
资料下载


如何使用数据过采样和集成学习进行软件缺陷数目预测方法概述
分享资料个
预测软件缺陷的数目有助于软件测试人员更多地关注缺陷数量多的模块,从而合理地分配有限的测试资源。针对软件缺陷数据集不平衡的问题,提出了一种基于数据过采样和集成学习的软件缺陷数目预测方法——SMOTENDEL。首先,对原始软件缺陷数据集进行n次过采样,得到凡个平衡的数据集;然后基于这n个平衡的数据集利用回归算法训练出n个个体软件缺陷数目预测模型;最后对这凡个个体模型进行结合得到一个组合软件缺陷数目预测模型,利用该组合预测模型对新的软件模块的缺陷数目进行预测。实验结果表明SMOTENDEL相比原始的预测方法在性能上有较大提升,当分别利用决策树回归( DTR)、贝叶斯岭回归(BRR)和线性回归(LR)作为个体预测模型时,提升率分别为7.68%、3.31%和3.38%。
软件在如今社会发挥着举足轻重的作用,复杂系统的可靠性高度依赖于软件的可靠性。软件缺陷是导致系统失效和崩溃的潜在根源,如果能对软件缺陷进行预测,就能在造成危害前对软件缺陷进行排查和修复,从而减少软件崩溃所带来的经济损失。
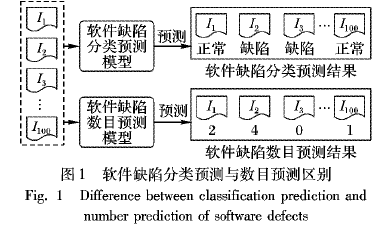
伴随着第一个软件的诞生并延续至今,软件缺陷预测技术已得到了长足的发展。已有很多研究提出了很多软件缺陷预测方法。探索了传统的机器学习模型和半监督学习在软件缺陷预测中的应用,并在PROMISE数据集上进行测试,达到了工程的需求。比较了包括决策树、贝叶斯、向量机、人工神经网络等传统机器学习模型在多机构数据集上的预测表现。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




