
资料下载


hash表的实现原理
分享资料个
软件开发中,一个hash表相当于把n个key随机放入到b个bucket中,以实现n个数据在b个单位空间的存储。
我们发现hash表中存在一些有趣现象:
hash表中key的分布规律
当hash表中key和bucket数量一样时(n/b=1):
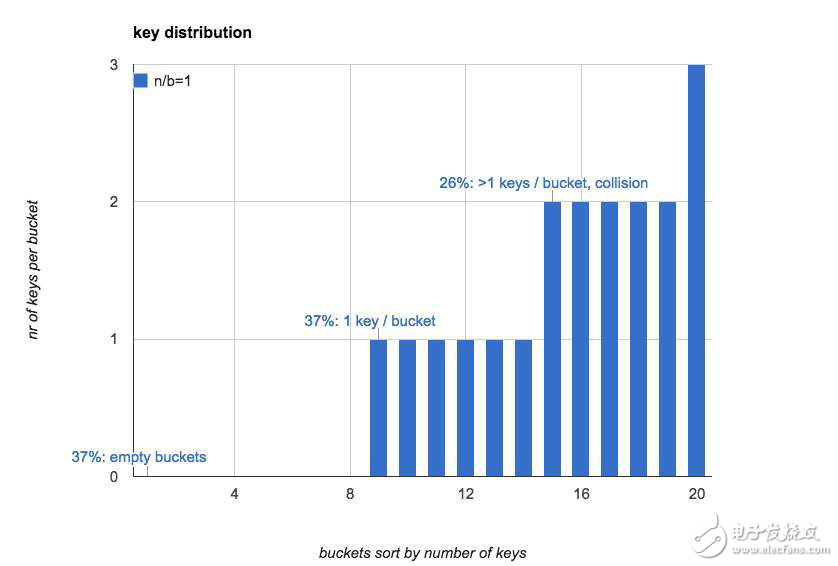
37% 的bucket是空的
37% 的bucket里只有1个key
26% 的bucket里有1个以上的key(hash冲突)
下图直观的展示了当n=b=20时,hash表里每个bucket中key的数量(按照key的数量对bucket做排序):
往往我们对hash表的第一感觉是:如果将key随机放入所有的bucket,bucket中key的数量较为均匀,每个bucket里key数量的期望是1。
而实际上,bucket里key的分布在n较小时非常不均匀;当n增大时,才会逐渐趋于平均。
key的数量对3类bucket数量的影响
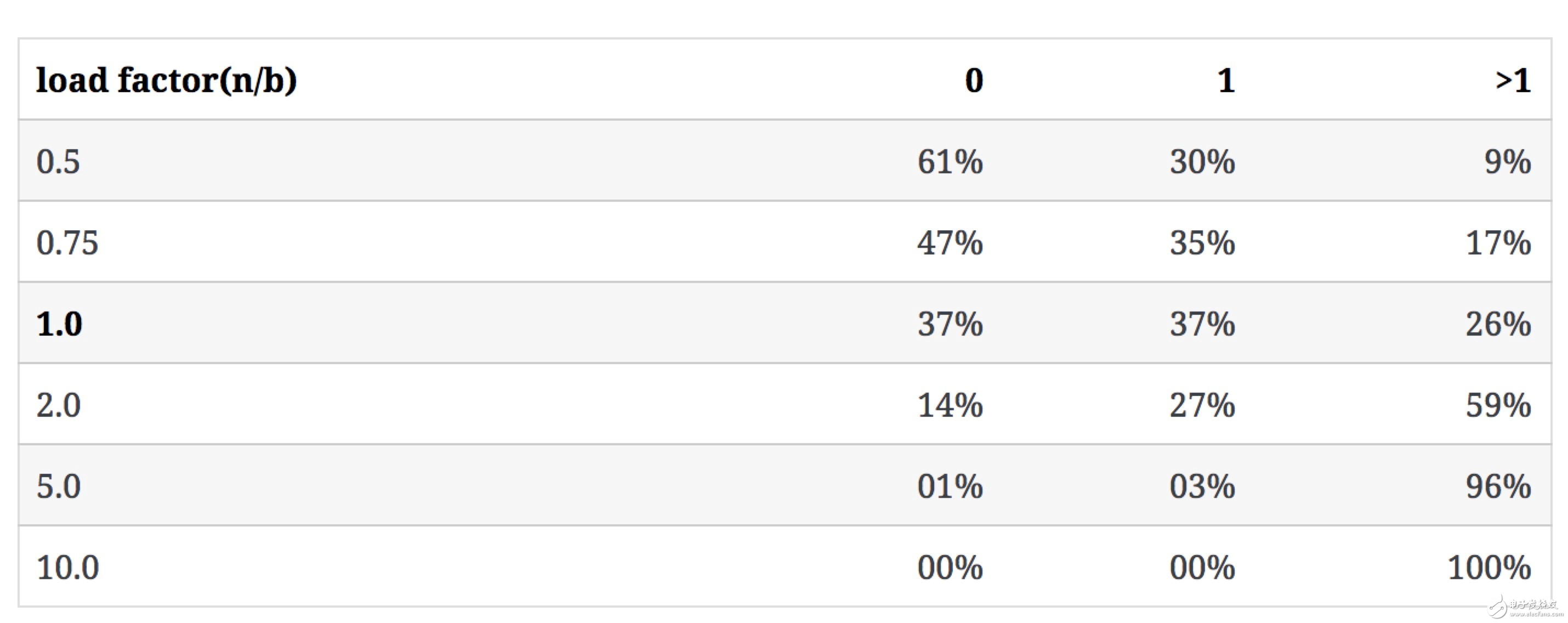
下表表示当b不变,n增大时,n/b的值如何影响3类bucket的数量占比(冲突率即含有多于1个key的bucket占比):
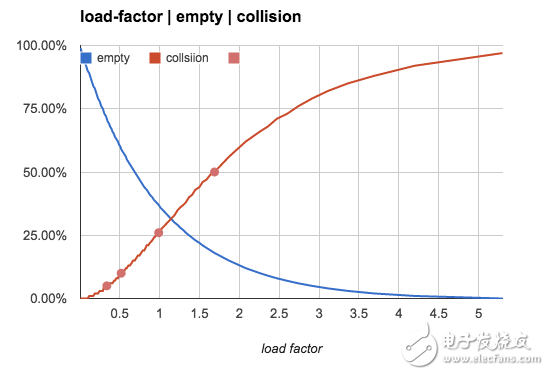
更直观一点,我们用下图来展示空bucket率和冲突率随n/b值的变化趋势:
key数量对bucket均匀程度的影响
上面几组数字是当n/b较小时有意义的参考值,但随n/b逐渐增大,空bucket与1个key的bucket数量几乎为0,绝大多数bucket含有多个key。
当n/b超过1(1个bucket允许存储多个key), 我们主要观察的对象就转变成bucket里key数量的分布规律。
下表表示当n/b较大,每个bucket里key的数量趋于均匀时,不均匀的程度是多少。
为了描述这种不均匀的程度,我们使用bucket中key数量的最大值和最小值之间的比例((most-fewest)/most)来表示。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





下载排行榜
- 暂无相关数据

