
资料下载


×
基于概率的大数据查询系统
消耗积分:3 |
格式:rar |
大小:0.78 MB |
2017-12-25
分享资料个
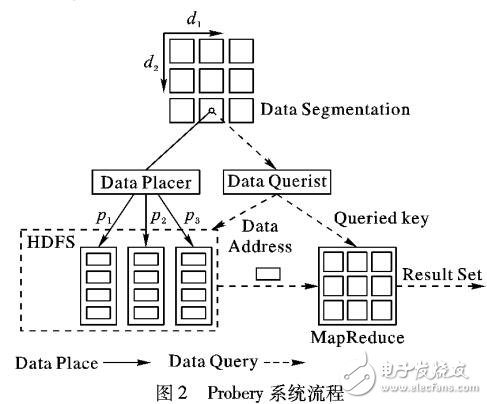
针对大数据环境下完整性查询时间代价消耗过高的问题,提出了一种采用近似完整性查询方法的系统-Probery。Probery所采用的近似完整性查询方法不同于传统的近似查询,其近似性主要体现为数据查全的可能性,是一种新型的数据查询方法。Probery首先将存入系统的数据划分为多个数据分段;然后,根据概率放置模型将各个数据分段的数据存储在分布式文件系统中;最后,对于给定的查询条件,Probery采用一种启发式查询方法进行概率查询。通过与其他主流的非关系型数据管理系统的查询性能进行比较,对Probery进行验证,Probery在损失8%查询完整性的情形下,查询时间较HBase相比节约了51%,较Cassandra相比节约了23%,较MongoDB相比节约了12%,较Hive相比节约了3%。实验结果表明,Probery可以适当地损失查询完整性来提高数据的查询性能,具有较好的通用性、适应性和可扩展性。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





下载排行榜
- 暂无相关数据

