
资料下载


Ultra96-V2上的头部姿势估计
李伟
分享资料个
描述
介绍
Xilinx Model Zoo 包含许多预构建的卷积神经网络模型。
该项目利用了其中几个模型,以实现创建面部应用程序的基础。
- 人脸检测:densebox_640_360
- 人脸地标检测:facelandmark

检测到面部并识别面部标志后,我们可以添加额外的处理,例如头部姿势估计。
- Satya Mallick,使用 OpenCV 和 DLIB 进行头部姿势估计,LearnOpenCV https://learnopencv.com/head-pose-estimation-using-opencv-and-dlib/ https://github.com/spmallick/learnopencv/blob/master/头部姿势/headPose.cpp

让我们开始吧 !
第 1 步 - 创建 SD 卡
为以下 Avnet 平台提供了预构建的 Vitis-AI 1.3 SD 卡映像:
- u96v2_sbc_base : Ultra96-V2 开发板
- uz7ev_evcc_base:UltraZed-EV SOM (7EV) + FMC 载卡
- uz3eg_iocc_base:UltraZed-EG SOM (3EG) + IO 载卡
可在此处找到预构建 SD 卡映像的下载链接:
- 适用于 Avnet Vitis 平台的 Vitis-AI 1.3 流程:https ://avnet.me/vitis-ai-1.3-project
下载并解压后,.img 文件可以编程到 16GB 微型 SD 卡。
0.解压压缩包得到.img文件
1. 将开发板特定的 SD 卡映像编程到 16GB(或更大)的 micro SD 卡
一个。在 Windows 机器上,使用 Balena Etcher 或 Win32DiskImager(免费开源软件)
湾。在 linux 机器上,使用 Balena Etcher 或使用 dd 实用程序
$ sudo dd bs=4M if=Avnet-{platform}-Vitis-AI-1-3-{date}.img of=/dev/sd{X} status=progress conv=fsync
其中 {X} 是一个小写字母,用于指定 SD 卡的设备。您可以使用“df -h”来确定您的 SD 卡对应的设备。
第 2 步 - 克隆源代码存储库
本项目中使用的源代码可以从以下存储库中获取:
- https://github.com/AlbertaBeef/vitis_ai_cpp_examples
- https://github.com/AlbertaBeef/vitis_ai_python_examples
如果您有活动的互联网连接,您可以简单地将存储库克隆到嵌入式平台的根目录:
$ cd ~
$ git clone https://github.com/AlbertaBeef/vitis_ai_cpp_examples
$ git clone https://github.com/AlbertaBeef/vitis_ai_python_examples
第 3 步 - 人脸检测示例概述
为了实现头部姿态估计示例,我们修改了一个现有示例facedetect ,该示例可以在以下目录中找到:
~/Vitis-AI/demo/Vitis-AI-Library/samples/facedetect
如果我们查看 test_video_facedetect.cpp 源代码,我们可以看到它非常小:
int main(int argc, char *argv[]) {
string model = argv[1];
return vitis::ai::main_for_video_demo(
argc, argv,
[model] {
return vitis::ai::FaceDetect::create(model);
},
process_result, 2);
}
此代码的可视化表示如下图所示:
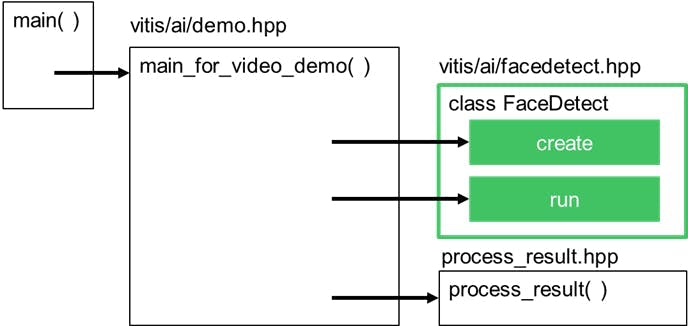
我们可以看到 main 函数使用了一个通用的 main_for_video_demo() 函数,并向它传递了一个 FaceDetect 类的实例,该类提供了 create() 和 run() 方法,以及一个 process_result() 函数。
该示例可以使用以下命令运行:
1. 启动后,启动 dpu_sw_optimize.sh 脚本,该脚本将优化 DDR 内存的 QoS 配置
$ cd ~/dpu_sw_optimize/zynqmp
$ source ./zynqmp_dpu_optimize.sh
2. 禁用 dmesg 详细输出:
$ dmesg -D
3.定义DISPLAY环境变量
$ export DISPLAY=:0.0
4.将DP显示器的分辨率改为较低的分辨率,比如640x480
$ xrandr --output DP-1 --mode 640x480
5.使用以下参数启动面部检测应用程序:
- 指定“densebox_640_360”作为第一个参数
- 指定“0”作为第二个参数,指定 USB 摄像头)
$ cd ~/Vitis-AI/demo/Vitis-AI-Library/samples/facedetect
$ ./test_video_facedetect densebox_640_360 0

第 4 步 - 创建头部姿势估计应用程序
我们可以使用这个通用的 main_for_video_demo(),以及一个定义我们修改后的用例的自定义类,如下图所示:
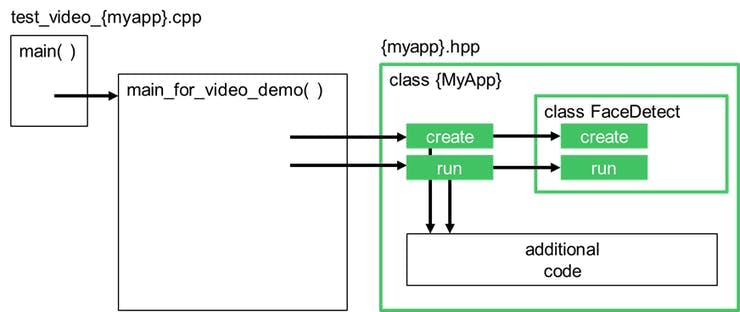
对于头部姿态估计示例,对面部检测示例进行了以下修改:
- 添加人脸地标
- 添加头部姿势估计
下图说明了此示例的修改代码。
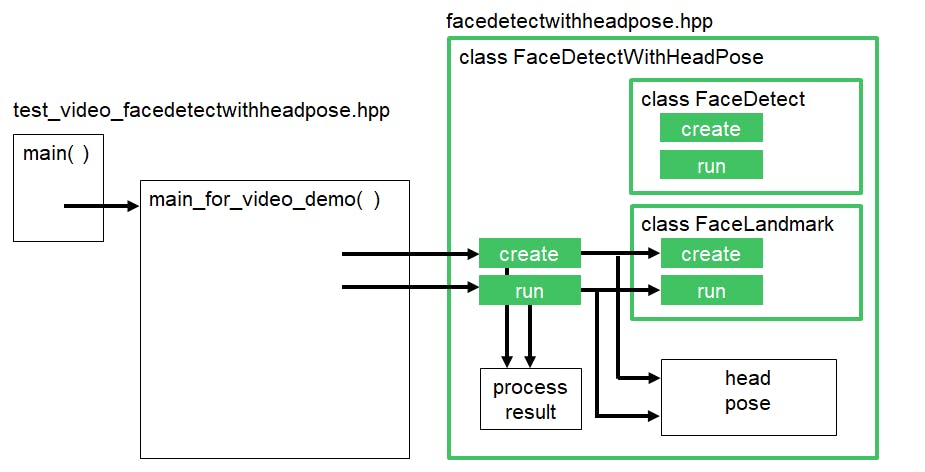
修改后的代码可以在以下位置找到:
~/vitis_ai_cpp_examples/facedetectwithheadpose/test_video_facedetectwithheadpose.cpp
1. 构建头部姿态估计应用程序
$ cd ~/vitis_ai_cpp_examples/facedetectwithheadpose
$ ./build.sh
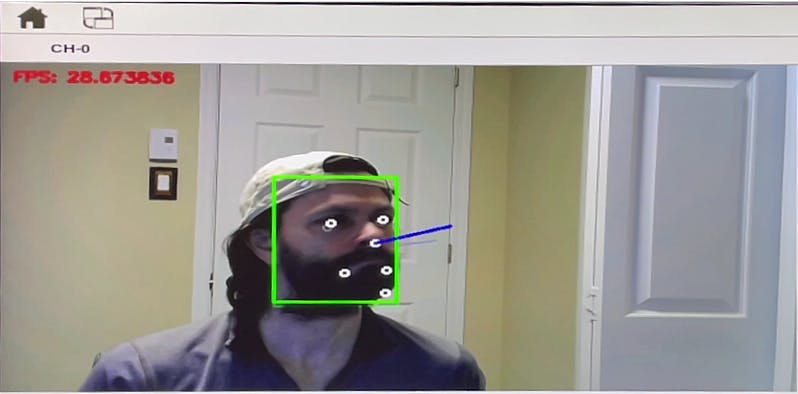
2.启动头部姿势估计应用程序
$ cd ~/vitis_ai_cpp_examples/facedetectwithheadpose
$ ./test_video_facedetectwithheadpose 0
对于头部姿势估计示例,我重用了以下代码:
头部姿势估计:
- Satya Mallick,使用 OpenCV 和 DLIB 进行头部姿势估计,LearnOpenCV https://learnopencv.com/head-pose-estimation-using-opencv-and-dlib/https://github.com/spmallick/learnopencv/blob/master/头部姿势/headPose.cpp
我不会描述这个算法背后的数学原理,因为 Mallick 先生做得很好。我们需要知道的是,在我们的 2D 检测到的面部上需要以下 6 个标志点,以便估计头部位置。
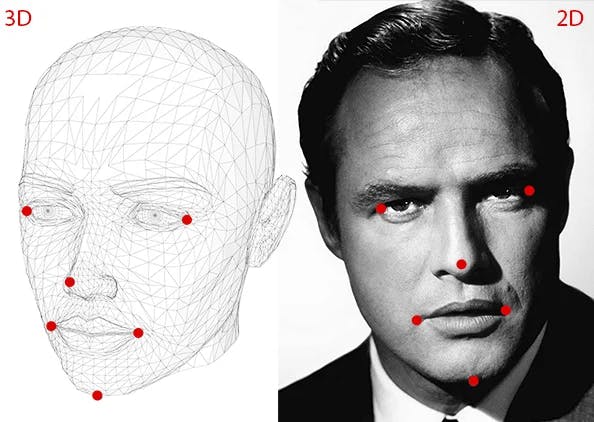
Xilinx 的 facelandmark 模型为我们提供了 5 个界标,分别对应两只眼睛、鼻子和嘴角,因此我们缺少第 6 个界标,对应下巴。
在我的实现中,我粗略估计了下巴的位置:
- 相对于嘴的位置与相对于眼睛的鼻子的位置大致相同
第 5 步 - Python 实现
python中也提供了类似的实现。
1.启动头部姿态估计示例的python版本:
$ cd ~/vitis_ai_python_examples/face_applications
$ python3 face_headpose.py
已知限制
在这个项目中实现的头部姿势估计有一定的局限性。当头部姿势向上或向下看时,它不能很好地工作。有两个因素可能导致这种情况:
- 用于眼睛的界标对应于眼睛的中心,而头部姿势源代码假设眼睛的外角
- 估计用于下巴的地标,可能并不总是正确的
你能改进这个实现吗?
- 你会以不同的方式计算下巴位置吗?
- 你会使用一个替代的面部标志,包括面部
第 6 步 - 使用 DLIB 改进结果
为了改善结果,我尝试了 DLIB 提供的功能,这是一个非常流行的人脸检测和地标库。
为了加快速度,我将在 python(而不是 C++)中执行此操作。
1.首先需要做的是安装DLIB
安装 dlib 包(仅与 python 一起使用)的最快方法是使用 pip3 命令:
$ pip3 install dlib
安装 dlib(供 python 和 C++ 使用)的较长方法是从源代码构建:
# download source code from dlib.net
wget http://dlib.net/files/dlib-19.21.tar.bz2
tar xvf dlib-19.21.tar.bz2
cd dlib-19.21
# build/install for use with C++
mkdir build
cd build
cmake ..
cmake --build . --config Release
sudo make install
# build/install for use with python
python setup.py install
这两种方法都需要有效的互联网连接并且需要很长时间,因为需要为我们的嵌入式平台构建包。
2. 确保您拥有最新版本的存储库内容
$ cd ~/vitis_ai_python_examples
$ git pull
3.接下来,运行以下脚本
$ cd ~/vitis_ai_python_examples/face_applications_dlib
$ python3 face_headpose_dlib.py
此版本的脚本具有以下附加功能:
- 添加了状态显示,其中包括 FPS
- 按“d”在人脸检测算法之间切换(VART 与 DLIB)
- 按“l”在人脸界标算法之间切换(VART 与 DLIB)
请注意,VART 是 Vitis-AI 运行时的缩写,此处用于表示使用 Vitis-AI 预构建模型。
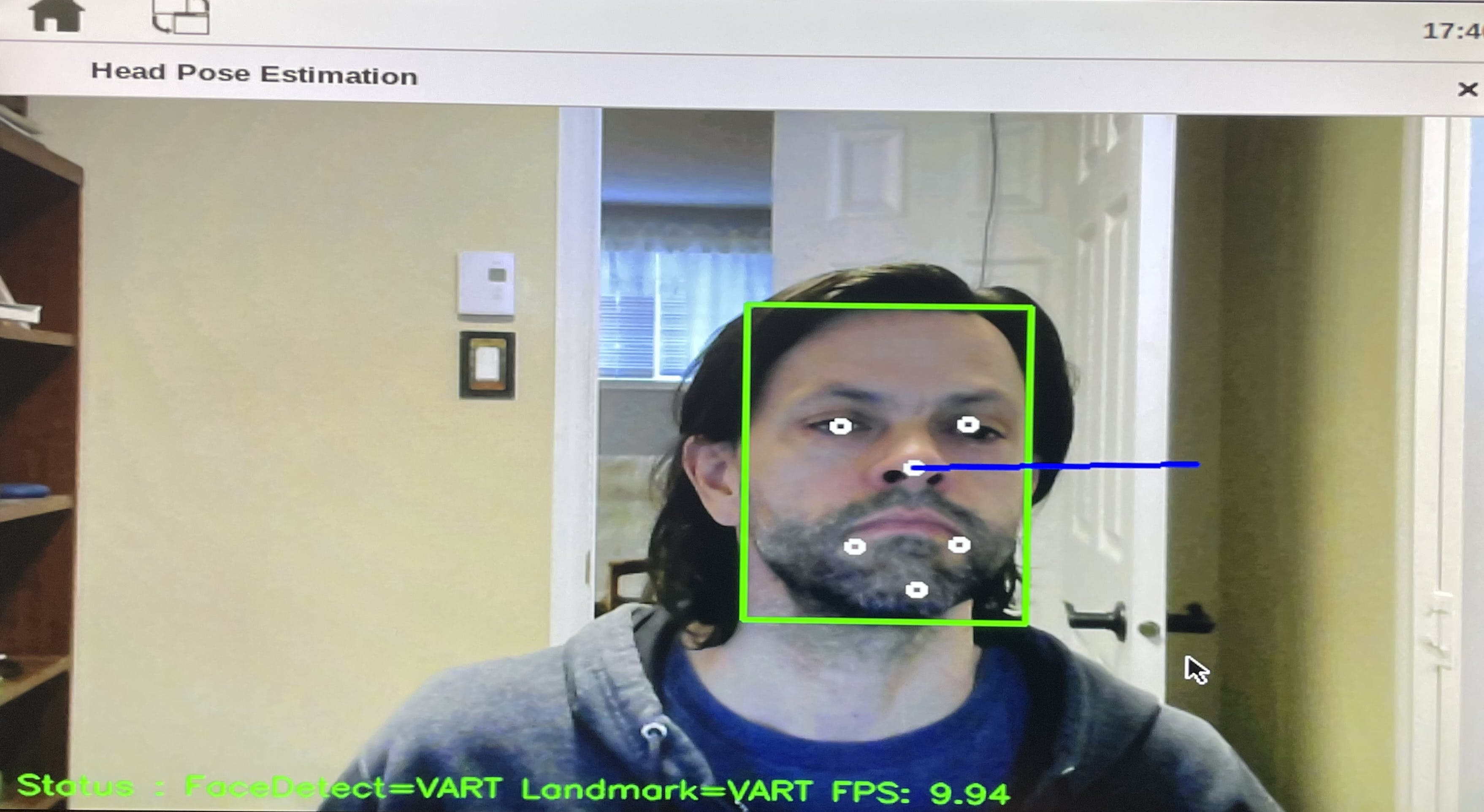
首先要观察的是,VART 人脸检测的运行速度比 DLIB 人脸检测快 5 倍,但结果相似。

可以进行的第二个观察是 VART 面部标志与 DLIB 面部标志不在同一个位置,这可能解释了为什么使用 DLIB 面部标志可以获得更好的头部姿势结果:
- 眼睛标志物:VART 位于眼睛中心,DLIB 位于外角
- 鼻子标志:VART 位于鼻子底部,DLIB 位于鼻尖
- 下巴地标:为 VART 估计,为 DLIB 正确定位
可以观察到的第三个观察结果是,当人脸不是正面时,VART 人脸界标更好。

那么,有赢家吗?
就性能而言,绝对是基于 Vitis-AI 的人脸检测和地标实现。
对于头部姿势结果:
对于正面用例,基于 Vitis-AI 的人脸检测和基于 DLIB 的地标可提供更好的结果。
对于侧面用例,基于 Vitis-AI 的人脸检测和地标可提供更好的结果。
第 7 步 - 进一步使用 DLIB 面部标志
我鼓励您运行显示每种算法的所有地标的脚本版本,如下所示:
$ cd ~/vitis_ai_python_examples/face_applications_dlib
$ python3 face_landmark_dlib.py
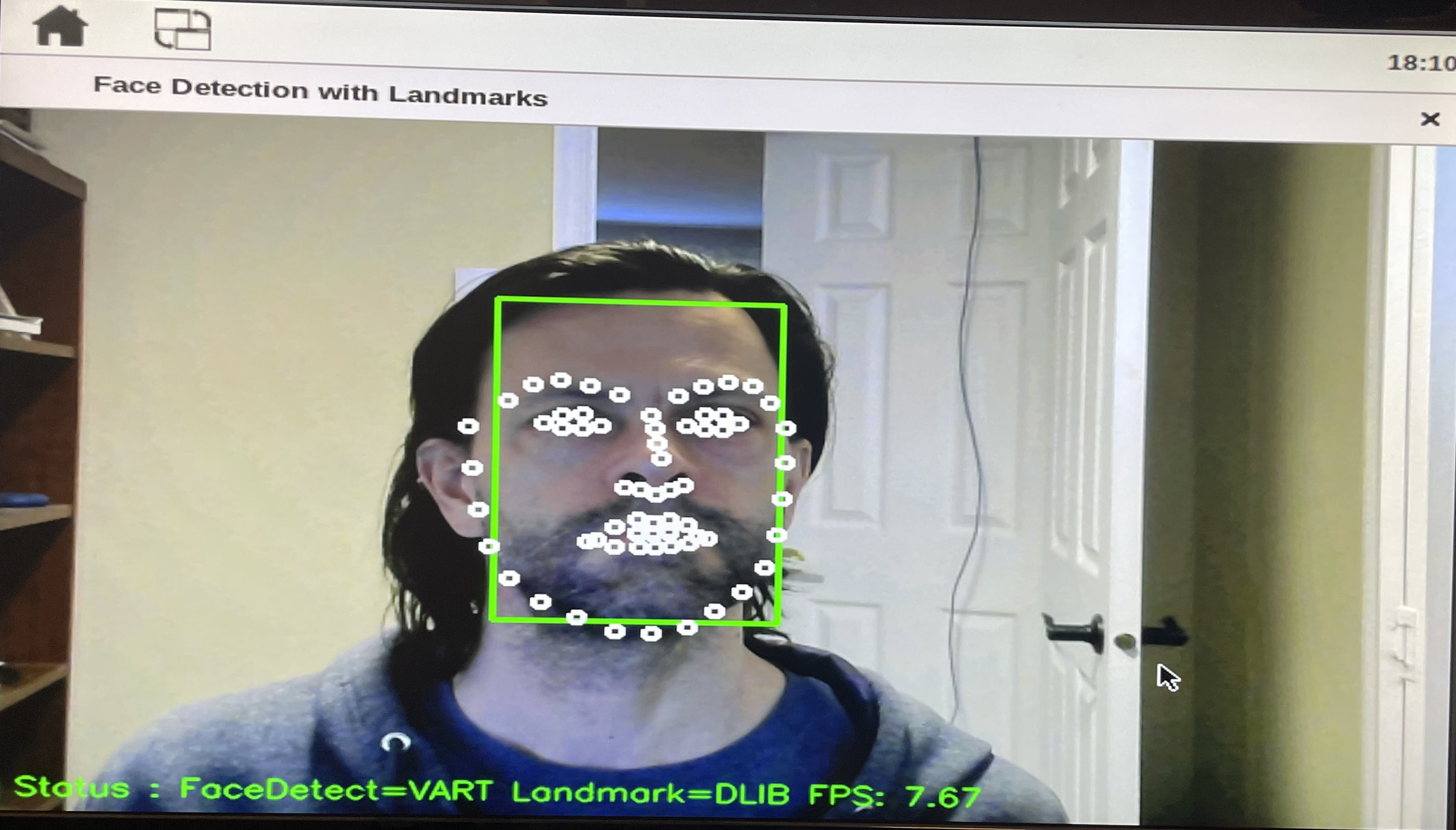
您还能想到哪些其他使用面部标志的应用程序?在下面的评论中分享您的想法。
结论
我希望本教程能帮助您开始在 Ultra96-V2 和其他 Avnet 平台上使用人脸应用程序。
如果您还想看到任何其他相关内容,请在下面的评论中分享您的想法。
修订记录
2021/03/15 - 第一版
2021/03/18 - 添加了“第 6 步 - 使用 DLIB 改进结果”
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





