
资料下载


基于FPGA的披萨切片角度计算器
贾飞小
分享资料个
描述
介绍
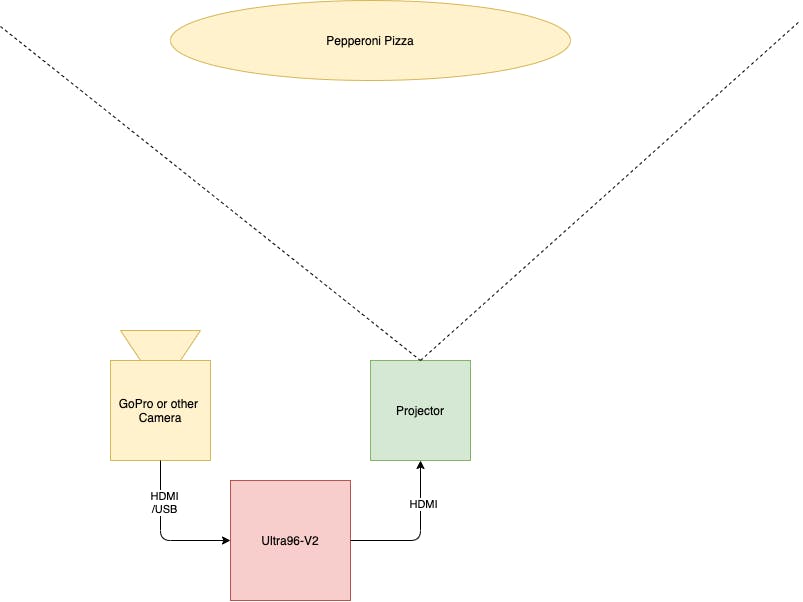
嗨,在这个项目中,我想向您展示如何构建一个基于 FPGA 加速 Yolov3 网络的披萨切片角度计算器。披萨配料由 Yolov3 网络分析。根据 Yolo 输出,计算出意大利辣香肠热图。此热图用于计算将比萨饼切成两半的完美角度。最佳切割角度的结果投影在披萨附近。Avnet 的 Ultra96-V2 板用于所有计算。GoPro Hero 相机用于从意大利辣香肠比萨饼中捕捉图像。相机和投影仪连接到 Ultra96-V2 板。我使用了定制的 HDMI 板,但您可以使用 USB 网络摄像头进行图像捕捉。来自相机的传入图像会调整大小,这是通过可编程逻辑 (PL) 加速器完成的。Yolov3对象检测网络,DPU ) 执行比萨饼和意大利辣香肠检测。#projectofthemonth
在你开始之前
项目文档分为“入门”、“从数据集到DPU精灵”和“切片器程序”三个部分。“入门”部分描述了在 Ultra96V2 板上运行基于 Yolo 的披萨切片机所需的步骤。“从数据集到 DPU elf”一节描述了从自定义数据集到 DPU elf 文件的整个开发过程。该项目的这一部分最耗时,因为赛灵思文档和示例仅涵盖了整个开发过程的一部分。目前,这部分正在建设中,但结合项目源代码,它是您自定义 Xilinx DPU 项目的良好起点。就在这个项目在 hackster 上发布前几个小时,LogicTronix 发布了这个教程,其中涵盖了 Yolov3 到 DPU 精灵编译的某些部分。最后但同样重要的是,您可以在“切片器程序”部分找到实现 Pizza 切片器应用程序的 Python 代码的详细描述。
入门
- 下载 Ultra96V2 的 PYNQ V2.6映像
- 从这个黑客教程安装 PYNQ-DPU
- 为了提高 OpenCV 的速度,我在 Tengine 支持下重建了 OpenCV。这提高了基于 ARM 处理器的系统的整体性能。
- 克隆我的项目存储库以构建 FPGA 硬件。我使用了定制的 HDMI 板,因此 Pizza-base-without-hdmi.tcl 创建了带有 pl 图像调整器和 DPU 的 Ultra96-V2 板,没有 HDMI 输入/输出。
- 从 Vitis ai docker 运行 compile-caffe.sh 脚本。该脚本使用预训练的 Caffe 模型。我还将用于 DPU 量化和编译的测试图像放入存储库中。
- 复制板上的FPGA *.bin 文件和DPU *.elf 文件。但一切都在与披萨切片机 jupyter notebook 相同的目录中。
- 使用我的 repo 中的披萨切片机 jupyter notebook 并测试 yolov3 网络并切片一些披萨。
从数据集到 DPU 精灵
遗憾的是,Xilinx 的 Zoo 模型没有提供用于比萨检测的预训练网络,所以我不得不从头开始构建网络。下图显示了在 Xilinx DPU 上运行 Yolo 网络所需的步骤。
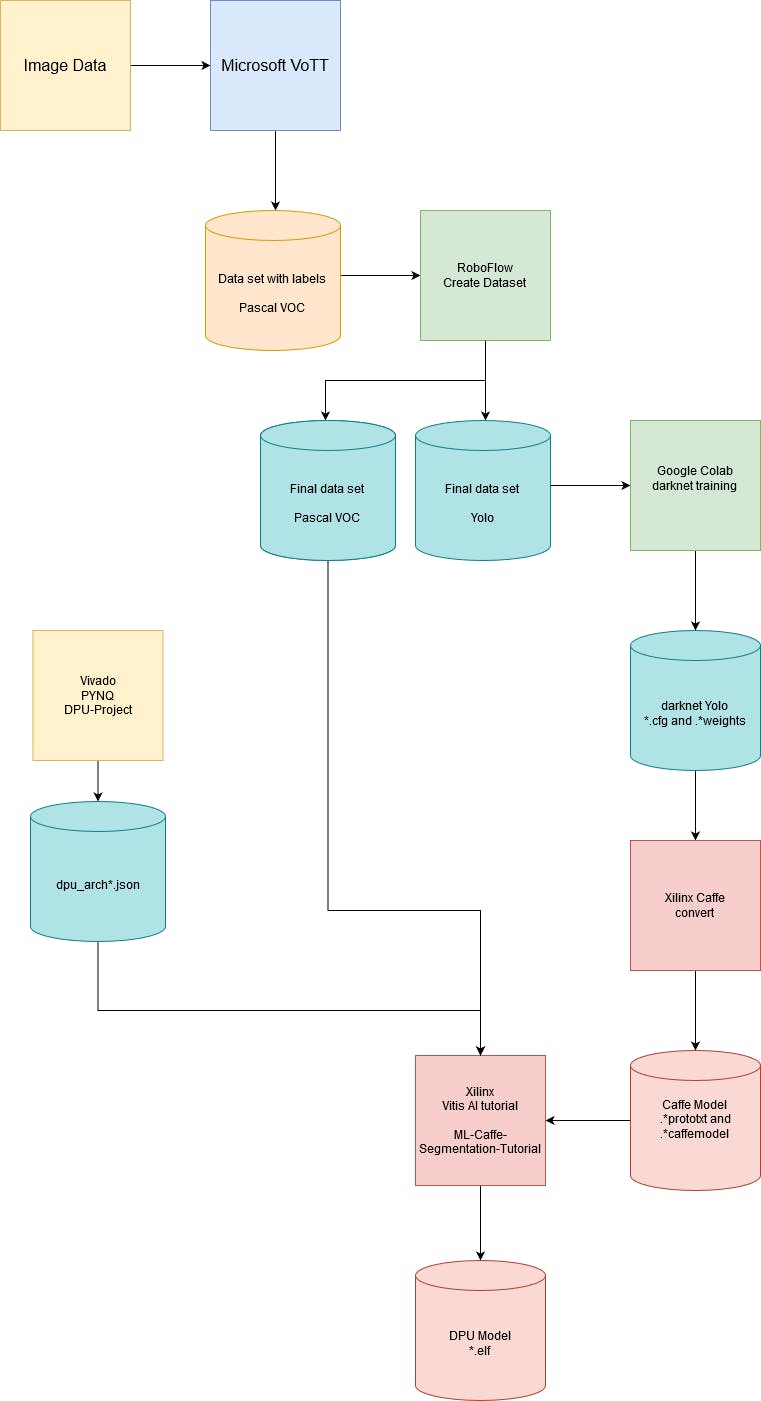
详细的工作流程:
- 图片:首先我必须得到一些意大利辣香肠披萨的图片。我使用了来自 Google 的 22 张图片,后来我添加了一些来自 GoPro 的真实图片。所有图像都已调整大小并裁剪为 320x320 像素。
- 图像注释:图像注释的一个很好的工具是Microsoft VoTT 。对于披萨切片机应用程序,使用了披萨和意大利辣香肠的边界框。VoTT 可以导出不同格式的数据集,我使用Pascal VOC 格式进行导出。
- 数据增强:训练一个只有 22 张图像的网络对于网络推理来说不是很健壮。为了提高训练数据集和鲁棒性,来自roboflow ai的数据增强工作流程. 用来。这是一种修改小型数据集并添加一些预处理图像进行训练的简单方法。使用每个数据集限制为 1000 张图像的免费帐户,可以构建一个小型数据集。对于这个用例,旋转和饱和是模拟真实世界场景的好方法。很酷的是,roboflow 在预处理步骤中更新注释。我的最终数据集包含大约 800 张披萨图像,慢慢地我饿了…… 需要将预处理的数据集导出到 Pascal VOC(Xilinx DPU 编译)和 Yolo 数据集(用于训练)。生成多种输出格式的可能性是 roboflow 的另一个重要功能。
- 网络训练:YOLO 网络是用darknet训练的。对于训练,使用了Google Colab GPU 笔记本。培训笔记本可在我的 GitHub 存储库中找到。我在我的 Colab 笔记本中添加了对 yolov2-tiny、yolov3-tiny 和 yolov4-tiny 训练的支持。训练后,您可以比较不同的网络及其输出。用于该项目的预训练网络可在我的 GitHub 存储库中获得。
- Darknet to Caffe convert:要将 Yolo 网络与 Xilinx DPU 一起使用,必须将网络转换为 Caffe 格式。这一步很棘手。几乎没有关于如何将暗网输出转换为与 Xilinx Vitis ai 编译器兼容的 Caffe 模型的文档。Xilinx 在Vitis-Ai存储库中提供了 xilinx-caffe 版本。我构建了一个docker 容器,它构建了 xilinx-caffe 版本,该容器能够将暗网模型转换为 caffe 模型。要转换暗网模型(*cfg 和 *weights),请使用convert.py脚本,该脚本位于Vitis-AI/AI-Model-Zoo/caffe-xilinx/scripts/如果一切正常,您将获得一个 *.prototxt 和一个 *.caffe 模型
- 编译DPU elf:最后一步,DPU elf文件的量化和编译需要一些准备。需要一个 Vivado 硬件项目,其中包括 DPU IP、Pascal 验证数据集、Caffe 网络和 Vitis-AI docker 容器。这仅对 Ultra96-V2 板 DPU 上的 Yolo 网络有效,对于其他网络类型,要求可能有所不同。需要在 Vitis Ai docker 容器内执行以下步骤。但在我们能够编译模型之前,我们必须更改 *.prototxt 文件的第一个“层”。请参阅项目 GitHub Repo和Xilinx 教程。 量化步骤需要有效的网络输入数据。为了让第一层的图像加载器运行起来,我们需要 ms coco 数据集格式的图像。幸运的是,roboflow 可以以 coco 格式导出数据集(参见“数据增强”步骤)。对于量化,可以使用来自 roboflow 的测试图像。Roboflow 自动将数据集拆分为测试、训练和有效部分。完整的编译代码、测试图像和 DPU 配置是我 repo 的一部分。除了网络层适配之外,DPU 编译器还需要一些有关 DPU 的信息,这些信息在硬件设计中实现。配置存储在 JSON 文件中。JSON 文件分为两部分,一是 CPU 架构和 DPU 类型,另一部分是 DPU 配置(Cores、Softmax 等)。这个 JSON 文件可以使用 DELT 工具生成。DELT 工具将 *.hwh 文件转换为 JSON 文件,可用于编译。有关更多信息,请参阅此赛灵思论坛帖子。我的自定义 JSON 文件是我的repo的一部分。如果你准备好了一切,你就可以量化和编译 DPU 精灵了。从您的自定义网络。如果一切成功,就会生成dpu.elf文件。该文件可以使用 PYNQ-DPU python 框架加载。
切片程序
最后一部分解释了 Pizza Slicer 代码。该程序是用python3编写的,并使用jupyter notebook来控制程序。源代码
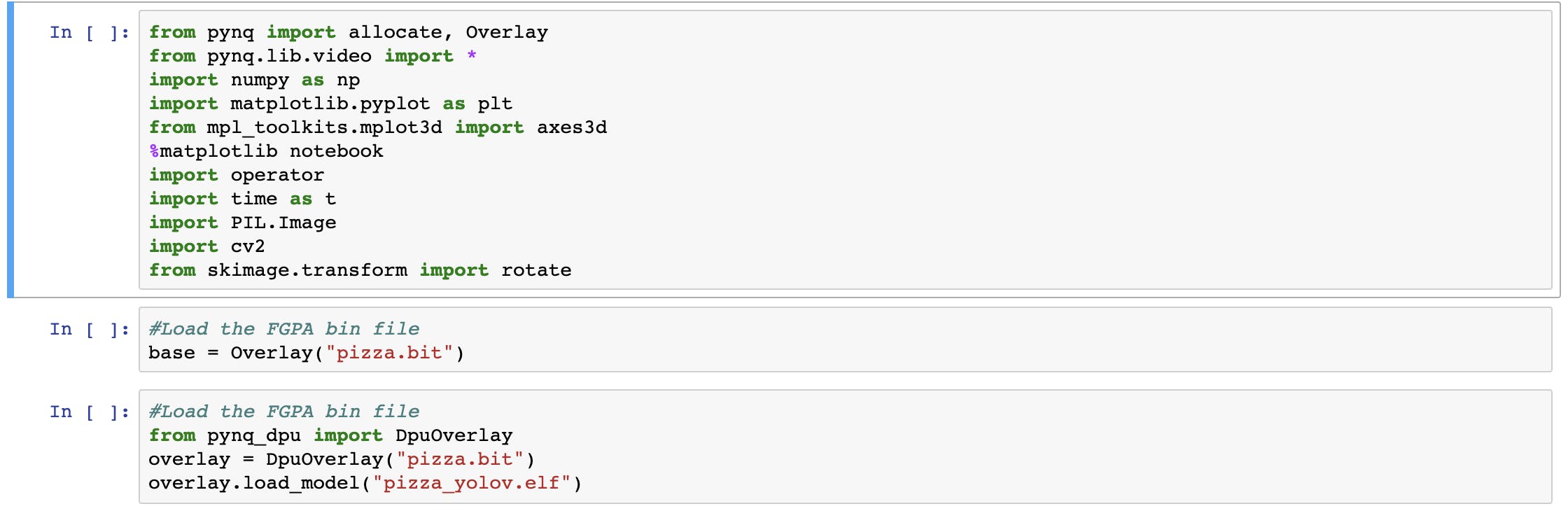
前三个单元格涵盖了所有 Python 导入和 FPGA/DPU 文件加载。
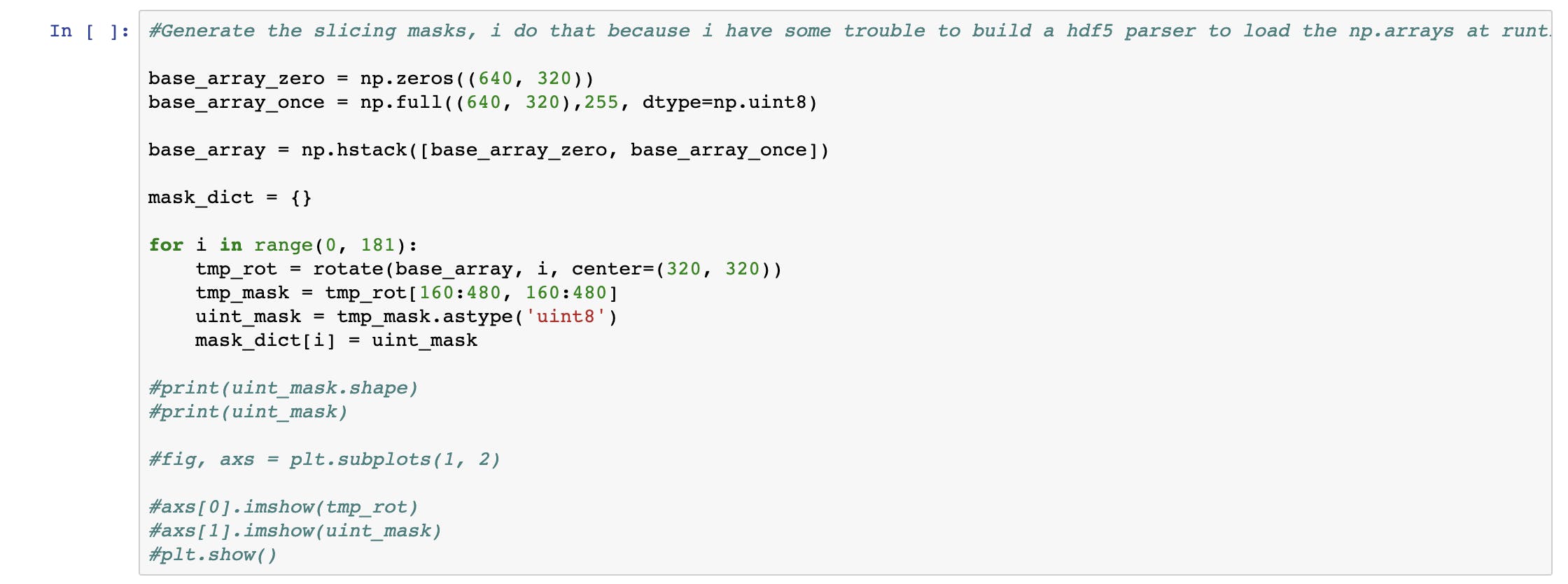
生成切片蒙版。找到最佳角度的问题以几何方式解决。我使用了 180 个蒙版,将 320 x 320 的图像分成两部分。注释代码,启用绘制切片 mak 的 matplotlib 图。
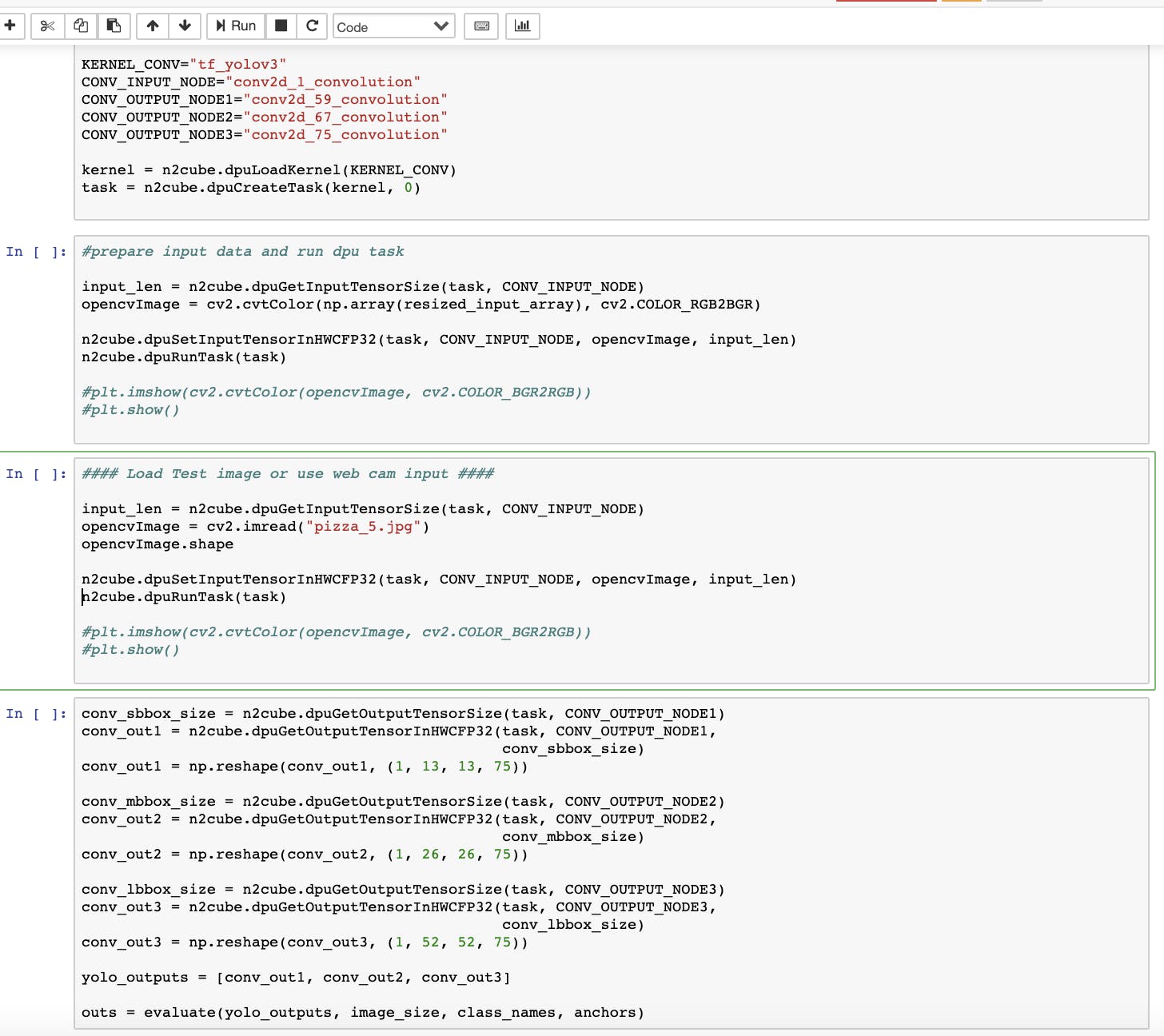
为 Yolov3 网络加载锚点。Yolov3 使用一组固定的锚点来生成边界框。这些锚点用于评估函数。

评估函数将 Yolov3 输出转换为框、类和分数。这是必需的,因为所有其他步骤都需要边界框格式的输出。
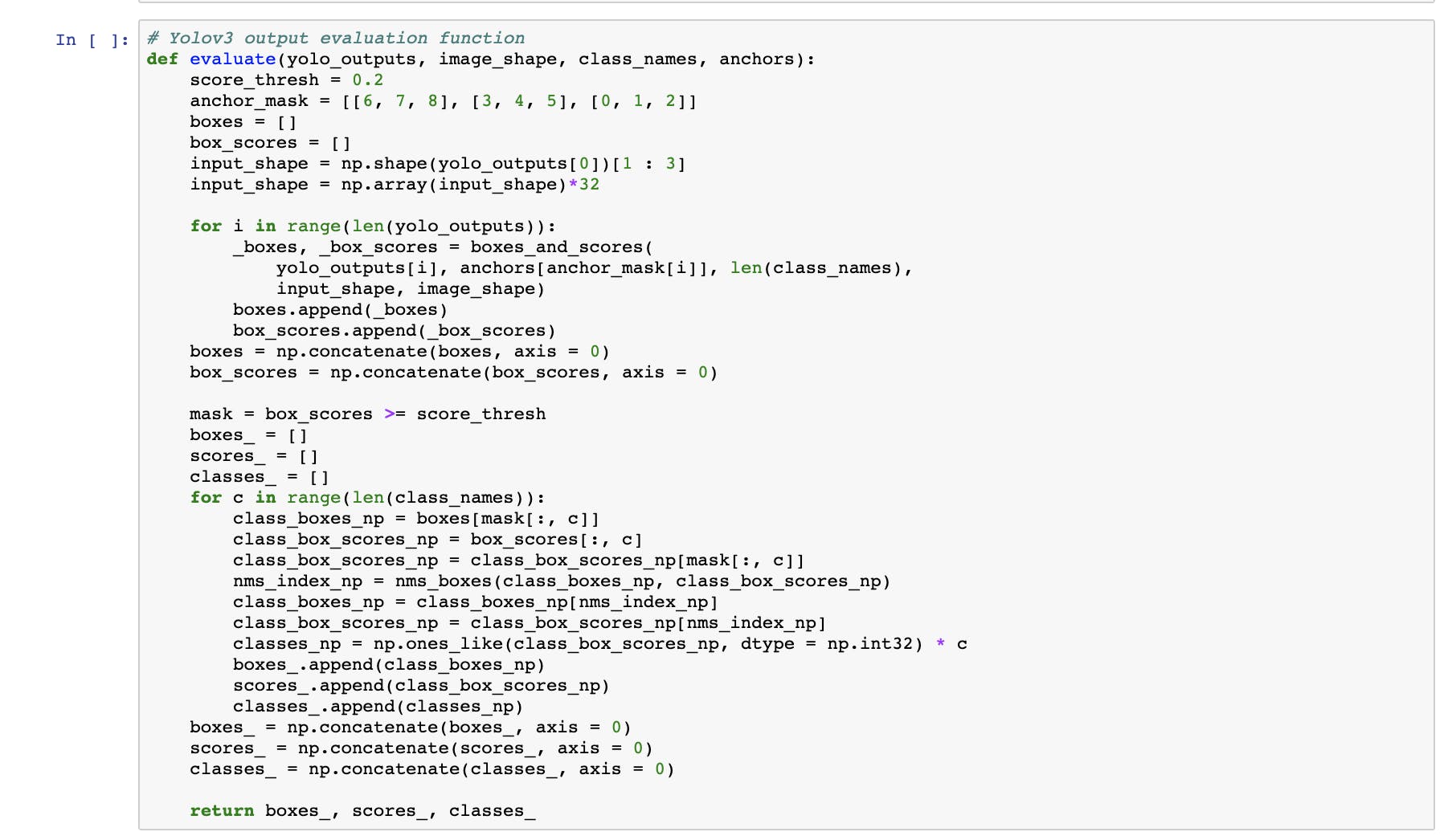
用于相机输入和投影仪输出的 HDMI 设置。该代码与 PYNQ HDMI 接口兼容。此时可以设置自定义输入/输出。
第一步中裁剪来自相机的输入图像,以选择感兴趣区域 (ROI)。我的 GoPro 摄像机输出 720p 图像,因此 ROI 设置为 440 x 440 像素,裁剪是在软件中完成的。如果您的相机没有固定在投影仪上,并且需要进行一些调整以使比萨饼适合 ROI 中间,这将非常有用。ROI 图像数据被传输到 FPGA 图像缩放器,数据传输由一些 DMA 任务完成。为了启用从 python 内存到 PL 内存的数据传输,使用了 pynq.buffer。PL 图像缩放器的输出用作 DPU 输入。PL resizer 的源代码来自这个PYNQ-Helloworld GitHub repo. PL resizer 可以处理自定义输入/输出图像,输入/输出图像的设置可以通过寄存器进行设置。必须设置四个寄存器值: 0x10:输入图像高度;0x18 输入图像宽度;0x20 输出图像高度;0x28 输出图像宽度

DPU init 和 DPU Task 启动。评估函数将原始 Yolov3 网络输出转换为边界框格式。
评估函数的输出被传递到排序过程。重复的比萨检测被删除,只使用比萨的最高置信度。如果置信度高于 0.5,则使用 Pepperoni 检测。
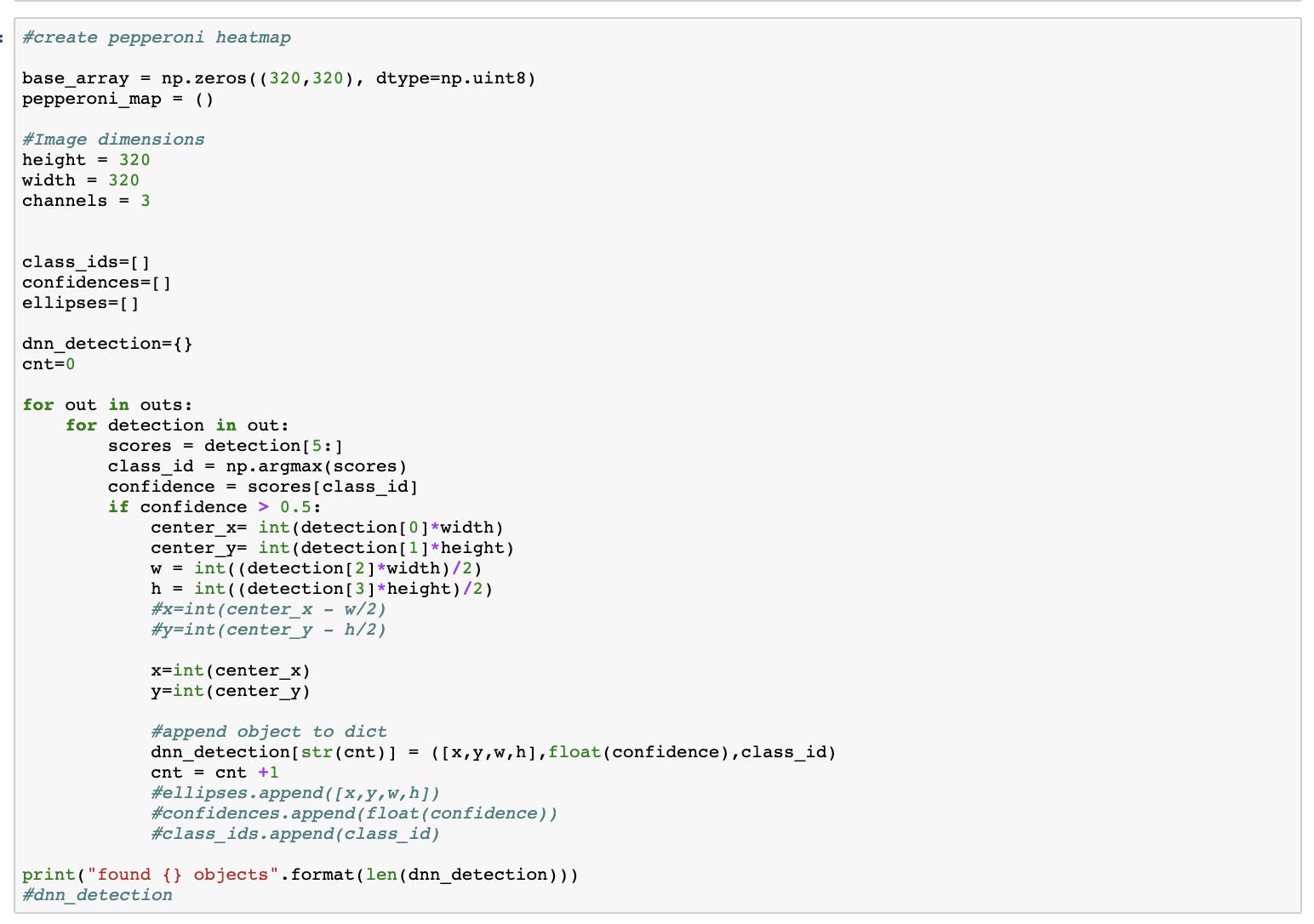
基于排序过程,在 320 x320 uint8 数组中绘制了一个虚拟披萨。边界框坐标用于在边界框内绘制一个椭圆。椭圆的内部用 1 填充,外部用 0 填充。每个意大利辣香肠近似值都添加到 320 x 320 基本数组中。基本数组元素是一个披萨边界框近似。披萨基数组之外的意大利辣香肠检测将被忽略。结果是一个意大利辣香肠热图。
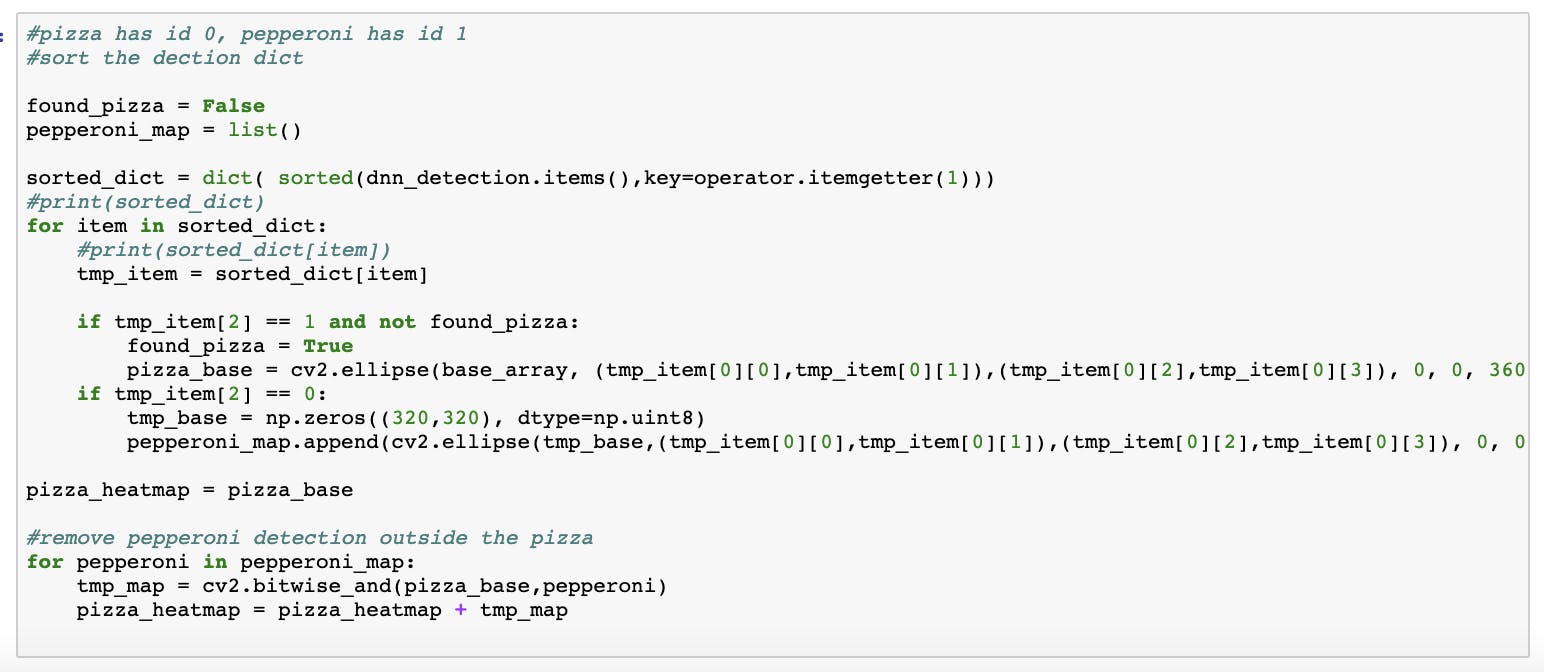
意大利辣香肠热图,覆盖意大利辣香肠切片也被模拟(较亮的区域)。这就是为什么使用对象检测网络而不是分割网络的原因之一。使用目标检测网络和椭圆区域近似覆盖意大利辣香肠可以进行模拟。
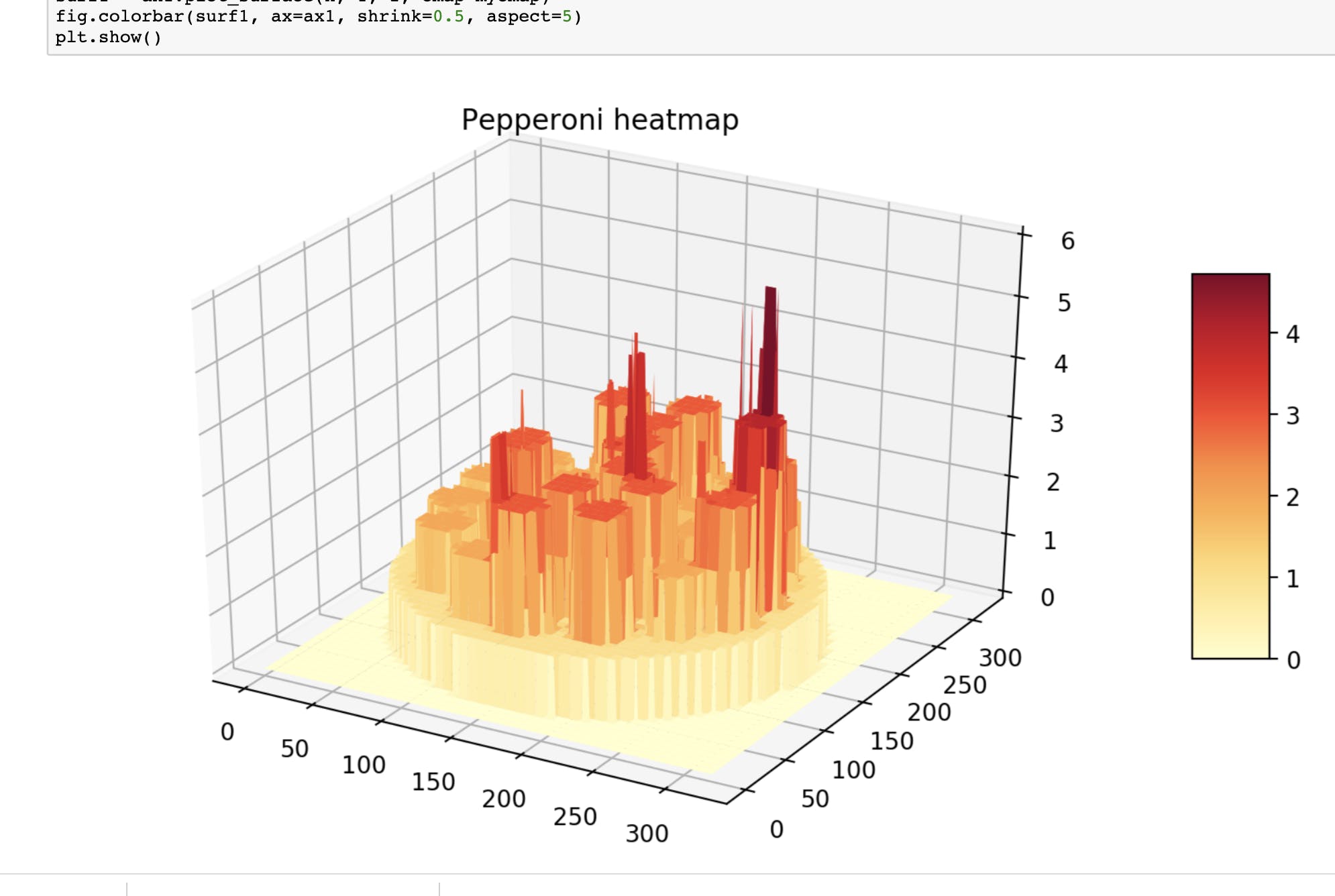
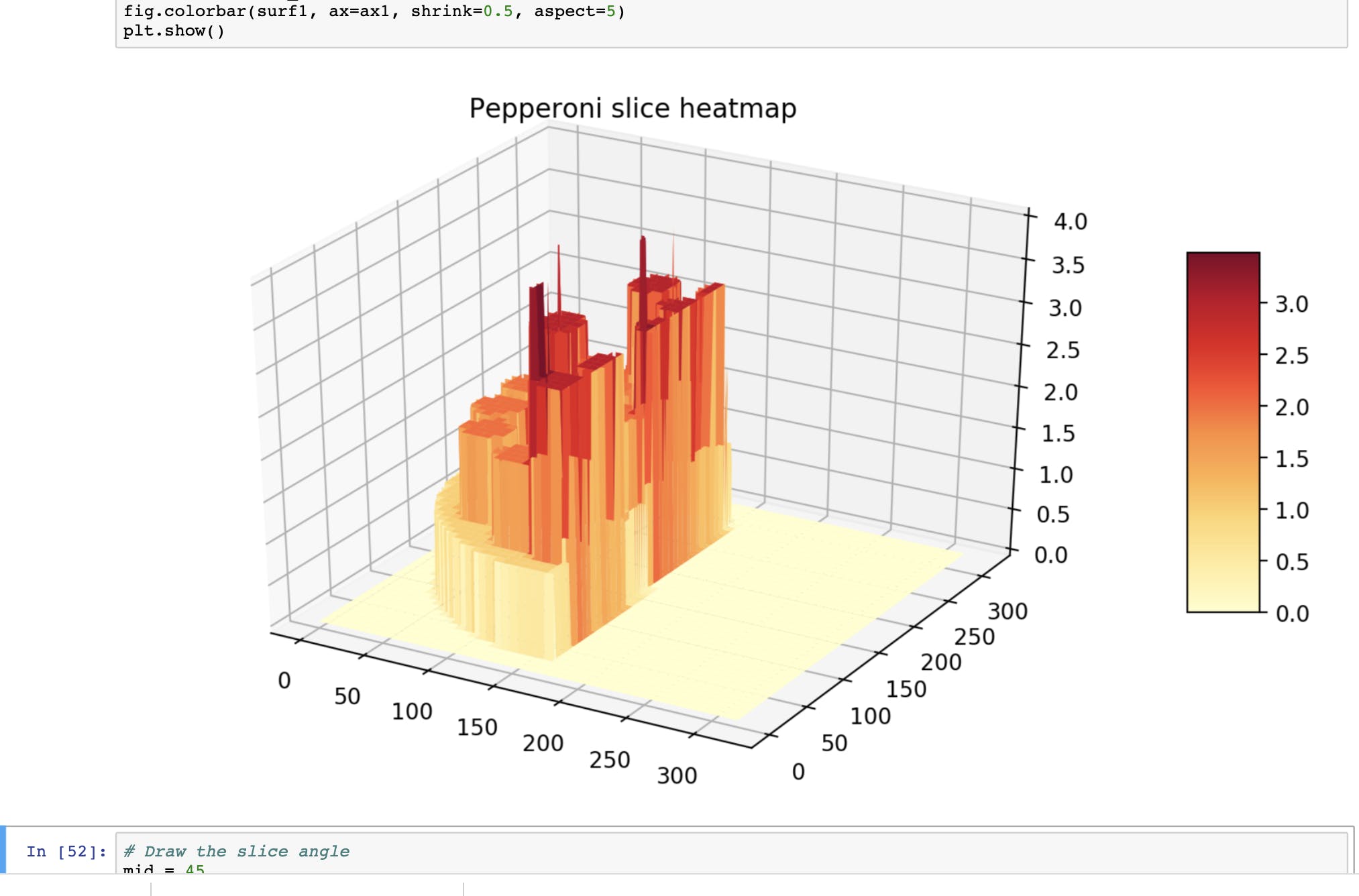
3D 意大利辣香肠热图,重叠的意大利辣香肠区域被绘制为尖峰。该图非常清楚地显示了在椭圆区域近似和层添加之后如何组合热图数据。
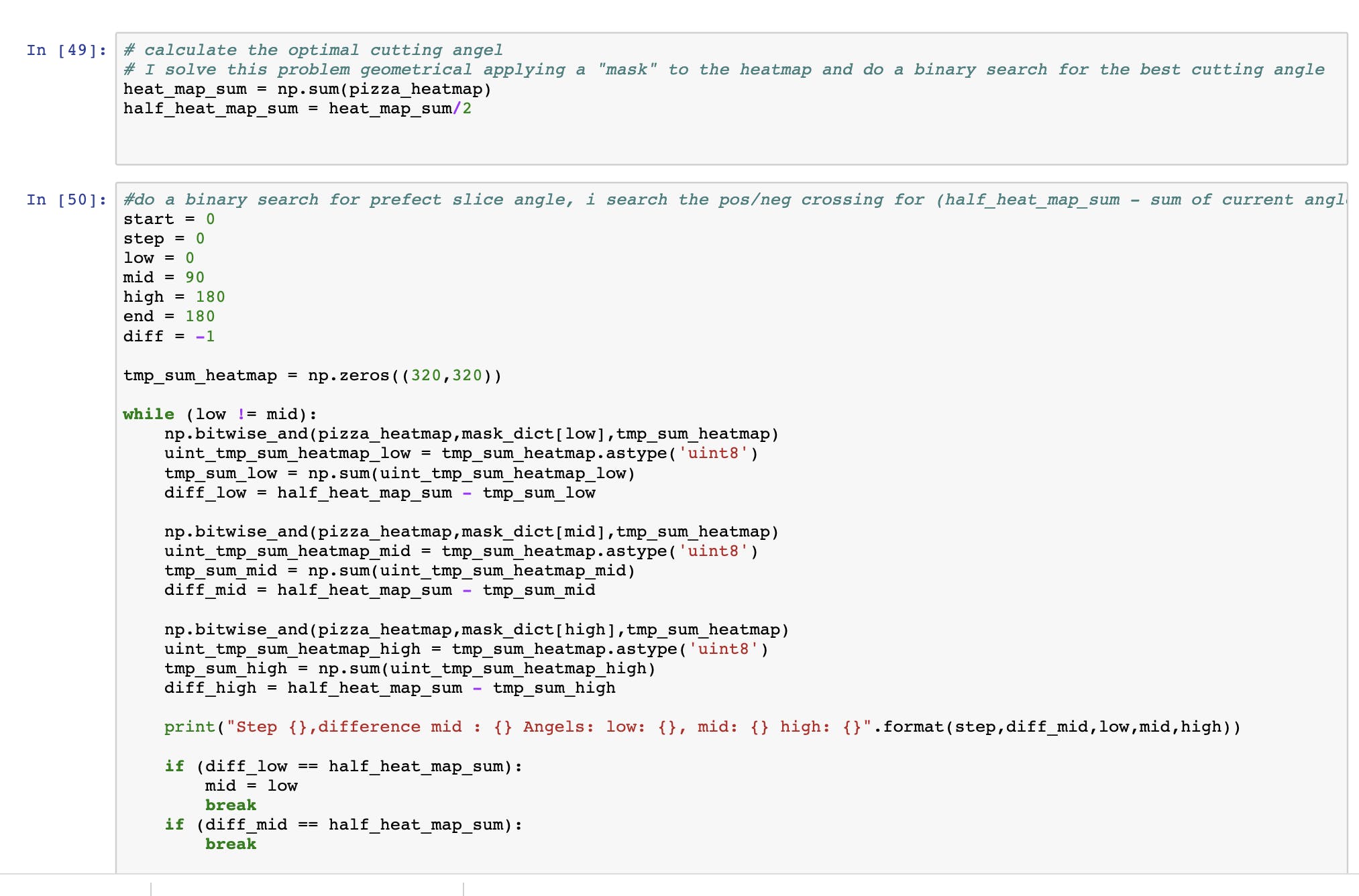
在计算意大利辣香肠热图后,必须定义最佳切割角度。这个问题是通过对意大利辣香肠热图应用蒙版来解决的。掩码将热图值的一半设置为零。应用掩码后,所有元素都被汇总。该值与原始意大利辣香肠热图中的所有元素的一半进行比较。二分搜索算法试图最小化从掩码总和到半热图总和的差异。我使用了我们只需要从 0 到 180 度搜索的事实,因为掩码围绕数组的中心旋转。这种搜索非常有效,并且极大地减少了计算次数。
3D 最佳切割角度的可视化
在最后一步中,计算“Cut Here”的输出图像和切割箭头。
设置


声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章







