
资料下载


×
FM和FFM原理的探索和应用的经验
消耗积分:1 |
格式:rar |
大小:0.4 MB |
2017-10-12
分享资料个
FM和FFM模型是最近几年提出的模型,凭借其在数据量比较大并且特征稀疏的情况下,仍然能够得到优秀的性能和效果的特性,屡次在各大公司举办的CTR预估比赛中获得不错的战绩。美团点评技术团队在搭建DSP的过程中,探索并使用了FM和FFM模型进行CTR和CVR预估,并且取得了不错的效果。本文旨在把我们对FM和FFM原理的探索和应用的经验介绍给有兴趣的读者。
前言
在计算广告领域,点击率CTR(click-through rate)和转化率CVR(conversion rate)是衡量广告流量的两个关键指标。准确的估计CTR、CVR对于提高流量的价值,增加广告收入有重要的指导作用。预估CTR/CVR,业界常用的方法有人工特征工程 + LR(Logistic Regression)、GBDT(Gradient Boosting Decision Tree) + LR[1][2][3]、FM(Factorization Machine)[2][7]和FFM(Field-aware Factorization Machine)[9]模型。在这些模型中,FM和FFM近年来表现突出,分别在由Criteo和Avazu举办的CTR预测竞赛中夺得冠军[4][5]。
考虑到FFM模型在CTR预估比赛中的不俗战绩,美团点评技术团队在搭建DSP(Demand Side Platform)[6]平台时,在站内CTR/CVR的预估上使用了该模型,取得了不错的效果。本文是基于对FFM模型的深度调研和使用经验,从原理、实现和应用几个方面对FFM进行探讨,希望能够从原理上解释FFM模型在点击率预估上取得优秀效果的原因。因为FFM是在FM的基础上改进得来的,所以我们首先引入FM模型,本文章节组织方式如下:
首先介绍FM的原理。其次介绍FFM对FM的改进。然后介绍FFM的实现细节。最后介绍模型在DSP场景的应用。
FM原理
FM(Factorization Machine)是由Konstanz大学Steffen Rendle(现任职于Google)于2010年最早提出的,旨在解决稀疏数据下的特征组合问题[7]。下面以一个示例引入FM模型。假设一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告。源数据如下[8]
Clicked?
Country
Day
Ad_type
1 USA 26/11/15 Movie
0 China 1/7/14 Game
1 China 19/2/15 Game
“Clicked?”是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。
Clicked?
Country=USA
Country=China
Day=26/11/15
Day=1/7/14
Day=19/2/15
Ad_type=Movie
Ad_type=Game
1 1 0 1 0 0 1 0
0 0 1 0 1 0 0 1
1 0 1 0 0 1 0 1
由上表可以看出,经过One-Hot编码之后,大部分样本数据特征是比较稀疏的。上面的样例中,每个样本有7维特征,但平均仅有3维特征具有非零值。实际上,这种情况并不是此例独有的,在真实应用场景中这种情况普遍存在。例如,CTR/CVR预测时,用户的性别、职业、教育水平、品类偏好,商品的品类等,经过One-Hot编码转换后都会导致样本数据的稀疏性。特别是商品品类这种类型的特征,如商品的末级品类约有550个,采用One-Hot编码生成550个数值特征,但每个样本的这550个特征,有且仅有一个是有效的(非零)。由此可见,数据稀疏性是实际问题中不可避免的挑战。
One-Hot编码的另一个特点就是导致特征空间大。例如,商品品类有550维特征,一个categorical特征转换为550维数值特征,特征空间剧增。
同时通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的。
多项式模型是包含特征组合的最直观的模型。在多项式模型中,特征 xi 和 xj 的组合采用 xixj 表示,即 xi 和 xj 都非零时,组合特征 xixj 才有意义。从对比的角度,本文只讨论二阶多项式模型。模型的表达式如下:
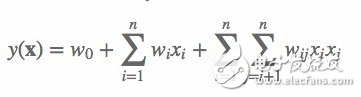
(1)
其中,n 代表样本的特征数量,xi 是第 i 个特征的值,w0、wi、wij 是模型参数。
从公式(1)可以看出,组合特征的参数一共有 n(n−1)/2 个,任意两个参数都是独立的。然而,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的。其原因是,每个参数 wij 的训练需要大量 xi 和 xj 都非零的样本;由于样本数据本来就比较稀疏,满足“xi 和 xj 都非零”的样本将会非常少。训练样本的不足,很容易导致参数 wij 不准确,最终将严重影响模型的性能。
那么,如何解决二次项参数的训练问题呢?矩阵分解提供了一种解决思路。在model-based的协同过滤中,一个rating矩阵可以分解为user矩阵和item矩阵,每个user和item都可以采用一个隐向量表示[8]。比如在下图中的例子中,我们把每个user表示成一个二维向量,同时把每个item表示成一个二维向量,两个向量的点积就是矩阵中user对item的打分。
前言
在计算广告领域,点击率CTR(click-through rate)和转化率CVR(conversion rate)是衡量广告流量的两个关键指标。准确的估计CTR、CVR对于提高流量的价值,增加广告收入有重要的指导作用。预估CTR/CVR,业界常用的方法有人工特征工程 + LR(Logistic Regression)、GBDT(Gradient Boosting Decision Tree) + LR[1][2][3]、FM(Factorization Machine)[2][7]和FFM(Field-aware Factorization Machine)[9]模型。在这些模型中,FM和FFM近年来表现突出,分别在由Criteo和Avazu举办的CTR预测竞赛中夺得冠军[4][5]。
考虑到FFM模型在CTR预估比赛中的不俗战绩,美团点评技术团队在搭建DSP(Demand Side Platform)[6]平台时,在站内CTR/CVR的预估上使用了该模型,取得了不错的效果。本文是基于对FFM模型的深度调研和使用经验,从原理、实现和应用几个方面对FFM进行探讨,希望能够从原理上解释FFM模型在点击率预估上取得优秀效果的原因。因为FFM是在FM的基础上改进得来的,所以我们首先引入FM模型,本文章节组织方式如下:
首先介绍FM的原理。其次介绍FFM对FM的改进。然后介绍FFM的实现细节。最后介绍模型在DSP场景的应用。
FM原理
FM(Factorization Machine)是由Konstanz大学Steffen Rendle(现任职于Google)于2010年最早提出的,旨在解决稀疏数据下的特征组合问题[7]。下面以一个示例引入FM模型。假设一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告。源数据如下[8]
Clicked?
Country
Day
Ad_type
1 USA 26/11/15 Movie
0 China 1/7/14 Game
1 China 19/2/15 Game
“Clicked?”是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。
Clicked?
Country=USA
Country=China
Day=26/11/15
Day=1/7/14
Day=19/2/15
Ad_type=Movie
Ad_type=Game
1 1 0 1 0 0 1 0
0 0 1 0 1 0 0 1
1 0 1 0 0 1 0 1
由上表可以看出,经过One-Hot编码之后,大部分样本数据特征是比较稀疏的。上面的样例中,每个样本有7维特征,但平均仅有3维特征具有非零值。实际上,这种情况并不是此例独有的,在真实应用场景中这种情况普遍存在。例如,CTR/CVR预测时,用户的性别、职业、教育水平、品类偏好,商品的品类等,经过One-Hot编码转换后都会导致样本数据的稀疏性。特别是商品品类这种类型的特征,如商品的末级品类约有550个,采用One-Hot编码生成550个数值特征,但每个样本的这550个特征,有且仅有一个是有效的(非零)。由此可见,数据稀疏性是实际问题中不可避免的挑战。
One-Hot编码的另一个特点就是导致特征空间大。例如,商品品类有550维特征,一个categorical特征转换为550维数值特征,特征空间剧增。
同时通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的。
多项式模型是包含特征组合的最直观的模型。在多项式模型中,特征 xi 和 xj 的组合采用 xixj 表示,即 xi 和 xj 都非零时,组合特征 xixj 才有意义。从对比的角度,本文只讨论二阶多项式模型。模型的表达式如下:
(1)
其中,n 代表样本的特征数量,xi 是第 i 个特征的值,w0、wi、wij 是模型参数。
从公式(1)可以看出,组合特征的参数一共有 n(n−1)/2 个,任意两个参数都是独立的。然而,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的。其原因是,每个参数 wij 的训练需要大量 xi 和 xj 都非零的样本;由于样本数据本来就比较稀疏,满足“xi 和 xj 都非零”的样本将会非常少。训练样本的不足,很容易导致参数 wij 不准确,最终将严重影响模型的性能。
那么,如何解决二次项参数的训练问题呢?矩阵分解提供了一种解决思路。在model-based的协同过滤中,一个rating矩阵可以分解为user矩阵和item矩阵,每个user和item都可以采用一个隐向量表示[8]。比如在下图中的例子中,我们把每个user表示成一个二维向量,同时把每个item表示成一个二维向量,两个向量的点积就是矩阵中user对item的打分。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章




下载排行榜
- 暂无相关数据

