
资料下载


带Raspi的语音控制电梯
分享资料个
描述
1) 简介
免提选择电梯楼层
2) 特点
- 语音控制
- 液晶显示器
3) 硬件
3.1) 用于 Raspi Stretch 的麦克风
按照这些说明确保您可以在 Raspberry Pi 上录制音频
这是此项目中 Raspi Stretch 的配置:
更新 ALSA 配置:
sudo nano /usr/share/alsa/alsa.conf
并寻找以下两行:
defaults.ctl.card 0
defaults.pcm.card 0
将“0”都更改为“1”,然后保存文件
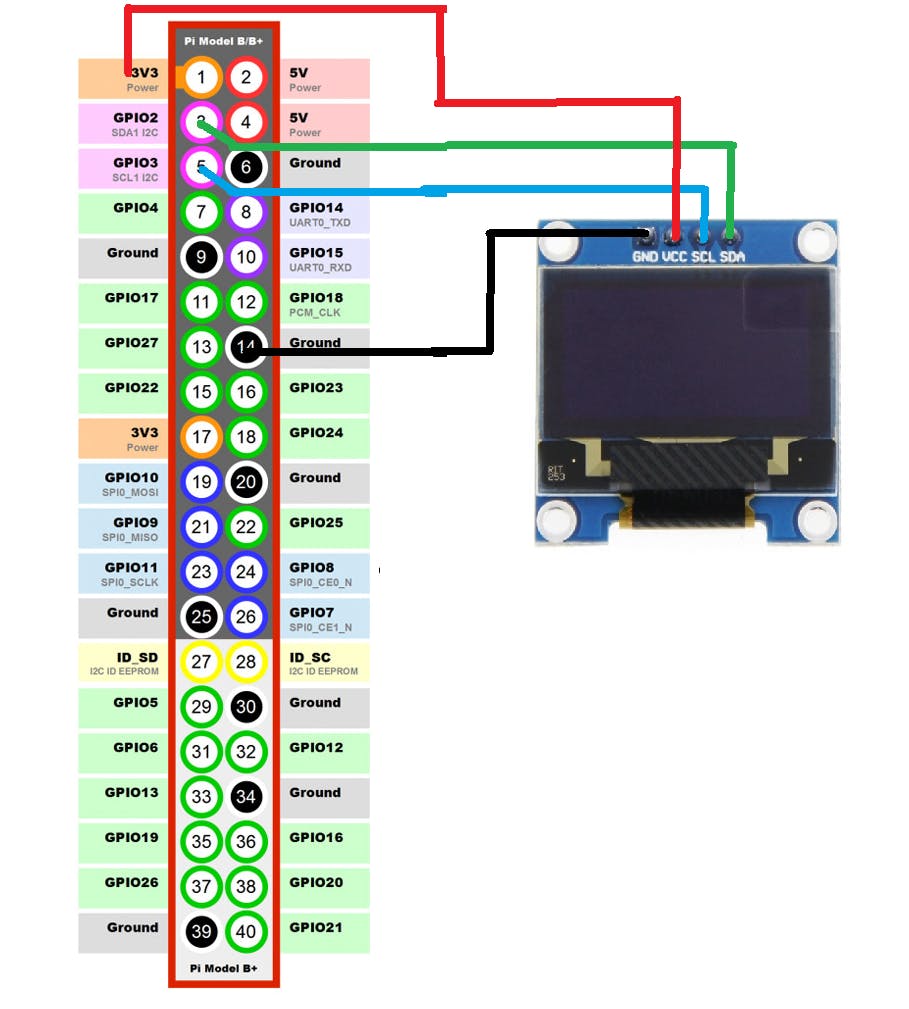
3.2 示意图
Raspi 和 LCD SSD1306
4) 代码
4.1) 准备数据集
首先,在您的计算机上下载并解压缩Google Speech Commands 数据集。
打开 1_data_pre.py.将变量更改 dataset_path为指向计算机上解压缩的 Google Speech Commands 数据集目录的位置。运行整个脚本。
该脚本会将所有语音样本(不包括background_noise集)转换为它们的梅尔频率倒谱系数 (MFCC),将它们分为训练集、验证集和测试集,并将它们作为张量保存在一个名为
all_targets_mfcc_sets.npz
.4.2) 训练模型
打开更改变量以指向解压后的 Google Speech Commands 数据集目录的位置。此外,将变量更改为指向文件的目录位置。 02-train.py.dataset_pathfeature_sets_pathall_targets_mfcc_sets.npz
运行整个脚本。它将从第一个脚本中生成的文件中读取 MFCC,构建一个 CNN,并使用我们创建的训练特征 (MFCC) 对其进行训练。然后脚本会将模型保存在
allworld_model.h5
4.3) 转换为 tflite
打开03-convert_tflite.py并确保它keras_model_filename指向我们在上一个脚本中创建的.h5 模型的位置。
运行此脚本将 .h5 模型转换为 .tflite 模型。我们将有
allword-model.tflite
4.4) Raspi 代码
将allword-model.tflite,requirements.txt 和4_ras-voice-cmd.pyfiles 复制到 Raspberry Pi 上的同一目录中。运行requirements.txt以安装所有要求包。然后运行 4_ras-voice-cmd.py脚本。
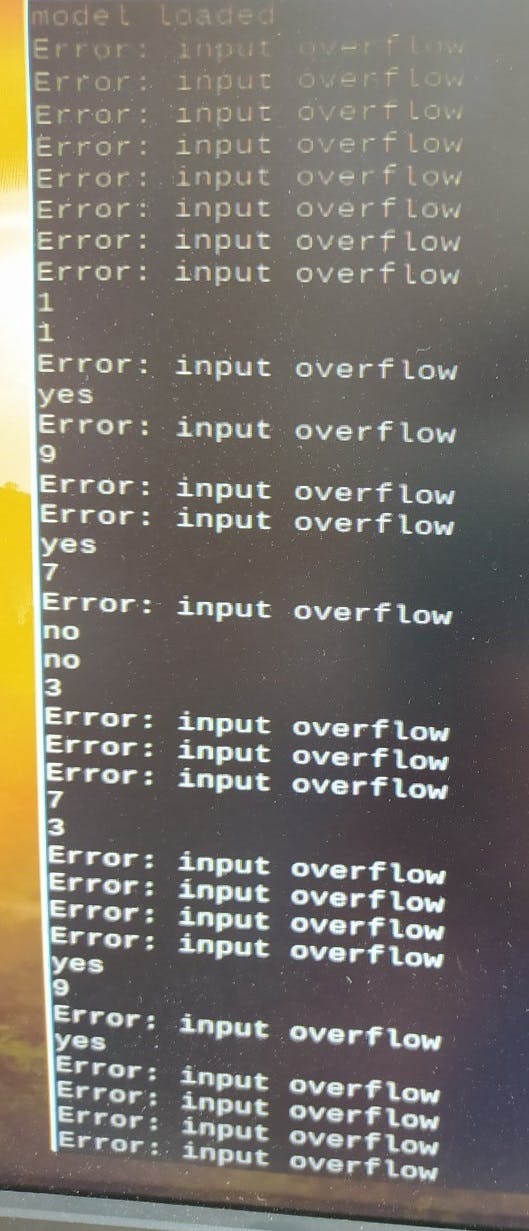
如果最后 1 秒捕获的音频包含此列表中的单词的置信度:
wake_word = ['backward', 'down', '8', '5', 'forward', '4', 'left', '9', 'no', 'off',
'on', '1', 'right','7','6', 'stop','3', '2', 'up','yes','0' ]
程序将打印出第 4 行 LCD 中的单词。

如果你接下来说“YES”,它将在 LCD 的第 3 行更新,如果“NO”,它将删除它

如果我们选择了错误的楼层,我们可以再次选择它来删除它。在这个例子中,我们选择了 1 - 9 -3 楼,但是我们不想去 9 楼,我们再次选择它来移除它。

这里是视频演示:
由于 Raspi 的限制,所以模型运行不流畅,存在输入溢出问题,但可以正常工作。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






