
资料下载


×
基于双语LDA的跨语言文本相似度计算方法
消耗积分:0 |
格式:rar |
大小:0.57 MB |
2017-11-21
分享资料个
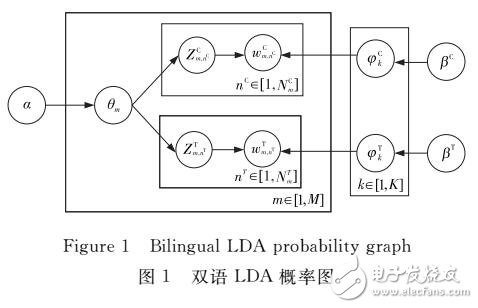
基于双语主题模型思想分析双语文本相似性,提出基于双语LDA跨语言文本相似度计算方法。先利用双语平行语料集训练双语LDA模型,再利用该模型预测新语料集主题分布,将新语料集的双语文档映射到同一个主题向量空间,结合主题分布使用余弦相似度方法计算新语料集双语文档的相似度,使用从类别间和类别内的主题分布离散度的角度改进的主题频率逆文档频率方法计算特征主题权重。实验表明,改进后的权重计算对于基于双语LDA相似度算法的召回率有较大提高,算法对类别不受限且有较好的可靠性。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





下载排行榜
- 暂无相关数据

