
资料下载


用微语音控制交通灯
申换换
分享资料个
描述
介绍和动机
机器学习通常涉及大量计算能力,这些计算能力通常以带有 GPU 的大型数据中心的形式出现,训练深度神经网络的成本可能是天文数字。小至 14 KB 的微型神经网络的出现为新应用打开了大量大门,这些应用可以直接在微处理器本身上分析数据并得出可操作的见解(Warden 和 Situnayake,2019 年)。这可以节省时间并防止延迟,因为我们不必将数据传输到云数据中心进行处理并等待其返回(Warden 和 Situnayake,2019 年)。这种现象称为边缘计算,允许在存储数据的设备上处理和计算数据(Lea,2020)。
学习过程:模型训练
首先,在我开始这个项目之前,我不知道边缘计算或 Arduino 是什么。正如技术列表所示,我必须使用并协调整个工具生态系统,才能实现在运行良好的 Arduino 板上部署语音识别的目标。
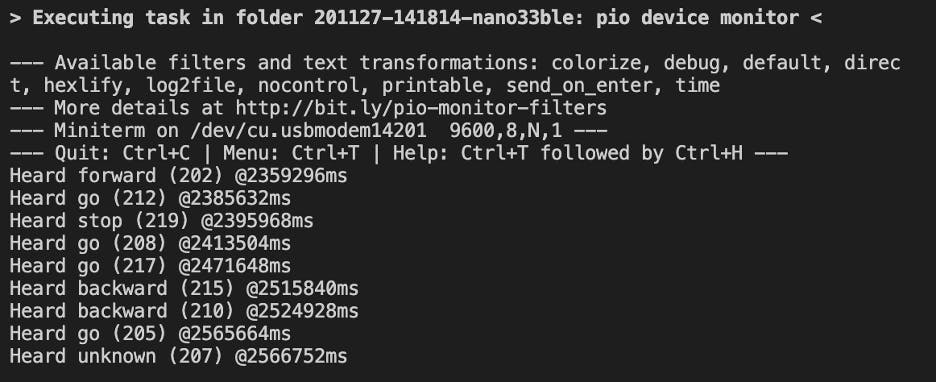
我做的第一件事是下载 VS Code IDE 并确保安装了 Platform IO 扩展。同时,我必须下载 Arduino IDE 并包含 TensorFlow Lite 库。在 VS Code 中,我从 Arduino IDE 导入了内置的微语音示例,作为一个运行良好的示例。该模型接收到“yes”的输入,打开 Arduino 上的绿色 LED;“否”打开了 Arduino 上的红色 LED;所有其他打开 Arduino 上的蓝色 LED 的单词;或没有打开 LED 的静音。
TensorFlow 已经在其 GitHub 存储库中提供了训练脚本:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/micro_speech/train/train_micro_speech_model.ipynb。
这个脚本也是我想如何为我的特定用例训练微语音模型的基础。
我最初开始将训练脚本从 TensorFlow 版本 1.x 转换为 2.x,因为后者的性能优化和简化的 API 调用。但是,我无法转换整个脚本,因为在 TensorFlow v2 中没有等效于 v1 的“tf.lite.constants.INT8”模块。
修改这个脚本实际上是一个巨大的挑战。主要因素是因为每当我对模型进行更改时,都需要大约 2 个小时来训练,所以我选择的超参数没有快速和即时的反馈。我无法通过经常试验和操纵许多参数来执行“快速原型设计”。我遇到的最令人抓狂的问题是,当我在 TensorFlow 中训练模型后,当我尝试量化模型并从中生成 TensorFlow Lite 模型时,我会收到如下错误消息:
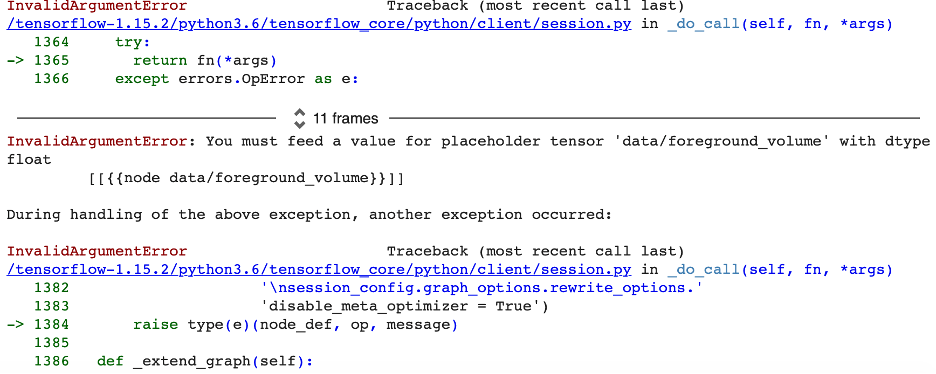
我对此进行了大量研究,结果发现这很可能归因于我每次在 Colab 单元中运行代码片段时创建的嵌套图,因此新占位符无法获得所需的输入值在评估阶段。每次我重新运行我的训练脚本来训练微语音模型时,我都通过重新启动我的 GPU 来解决这个问题。
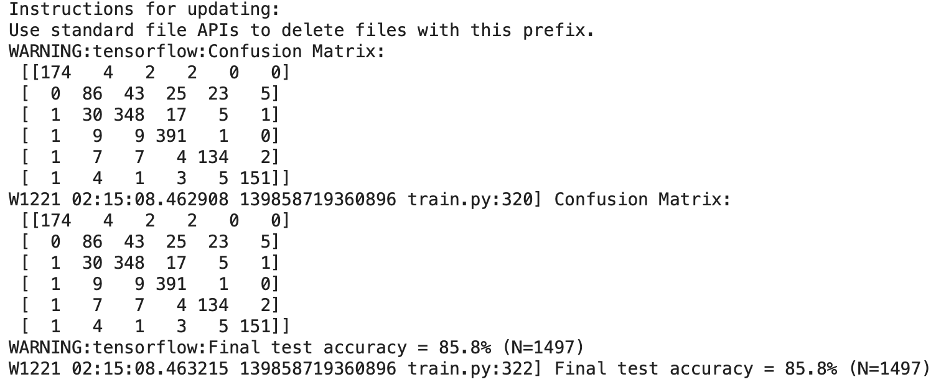
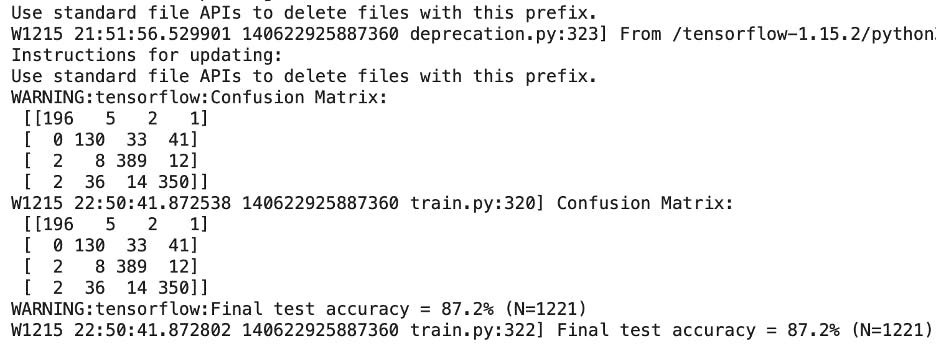
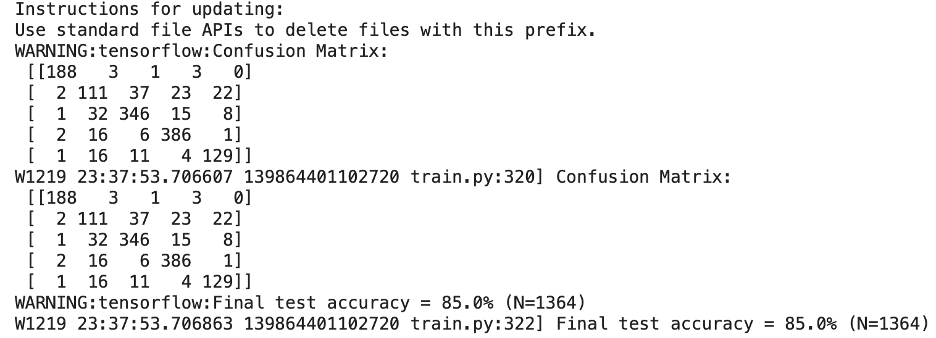
通过使用“go”和“stop”进行训练,我的模型得到的初始准确率为 87.2%,因此我认为可以通过将训练步数从 15,000 次迭代增加到 25,000 次来改进它。我也很愚蠢同时 tweeked 另一个变量是模型将识别的唤醒词的数量,因为我在列表中添加了“向后”和“向前”。
我用 25, 000 步训练的模型的准确度实际上下降到了 85%。花了几乎两倍的时间,3.5 小时,但准确度下降了!造成这种情况的原因可能有两个:1)混淆矩阵变大,必须识别更大的词向量并对更大的词向量更敏感,因此准确率下降;2)峰值性能实际上是在 15,000 个训练步骤,模型进入收益递减阶段。
我用两个额外的唤醒词回到最初的 15,000 个训练步骤,我的模型的最终准确率为 85.8%。因此,从这个结果中,我可以得出一个结论,即最有可能达到峰值性能需要用 15,000 步进行训练。
从我之前在课堂上的作业来看,0.001 和 0.0001 的学习率产生了具有最高准确度的模型,所以我用它们来训练我的模型。
我所做的其他调整是模型的实际架构。有几个可供选择,其中包括一个全尺寸的卷积神经网络。我最初选择了 MODEL_ARCHITECTURE = 'conv' 并尝试将该模型部署到我的 Arduino。结果是模型太大,Arduino 无法处理,所以每当我试图在麦克风中说出唤醒词时,它都会抛出一堆“请求失败”错误而关闭。之后我了解到,Arduino 可以处理的唯一模型架构是其中包含“tiny”一词的架构,例如效果最好的“tiny_conv”和“tiny_embedding_conv”。这些模型架构已经预先打包在训练脚本中并可以使用。
“tiny_conv”模型有一个卷积层,然后是一个具有 4 x 4000 权重的全连接层,最后一层是 softmax 层。
我选择用来训练模型的词多种多样。该模型从识别“是”和“否”开始,它们之间的区别足够大,与“开”和“关”等其他词对相比,它们不容易混淆。然后我决定添加“前进”和“后退”,使这个模型像交通信号/停车信号一样。当说出“STOP”或“BACKWARD”时 LED 会变为红色,当说出“GO”或“FORWARD”时 LED 会变为绿色。如果说出不属于这四个类别中的任何一个的单词,LED 将变为蓝色。沉默根本不会打开 LED。
微语音模型本质上是将传给麦克风的音频输入转换为频谱图,然后通过 TensorFlow Lite 运行它以对说出的单词进行分类。一旦模型完成训练,训练脚本就会生成一个名为 model.cc 的二进制模型文件。此二进制文件中的数据将使用脚本训练的模型和模型的二进制长度编码到一个名为 micro_features_model.cpp 的文件中。
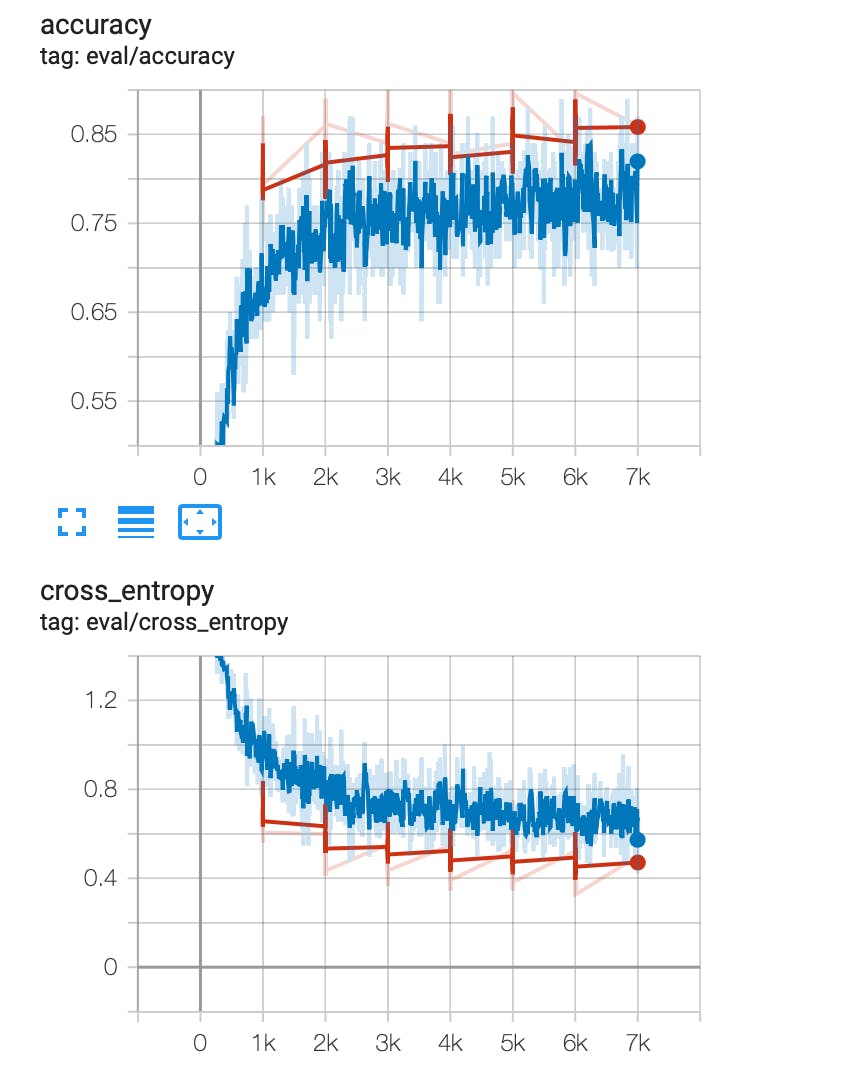
我使用 TensorBoard 来显示准确度和交叉熵的进展,它们应该分别增加和减少。红线指的是验证数据集上的性能,它定期发生,因此数据点稀疏。蓝线指的是训练数据集上的性能,它经常出现,所以这些线更接近。
除了“未知”和“沉默”之外,还有一个名为 kCategoryCount 的变量表示模型需要分类的词数。对于我的特定用例,kCategoryCount 等于 6。
学习过程:部署到 Arduino
到目前为止,我刚刚讨论了训练模型并使其达到尽可能高准确度的挑战。下一个障碍是将这个模型部署到 Arduino。
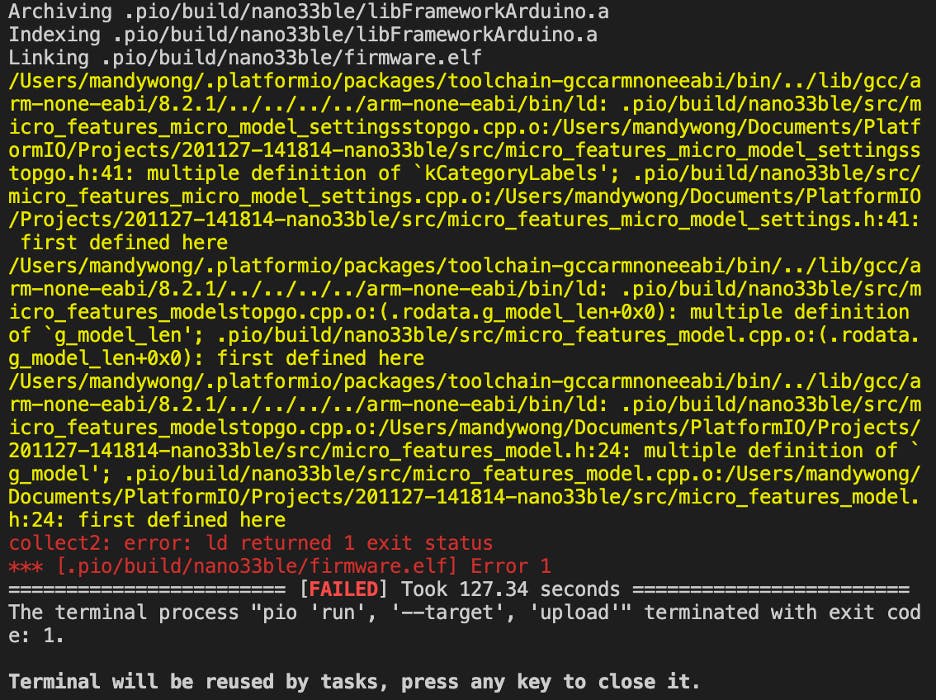
困扰我的最大挑战是一个错误,说我在项目文件夹中定义了两次模型。我花费了大量时间梳理所有不同的文件以解决该错误。事实证明,我忘记删除旧的#include 语句,该语句引用的模型与我试图部署到 Arduino 的模型不同。为了避免将来混淆,我给我的模型取了一个简单的名称,并删除了与另一个模型相关的任何其他文件。我只是清理了我的项目文件夹并选择了极简主义。错误如下所示。
一旦我清除了这个障碍,我很快就被另一堵砖墙迎接了。该程序能够编译,但我无法将其上传到 Arduino。我得到的错误是没有检测到上传端口,所以我无法将模型上传到 Arduino。我非常焦虑,因为我认为是我的 MacBook Pro 出现问题并且无法检测到外部设备。我通过将 USB 插入它来测试这个理论,看看它是否会识别它,事实上它确实做到了。我只能摸不着头脑,将开发转移到我的 Windows 计算机上。在将我的模型部署到 Arduino 之前,一切都按预期工作。我得到了完全相同的错误,然后我开始非常担心。我的 Arduino 会坏吗?寄给我的是有缺陷的吗?我什至从 Windows 7 移动到 Windows 10 并得到了同样的错误!这变得非常令人担忧。最后要检查的是我的微型 USB 电缆。我用过旧的微型 USB 来为我的 Android 手机充电。这实际上是最后一个要改变的变量。如果切换我的微型 USB 电缆仍然不允许我将模型上传到 Arduino,我只能写下我无法上传模型的原因。
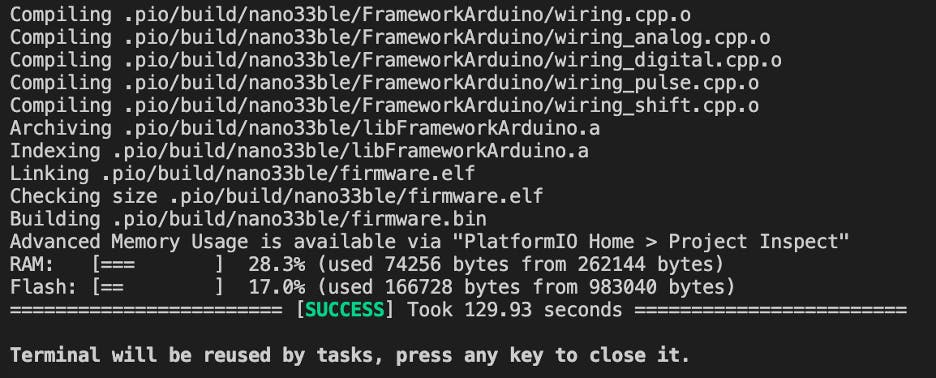
我在下面的屏幕截图中显示了我的编译成功但上传失败。
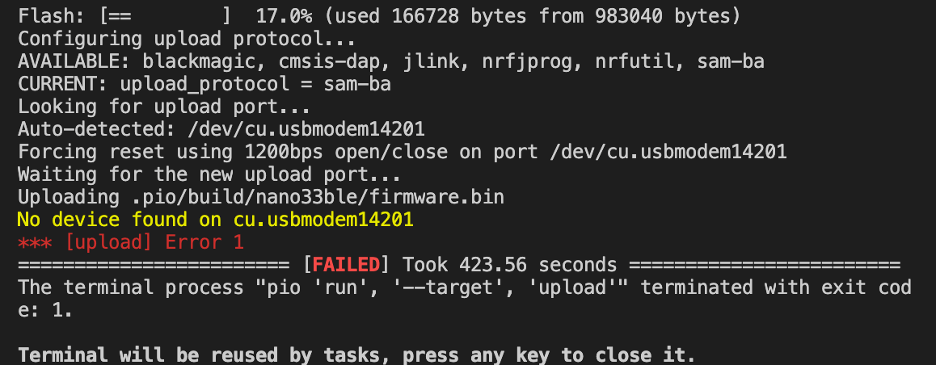
我将我的微型 USB 电缆换成了另一根更长且不是专门为手机充电的电缆……这是惊人的结果!
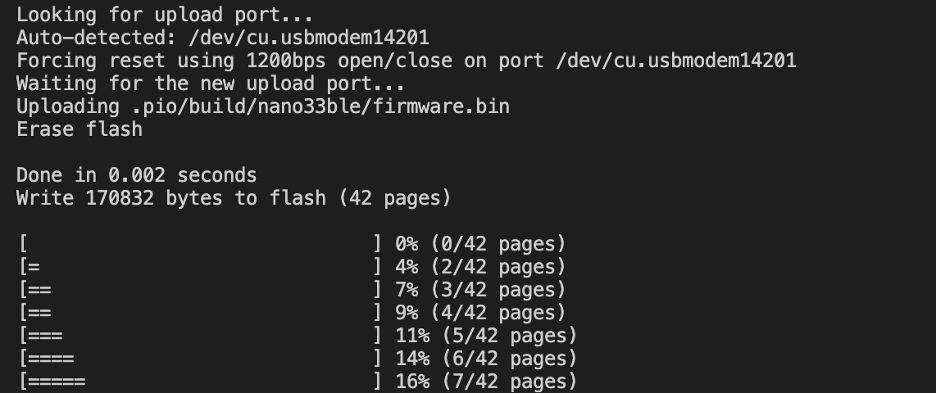
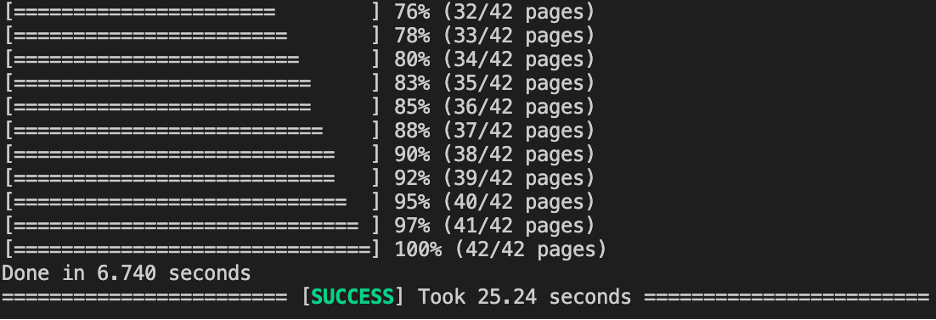
事实证明,无法检测到上传端口的原因是因为微型 USB 电缆有问题!我再放心不过了。
在部署到 Arduino 时解决了这两个问题后,我现在可以自由地将模型部署到它。端口错误确实出现了,但这次我找到了 Arduino 推荐的快速解决方案:“如果板子没有进入上传模式,请在启动上传过程之前双击重置按钮; 橙色 LED 应该会慢慢淡入淡出,表明开发板正在等待上传。” 在 Arduino 上执行此重置操作可解决任何端口检测错误。
更多研究还建议在上传之前对构建文件进行清理,如此屏幕截图所示。
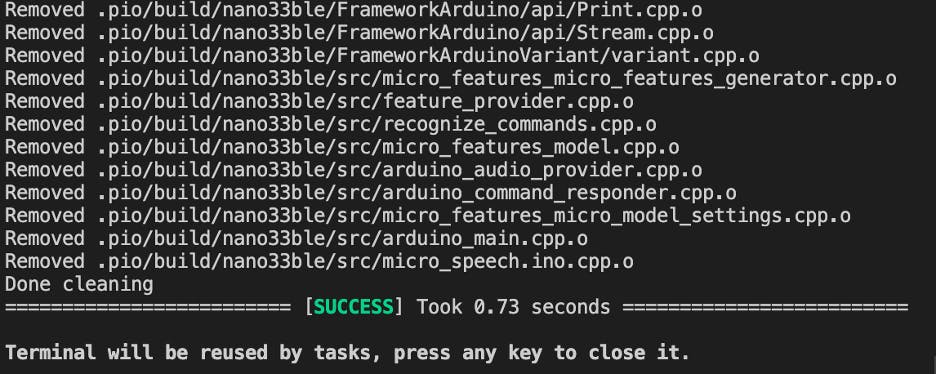
学习这些漂亮的技巧将使我进入与 Arduinos 合作的下一阶段。
未来的工作
能够在 Arduino 上部署微型深度学习模型彻底改变了物联网和边缘计算的功能。由于成本的显着降低,可能性是无穷无尽的。由于模型的准确性可能会更好,因此仍有很多改进工作要做。提高准确性在某种程度上仍然是一项黑盒活动,尤其是在使用此类新技术的情况下,因此通过操纵多个参数进行彻底的实验将使我们更接近更好的模型。这个特定模型的音频输入非常简单,下一个合乎逻辑的举措是训练并使用完整的短语来控制 Arduino,无论它仍然打开不同颜色的 LED 灯,还是让它以另一种方式响应。尽管在这个阶段,Arduino 上的实现更多的是 POC,而不是可扩展或大规模工业生产,但它让我们对这个新的前沿领域有所了解。利用算法简化的力量,我们可以将这些 POC 提供的解决方案堆叠和组合在一起,以解决与安全相关的更难、时间敏感的问题,例如机器人手术或自动驾驶汽车。
参考
Lea, P. (2020)。面向建筑师的物联网和边缘计算——第二版。O'Reilly 电子书[在线]。网址为:https ://learning.oreilly.com/library/view/iot-and-edge/9781839214806/ (访问日期:2020 年 12 月 14 日)。
Warden, P. 和 Situnayake, D. (2019)。TinyML。O'Reilly 电子书[在线]。网址为:https ://learning.oreilly.com/library/view/tinyml/9781492052036/ (访问日期:2020 年 11 月 10 日)。
监狱长,P.(2017 年)。启动语音命令数据集[在线]。网址为:https ://ai.googleblog.com/2017/08/launching-speech-commands-dataset.html (访问日期:2020 年 12 月 5 日)。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






