
资料下载


大数据分析平台构建实录
分享资料个
在数据分析中,有超过90%数据都是来自于非结构化数据,其中大部分的是日志,如运维、安全审计、用户访问数据以及业务数据等,但随着互联网快速的发展,数据规模也是水涨船高,从早前的GB级到现在的TB级,甚至PB级也只是短短几年光景。而移动互联网的时代到来,可以说每个人无时无刻不在产生数据,几乎成爆发式的增长。
如此多的数据早已压榨完单机的性能,在性价比的驱使下,转向分布式也是多数互联网企业早就未雨绸缪的事。2016年恰逢Hadoop十周年,可以说Hadoop改变了企业对数据的存储、处理和分析的过程,并引燃了整个大数据生态圈,而构建企业级大数据分析平台也必不可少从它开始。
一、基石-Hadoop
Hadoop2.0之后,资源管理被剥离了出来,变成了YARN。虽然在集群规模小于200台的企业里,可能不能感受到YARN带来的过多优势,但是与MRv1相比,其已不再是单纯的计算框架(Mapreduce),而是一个框架管理器,可以部署多个计算框架(如Spark,Storm,Impala等),NoSQL存储(如HBase等)。
HDFS是Hadoop的分布式文件系统,多数的计算框架都支持直接从HDFS上读取数据,且可以无障碍的部署在低廉的服务器上,Replication机制也保证了数据容灾性。但有些场景也不适合使用,如低延迟数据访问、大量小文件存储等,但可以依赖其他框架解决,如HBase、Alluxio解决低延迟访问、FastDFS解决大量小文件存储的问题,mmTrix的真机监测就是通过FastDFS来解决存储真机客户端大量回传的几KB小文件。
二、快刀-Spark、Mapreduce、Storm、Spark Streaming
很多人觉得Spark的出现,可以完全替代Mapreduce,尽管Mapreduce很优秀,编程模型简单,但是真的太慢了(前公司的BI人员多次吐槽,敲完一条连表HiveSQL,他可以看一集火影)。Spark目前正朝着2.0大步迈进,从目前最新的1.6版本来看,上千个补丁完全可以看出Spark正如其名一般的火爆。Spark 1.6引入新的内存管理器,自动调整不同内存区域大小,根据程序运行时自动地增加或缩小相应内存区域大小,这意味着对许多应用程序来说,在无需手动调整的情况下,在进行join和aggregation等操作时,其可用的内存将大大增加。
尽管Spark如此优秀,但是在日级别、部分业务小时级的数据计算时,我们依旧选择Mapreduce,但对于分钟级的计算已经将这光荣的任务移交给Spark。
Storm作为开源实时框架的先驱,在提到实时计算的时候,会第一反应想到它,尽管twitter公司已经宣布弃用,改用Heron。从Twitter在SIGMOD 2015上发布的论文来看,Heron可以说有非常不错的提升,Twitter也表示在将来会开源。而阿里的JStorm在2015年10月份也加入了Storm的豪华午餐,应该会出现在下个大版本里。我们部署了JStorm2.1.0进行了测试,发现JStorm表现出非常不错的性能,仅从监控UI就能看出阿里对于JStorm的诚意,但最重要的是JStorm解决了Storm的几个问题,如过度依赖Zookeeper(频繁交互Zookeeper)、HA、多集群监控、资源硬隔离等。
而Spark Streaming则是目前我们正在过渡到的一个实时计算框架,Spark Streaming与Storm在处理数据的本质上有着很大的不同,Storm是逐个处理tuple,而Spark Streaming则可看成细粒度批处理(micro batch)的spark任务,但这也决定了其高吞吐量和较高的延迟。一般认为Storm的处理瓶颈是单条流水线20000Tuple/s(每个tuple大小为1KB),但在一些大数据量且延迟要求不高的场景下,其实Spark Streaming可能更适合,目前mmTrix也准备将静态CDN访问日志相关的秒级监控迁到Spark Streaming。
三、辅助-Kafka、OpenTSDB、Kylin
Kafka为LinkedIn开源的优秀分布式发布订阅消息系统,即便是廉价的服务器也能跑出单机10W/s的效率。Kafka解藕了服务的同时,对消费端消费能力不足的情况下,实现了数据缓冲,并且消费不删除和Retention机制也提高了其在实践中的高可用。即便在后端消费服务全部宕机的情况下,Kafka也能默默承载全部数据压力,并给予运维、开发人员修复的时间(取决于配置项log.retention.hours)。
由于mmTrix是主要做APM业务的,不可避免地会遇到时间序列的监控数据,如OS监控、Plugin监控、Server监控等业务。早期的做法,选择了Mongo作为存储工具,但最终我们还是选择了HBase,并配合OpenTSDB使用。OpenTSDB主要由Time Series Daemon (TSD)以及一系列的命令工具组成。每个TSD都是独立的,它们之间没有Master,没有共享状态,从而在使用的时候可以部署任意多个,且相互之间不影响。数据的存储主要依托开源的列存储数据HBase,按时间序列存储。与TSD之间的数据交互,可以通过简单的telnet-style协议,比如HTTP API或者内建的GUI。时间序列的数据是高密集的,如果设计HBase Rowkey时,只注重在时间尺度上的Scan且把全时间带入到Rowkey中,当大规模灌入数据的时候是极易引起Region热点问题的。
而OpenTSDB的Rowkey设计巧妙的规避了这个问题,采用固定长度的Rowkey,让Rowkey包含尽可能多的检索信息。同时,其使用AsyncHbase而非HBase自带的HTable,且线程安全、非阻塞、异步、多线程并发的HBase API,在高并发和高吞吐时,可以获得更好的效果。
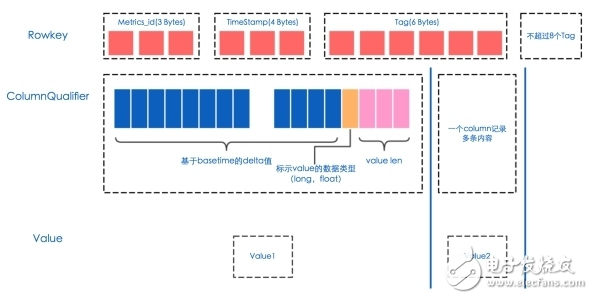
Kylin是eBay开源给Apache的OLAP平台,并于2015年12月8日成为Apache顶级项目。对于需要长期建立的数据分析仓库,在不同的时间弹性尺度上聚合结果是比较耗时的,而用户经常要求在秒级返回结果,OLAP平台正好解决这个问题。同时,mmTrix的技术支持和OP人员也需要快速的帮助客户排查一些问题或者快速制作分析报表。Kylin目前来看使用的限制较多,对于其依赖的组件Hive、HBase、Hadoop有一定限制,而且目前使用的公司还较少(京东云海分享过使用经验),mmTrix目前也在试水。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




下载排行榜
- 暂无相关数据

