
资料下载


使用Ultra96 PYNQ测定织物GSM
张涛
分享资料个
描述
在织物印花厂的培训期间,我们注意到由于用于 GSM 测量的传统方法,大量织物被浪费。GSM(克每平方米)是织物质量的指标,织物行业使用各种机器和技术在整个制造和印花过程中保持织物的 GSM 一致。
织物 GSM 测量的传统方法包括切割一块面积为 0.01 平方厘米的小圆形织物,并使用精密天平测量其重量。这是在拉幅过程中专门完成的,机器的超喂根据输入和输出 GSM 进行控制。
该项目旨在用基于光学的方法取代这种传统方法。目前,该项目的范围仅限于单色(白色)平纹斜纹织物。(算法也可以应用于具有相当精确度的针织面料)
在 Ultra96 上设置 PYNQ
对于希望以最少的开发和调试时间实现硬件加速应用程序的任何人,PYNQ是一个不错的选择。目前 PYNQ 支持多个板,包括 Ultra96。所以如果你碰巧有一个 Ultra96 或类似的板子,我强烈建议你试试 PYNQ。(根据我的经验,任何支持 Python 的东西都非常容易使用)
您要做的第一件事是从这里为您的电路板下载 PYNQ 2.3 映像。对于 Ultra96,您也可以在 board 的官方网站上找到它。
下载后,您可以使用 PYNQ 重新刷新开发板随附的 SD 卡。如果您在格式化卡时遇到问题,此视频将展示如何使用 DISKPART for windows 来完成。
安装后,您应该能够使用 Ultra96 的 wifi 接入点(pynq_<您的主板的mac地址>)访问您的 Ultra96。您可以通过从您喜欢的浏览器访问192.168.2.1:9090打开 Jupyter Notebook ,并立即开始开发。
提示 :
登录密码是“xilinx”
获取 PYNQ 计算机视觉库
PYNQ 的计算机视觉库提供了几个用于在硬件中加速 OpenCV 功能的覆盖。目前支持 Filter2D 和扩张操作。(如果你是 Xilinx 的人读到这篇文章,我希望你们也可以下载可以使用 xfopencv 库构建的其余叠加层。下载 17gigs 的 SDSoC 来构建叠加层不是我可以用我的第三世界互联网)
您可以从此处获取计算机视觉库。
或者简单地说,在 Jupyter Notebook 中打开一个终端并输入,
sudo pip3 install --upgrade git+https://github.com/Xilinx/PYNQ-ComputerVision.git
你就完成了。
获取 PYNQ:BNN 覆盖
PYNQ 越来越好。Xilinx 的优秀人员还提供了一些叠加层,使我们能够在硬件中运行量化神经网络!您可以在他们的GitHub 页面上阅读更多相关信息。(接下来我们将尝试训练我们自己的小型神经网络来识别织物结构,从而使校准更容易。)
sudo pip3 install git+https://github.com/Xilinx/BNN-PYNQ.git (on PYNQ v2.3)
现在我们已经安装了所有这些花哨的叠加层,让我们开始做事吧。
机织物的经纬纱分离
我们决定使用USB 显微镜相机来获取织物的放大图像。
尽管它的价格很高,但我们还是能够获得令人惊讶的好织物图像。下图显示了机织织物放大后的样子。
机织织物由沿水平和垂直方向运行的纱线组成。那么有什么比使用可靠的 ol Sobel 过滤器更好的方法来分离它们!Sobel算子用于识别灰度图像的边缘(称为图像强度函数,其中每个像素仅被赋予一个从最低强度到最高强度的值)。使用这些梯度,可以通过将它们的梯度与相邻像素的梯度进行比较来找到形成边缘的像素。我们可以通过将原始图像与 Sobel X 和 Y 核进行卷积来生成经纱和纬纱的子图像。
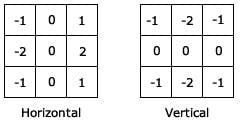
Sobel 滤波器 - 使用 Filter2D 覆盖在 Ultra96 硬件上实现
在我们开始使用硬件加速过滤器 2D 之前,我们需要导入必要的叠加层。让我们打开一个新的 Notebook 并开始开发算法。安装计算机视觉库时获得的笔记本中提供了使用叠加层时必须遵循的语法和结构。
提示:自己运行提供的笔记本,看看这些操作与软件相比有多快!
提示 2 - 如果您在访问相机时遇到错误,请执行 Kernel > Restart and Run All。
import cv2 #NOTE: This needs to be loaded first# Load filter2D + dilate overlay
# Load filter2D + dilate overlay
from pynq import Bitstreambs = Bitstream("/usr/local/lib/python3.6/dist-packages/pynq_cv/overlays/xv2Filter2DDilate.bit")bs.download()
import pynq_cv.overlays.xv2Filter2DDilate as xv2
# Load xlnk memory mangager
from pynq import XlnkXlnk.set_allocator_library('/usr/local/lib/python3.6/dist-packages/pynq_cv/overlays/xv2Filter2DDilate.so')mem_manager = Xlnk()
我们还需要从我们的网络摄像头捕捉帧。
camera = cv2.VideoCapture(0)
width = 640
height = 480
camera.set(cv2.CAP_PROP_FRAME_WIDTH,width)camera.set(cv2.CAP_PROP_FRAME_HEIGHT,height)
你还需要这个函数在 Jupyter 中显示图像。稍后我们将把这个项目与 Flask 集成,所以我们只需要在初始阶段使用它来检查事情是否正常工作。
import IPython
def imshow(img):
returnValue, buffer = cv2.imencode('.jpg', img)
IPython.display.display(IPython.display.Image(data=buffer.tobytes()))
让我们将内核设置为 numpy 数组。
sobelx = np.ones((480,640),np.uint8)sobely = np.ones((480,640),np.uint8)blur_frame = np.ones((480,640),np.uint8)
#These must be 3x3 since filter2d overlay supports a 3x3 kernel size
kernel_sobelx = np.array([[1.0,0.0,-1.0],[2.0,0.0,-2.0],[1.0,0.0,-1.0]],np.float32)#Sobel Xkernel_sobely = np.array([[1.0,2.0,1.0],[0.0,0.0,0.0],[-1.0,-2.0,-1.0]],np.float32)#Sobel Ykernel_sharp = np.array([[-1.0,-1.0,-1.0],[-1.0,32.0,-1.0],[-1.0,-1.0,-1.0]],np.float32)#sharpkernelb = np.array([[1/16.0,1/8.0,1/16.0],[1/8.0,1/4.0,1/8.0],[1/16.0,1/8.0,1/16.0]],np.float32)#blur
kernelVoid = np.zeros(0)
您将需要这些来运行您的硬件功能。
xFin= mem_manager.cma_array((height,width),np.uint8)
xFbuf= mem_manager.cma_array((height,width),np.uint8)
xFout= mem_manager.cma_array((height,width),np.uint8)
blur = mem_manager.cma_array((height,width),np.uint8)
让我们开始应用 sobel 过滤器。
# Flush webcam buffers (needed when rerunning notebook)
for _ in range(5):
ret, frame_in = camera.read()# Read in a frame
ret, img = camera.read()
if ret:
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #Convert color image from webcam to grayscale image
xFin[:] = gray[:] # load grayscale image to frame in buffer
xv2.filter2D(xFin, -1, kernelb, xFout, borderType=cv2.BORDER_CONSTANT) #See how easy it is to call the overlay!
blur_frame[:] = xFout[:]
imshow(blur_frame) #Display gaussian blurred image
blur[:] = xFout[:]
xv2.filter2D(blur, -1, kernel_sobelx, xFbuf, borderType=cv2.BORDER_CONSTANT) #convolve with sobel x filter
xv2.filter2D(xFbuf, -1, kernelVoid, xFout, borderType=cv2.BORDER_CONSTANT)
sobelx[:] = xFout[:]
xv2.filter2D(blur, -1, kernel_sobely, xFbuf, borderType=cv2.BORDER_CONSTANT) #convolve with sobel y filter
xv2.filter2D(xFbuf, -1, kernelVoid, xFout, borderType=cv2.BORDER_CONSTANT)
sobely[:] = xFout[:]
imshow(sobelx)
imshow(sobely)
else:
print("Error reading frame from camera.")
输出

由于我们需要强烈的模糊来去除纱线的细线部分,因此通过使用相机的焦距调整,输入图像略微失焦。


通过一些额外的形态变换和阈值处理,我们可以很容易地获得黑色背景上的白色条纹的经纱和纬纱。
由于我们需要获取经纱和纬纱的数量,因此我们不得不使用一些耗时的软件功能。(回想一下我们使用上面的代码获得的 sobelx 和 sobely 图像)
warpcount = 0
weftcount = 0
warparea = 0
weftarea = 0
draw_warp = 1
draw_weft = 1
warp_perimeter_thresh = 800
weft_perimeter_thresh = 800
############ This part should come after obtaining sobelx and y images##########
if draw_warp:
im2x, contoursx, hierarchyx = cv2.findContours(sobelx,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)
for cnt in contoursx:
perimeter = cv2.arcLength(cnt,True)
if perimeter > warp_perimeter_thresh:
cv2.drawContours(img, cnt, -1, (204,50,153), 2)
warpcount = warpcount+1
warparea = +cv2.contourArea(cnt)
if draw_weft:
im2y, contoursy, hierarchyy = cv2.findContours(sobely,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)
for cnt in contoursy:
perimeter = cv2.arcLength(cnt,True)
if perimeter > weft_perimeter_thresh:
cv2.drawContours(img, cnt, -1, (0,0,255), 2)
weftcount = weftcount+1
weftarea = +cv2.contourArea(cnt)
mem = "Warp Yarns : "+str(warpcount)
mem1 = "Warp Pixel Area : "+str(warparea)+ " pixels"
mem2 = "Weft Yarns : "+str(weftcount)mem3 = "Weft Pixel Area : "+str(weftarea)+ " pixels"
areatot = (warparea+weftarea)
mem4 = "Totalized Pixel Area : "+str(areatot)+ " pixels"
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,mem,(5,370), font, 1,(0,255,0),2,cv2.LINE_AA)
cv2.putText(img,mem1,(5,400), font, 1,(255,100,100),2,cv2.LINE_AA)
cv2.putText(img,mem2,(5,430), font, 1,(0,255,0),2,cv2.LINE_AA)
cv2.putText(img,mem3,(5,460), font, 1,(255,100,100),2,cv2.LINE_AA)
cv2.putText(img,mem4,(5,30), font, 1,(255,0,0),2,cv2.LINE_AA)
imshow(img)
这是输出。这部分有点资源密集,但我们的帧速率已经限制在 25FPS(由于它是 USB 摄像头),所以它不会对我们产生太大影响。
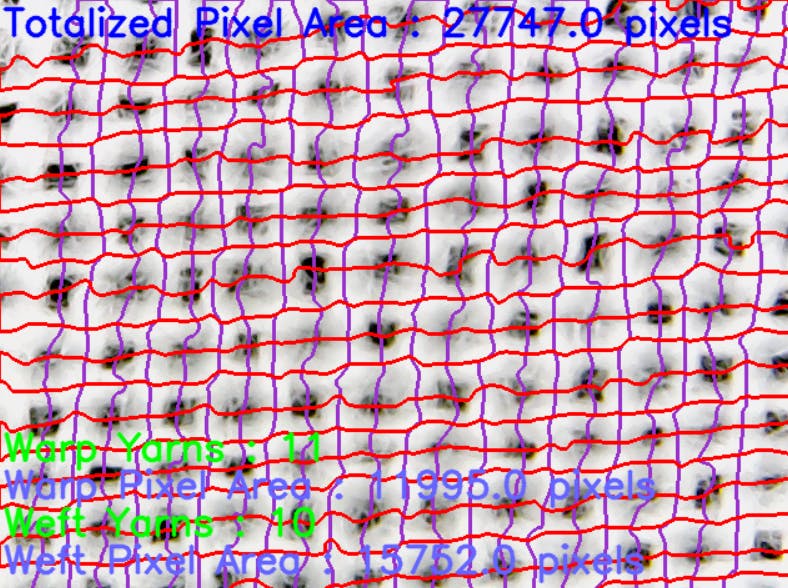
至此,我们已经得到了经纱和纬纱的支数(我们可以直接用这些来得到纱线密度,也就是单位面积的纱线数量),以及纱线的总像素数。由于在不知道给定织物类型的每个像素质量的情况下,无法从像素数量估计纱线质量,因此我们可以简单地使用具有已知 GSM 的织物样本进行校准。
举个例子。上面显示的织物样品是 110GSM。让我们结合它来校准我们的算法来测量这种织物类型的 GSM。
gsm = (areatot/27747)*110mem5 = "Predicted GSM : "+str(gsm)+ " GSM"
cv2.putText(img,mem5,(5,60), font, 1,(255,0,0),2,cv2.LINE_AA)
让我们再次运行代码并提供同一织物不同部分的图片。

预测的 GSM 很接近,但可以观察到一点偏差。校准后,我们必须确保传感器和织物之间的距离在移动到不同区域时不会发生变化。这促使我们开发了本文后半部分所示的 XY cartecean 滑块系统。
针织面料测试
针织物的织物结构更复杂,以便以这种方式捕捉。然而,如下图所示,我们可以在一侧捕获交织在一起的纱线簇(称为环)。

所以我们大概可以在这些纱线簇和质量之间建立关系。为此,我们需要更改我们的算法以仅找到垂直边缘。
回忆一下 draw_warp 和 draw_weft 控制变量。我们可以将其中一个设置为零。
使用 PYNQ 使我们的算法更智能:BNN
如果我们的算法能够在校准过程中识别出机织织物和针织物,它就可以轻松适应不同的织物结构。让我们利用 PYNQ BNN 覆盖来加快推理速度。
(在 Ultra96 上安装 BNN 后,请务必查看示例笔记本以熟悉自己)
为了在我们的数据集上训练提供的模型,我们需要使用我们相对更强大的计算机一段时间。(我是在 Linux 上完成的)所以将 PYNQ:BNN 存储库克隆到你的电脑上。
您需要按照此处的说明安装 Theano、Lasagne、Pylearn2 和其他一些必需的软件包。由于我们的数据集很小,我们现在不需要 CUDA 来进行 GPU 加速,但是如果您的数据集变得更大,您可能需要它。
安装 pylearn2 后,请记住通过输入为 pylearn2 数据集设置路径变量,
export PYLEARN2_VIEWER_COMMAND="eog --new-instance"
export PYLEARN2_DATA_PATH=/YOURPATHTOHERE/pylearn2/datasets
在您的终端中。
我们现在将尝试为我们的模型生成一个 MNIST 数据集进行训练。首先,我们需要获取一些梭织和针织织物结构的照片。
您可以使用末尾附加的phototaker.py代码从您的网络摄像头拍摄多张灰度图像。
拿到照片后,我们可以使用这个神奇的工具来生成 MNIST 数据。
https://github.com/gskielian/JPG-PNG-to-MNIST-NN-Format
将 repo 克隆到您的 PC 中,将图像复制到培训和测试目录。
根据标签数量编辑batches.meta.txt 。
在终端上键入./resize-script.sh 将所有图像调整为 28x28 大小并运行convert-images-to-mnist-format.py以生成数据集。
提示:您将获得 4 个文件。
gskielian 的工具将生成训练图像集和标签作为 train-images-idx3-ubyte 和 train-labels-idx1-ubyte,但您必须将 train 重命名为 t10k,因为这是训练脚本要查找的内容。
然后,您必须转到 pylearn2/pyearn2/datasets 并编辑mnist.py文件并更改训练和测试数据的大小、时期数和批量大小以适合您的数据集。
一切调整好后,你可以进入你的BNN目录,运行mnist.py
这将生成一个名为 mnist_parameters.npz 的文件。您需要使用 mnist-gen-weights-W1A1 或W1A2.py生成比特流
生成成功后,将生成的文件放在/usr/local/lib/python3.6/dist-packages/bnn/params/newmodel/lfcW1A1/
我们可以使用LFC-BNN_MNIST_Webcam.ipynb笔记本对其进行测试。
import bnn
hw_classifier = bnn.LfcClassifier(bnn.NETWORK_LFCW1A1,"newmodel",bnn.RUNTIME_HW)
import cv2
from PIL import Image as PIL_Image
from PIL import ImageEnhance
from PIL import ImageOps# says we capture an image from a webcam
import numpy as np
import math
from scipy import misc
from array import *
cap = cv2.VideoCapture(0)
_ , cv2_im = cap.read()
cv2_im = cv2.cvtColor(cv2_im,cv2.COLOR_BGR2RGB)
img = PIL_Image.fromarray(cv2_im).convert("L")
Image enhancement
contr = ImageEnhance.Contrast(img)img = contr.enhance(3)
# The enhancement values (contrast and brightness)
bright = ImageEnhance.Brightness(img)
# depends on backgroud, external lightsetc
img = bright.enhance(4.0)
#Adding a border for future cropping
img = ImageOps.expand(img,border=80,fill='white')
inverted = ImageOps.invert(img)
box = inverted.getbbox()
img_new = img.crop(box)
width, height = img_new.size
ratio = min((28./height), (28./width))
background = PIL_Image.new('RGB', (28,28), (255,255,255))
if(height == width):
img_new = img_new.resize((28,28))
elif(height>width):
img_new = img_new.resize((int(width*ratio),28))
background.paste(img_new, (int((28-img_new.size[0])/2),int((28-img_new.size[1])/2)))
else:
img_new = img_new.resize((28, int(height*ratio)))
background.paste(img_new, (int((28-img_new.size[0])/2),int((28-img_new.size[1])/2)))
background
img_data=np.asarray(background)
img_data = img_data[:,:,0]
misc.imsave('/home/xilinx/img_webcam_mnist.png', img_data)
#Resize the image and invert it (white on black)
smallimg = ImageOps.invert(img_load)
smallimg = smallimg.rotate(0)
data_image = array('B')
pixel = smallimg.load()
for x in range(0,28):
for y in range(0,28):
if(pixel[y,x] == 255):
data_image.append(255)
else:
data_image.append(1)
# Setting up the header of the MNIST format file - Required as the hardware is designed for MNIST dataset
hexval = "{0:#0{1}x}".format(1,6)
header = array('B')
header.extend([0,0,8,1,0,0])
header.append(int('0x'+hexval[2:][:2],16))
header.append(int('0x'+hexval[2:][2:],16))
header.extend([0,0,0,28,0,0,0,28])
header[3] = 3 # Changing MSB for image data (0x00000803)
data_image = header + data_image
output_file = open('/home/xilinx/img_webcam_mnist_processed', 'wb')
data_image.tofile(output_file)
output_file.close()
class_out = hw_classifier.classify_mnist("/home/xilinx/img_webcam_mnist_processed")
print("Class name: {0}".format(hw_classifier.class_name(class_out)))
训练时放置在类名 1 下的针织面料图像的输出。
推理耗时 7.00 微秒分类率:每秒 142857.14 张图像
班级名称:1
伟大的。我们的模型能够成功地确定织物结构,并且它使用硬件进行推理,速度非常快!
制作 XYZ 滑块
制作这种 XYZ 滑动机构是为了从织物的不同区域采集多个样本,而不会在校准后改变相机和传感器之间的距离。它是 3D 打印部件和金属制造部件的混合体。附上 3D 打印文件。
使用 EAGLE 设计了一个 PCB,以使用 A4988 步进电机驱动器控制 4 个步进电机。这些驱动程序使用 STM32 F103C8T6 MCU 进行控制。MCU根据Ultra96板通过Serial发送的数据控制各轴的绝对位置。附上 PCB gerber 文件和 STM32-Arduino 代码。(转到页面末尾!)
您还需要为 Arduino 下载AccelStepper 库。
MCU 期望以 '、' 作为分隔符的绝对位置和 * 表示字符串结束。我们可以轻松地生成一个字符串并使用 pySerial 通过串行方式发送它。

使用 Flask 创建 Web 界面
现在我们的代码可以正常工作了,让我们把所有东西放在一起。您可以使用 Flask 快速为您的图像处理应用程序生成一个漂亮的 webapp。而且很棒的是,Ultra96 开发板预装了 Flask!您可以在 GitHub 上找到如何将 Flask 与 OpenCV 一起使用的一个很好的示例。
https://github.com/log0/video_streaming_with_flask_example
借助一点 Bootstrap 和 Javascript 的魔力,您可以制作一个真正响应式的 Web GUI,如下所示。即:我没有提供整个 Flask GUI,因为它仍然是一个正在开发的用于商业用途的项目,但是如果您对如何制作 GUI 有任何疑问,我们非常乐意为您提供帮助。

结果
基于 Sobel 滤波器的纱线检测是对来自 3 个不同织物样本的 30 个图像进行的。下图显示了使用的样本类型。

通过将相机放置在织物的不同部分上,获得相同织物的不同样品。纱线检测算法在每个样品的 10 张这样的照片上运行。结果表明,机织织物的准确度 <94%,针织物的垂直毛圈结构准确度为 90%。(根据要求提供表格结果)

使用纱线像素区域的 GSM 测定
50 个不同的织物样本(每个不同点 4 帧,共 200 张图像),标称 GSM 为 107 GSM,用于该测试。全范围误差(最大读数为 250GSM)被制成表格。下图描述了读数相对于实际值的变化。
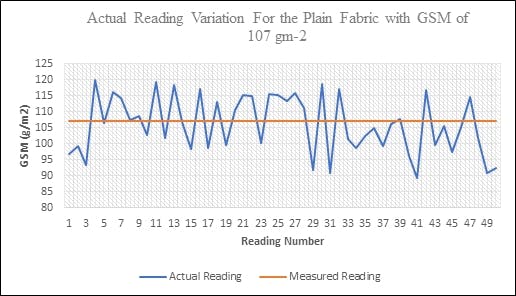
可以观察到相当大的偏差,但这在织物行业中是可以接受的。然而,这可以通过增强算法进一步最小化。
结论
Ultra96 板对于初学者和专家来说都是一个很棒的板。它与 PYNQ 的兼容性将其提升到了一个全新的水平。如果您对 Xilinx 提供的令人惊叹的计算机视觉和 BNN 库不满意,您可以使用 Vivado 编写自己的“叠加层”,并在硬件上运行某些部分(甚至整个程序)。
在硬件层中运行卷积(对于 Sobel、Smoothing、Erosion、Blurs)等操作可以大大减少算法的运行时间。然而,在这个应用程序中,帧速率受到资源密集型轮廓检测和相机的最大帧速率(24fps)的限制。
希望 Avnet 和 Xilinx 为 PYNQ 和 Ultra96 创建越来越多的资源和库,这使开发人员能够快速测试他们的想法,而无需经历从头开始构建一切的麻烦。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




