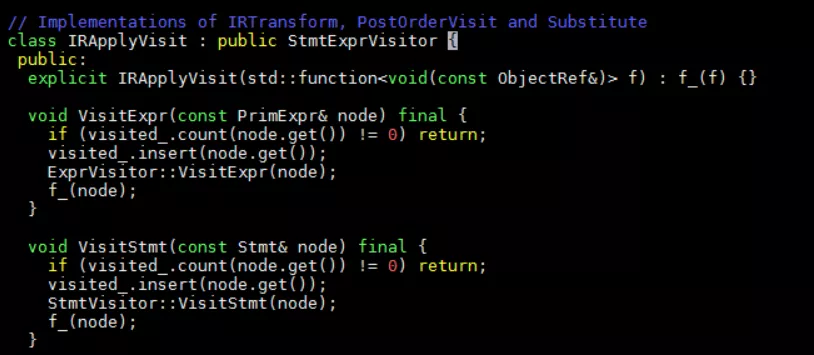
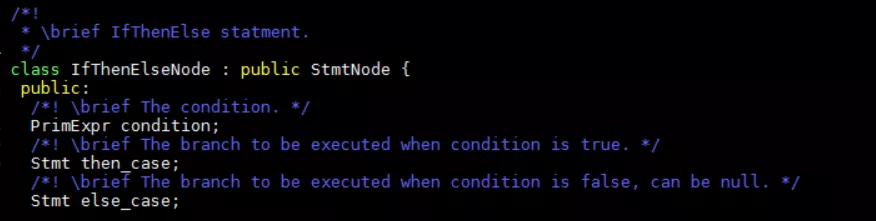
Stmt节点通常是节点中的主体实现,PrimExpr是TIR中节点的一个简单表达式。比如if节点:
ReadGraph创建完成后,通过PostDFSOrder来获取post-dfs列表,其函数具体实现在graph.cc中,
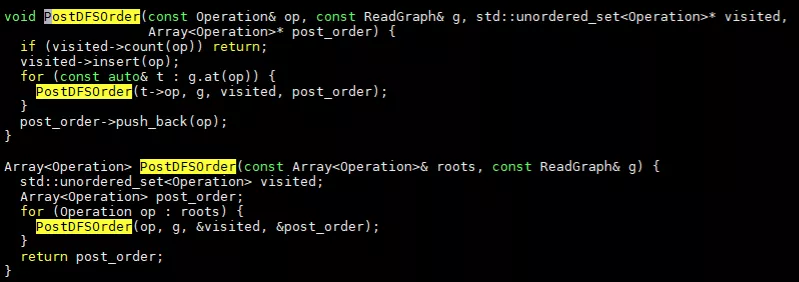
通过不断迭代来进行深度优先搜索。
接下来是对stage进行初始化。
首先对postorder中的所有op初始化一个stage对象。我们看以下stage的定义:
Stage类中主要定义了set_scope, compute_at, compute_root, bind, split, fuse等几种优化算法。同时定义了StageNode,在StageNode中定义了和优化相关的变量,包括op,iter变量等。看一下stage初始化代码:
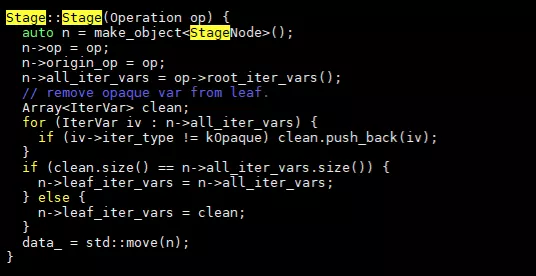
关键的几个变量lef_iter_vars,all_iter_vars,这些有什么作用还需要深入看优化函数的代码。我们看几个schedule函数,先看一个最简单的:compute_inline。代码只有一行:
(*this)->attach_type = kInline
对于标记了kInline的节点,在lower的时候会进行处理。应该会将其直接和调用的节点结合,合并两个op。
再看fuse函数,其代码为:
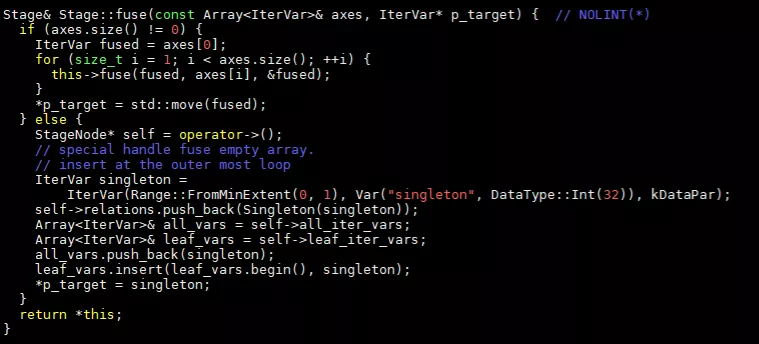
IterVar表示计算中坐标轴,比如一个两级循环,每级循环就是一个axis。从代码中看出,fuse函数会对输入的所有axis进行合并,用fused变量替换合并后的axis。
这块代码比较抽象,先熟悉以下流程,之后再深入读一下。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





