
资料下载


×
如何使用MapReduce进行大数据的主动学习
消耗积分:0 |
格式:rar |
大小:0.73 MB |
2018-12-12
分享资料个
针对传统的主动学习算法只能处理中小型数据集的问题,提出一种基于MapReduce的大数据主动学习算法。首先,在有类别标签的初始训练集上,用极限学习机( ELM)算法训练一个分类器,并将其输出用软最大化函数变换为一个后验概率分布。然后,将无类别标签的大数据集划分为Z个子集,并部署到Z个云计算节点上。在每一个节点,用训练出的分类器并行地计算各个子集中样例的信息熵,并选择信息熵大的前q个样例进行类别标注,将标注类别的Z×q个样例添加到有类别标签的训练集中。重复以上步骤直到满足预定义的停止条件。在Artificial、Skin、Statlog和Poker 4个数据集上与基于ELM的主动学习算法进行了比较,结果显示,所提算法在4个数据集上均能完成主动样例选择,而基于ELM的主动学习算法只在规模最小的数据集上能完成主动样例选择。实验结果表明,所提算法优于基于极限学习机的主动学习算法。
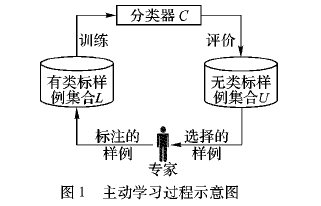
大数据具有以下几个特征:海量( Volume)、多模态(Variety)、变化速度快(Velocity)、蕴含价值高(Value)和可靠性高( Veracity)。在大数据环境下,传统的机器学习面临着巨大的挑战,其中也包括主动学习。主动学习算法大致可以分为两大类:基于池的主动学习算法和基于流的主动学习算法。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





