搜索内容
登录
爬虫
0人关注
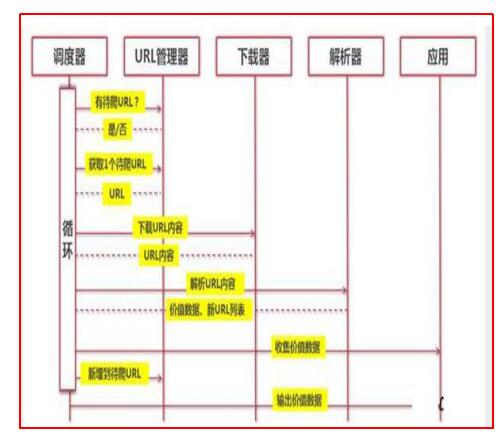
在互联网领域,爬虫一般指抓取众多公开网站网页上数据的相关技术。目前,爬行是获取数据的主要方式。正如爬虫工作者所知,爬虫时IP很容易被封堵,这是因为有了反爬虫机制,所以才使用代理IP。
...展开
76
文章
1201
视频
36
帖子
7999
阅读
关注标签,获取最新内容
全部
技术
资讯
资料
帖子
视频
网络爬虫的作用是什么
2019-03-21
3.2w阅读
网络爬虫的原理是什么
2019-03-21
1.3w阅读
网络爬虫的算法
2019-03-21
1.5w阅读
网络爬虫的爬行策略
2019-03-21
7568阅读
网络爬虫的基本工作流程
2019-03-21
2.9w阅读
成为高级爬虫工程师有哪些要求
2019-03-20
5539阅读
爬取b站上的所有短评进行分析,用数据说明为什么这部动漫会如此受欢迎
2019-03-05
7289阅读
如何快速入门Python爬虫的?
2019-02-18
3145阅读
如何用robots.txt快速抓取网站
2019-01-10
3367阅读
python为什么叫爬虫
2018-12-27
15.5w阅读
python爬虫框架Scrapy实战案例!
2018-12-07
2.3w阅读
用Python爬去百度贴吧图片并保存到本地
2018-12-03
7808阅读
爬虫实践:批量下载所有排行榜小说
2018-10-31
5961阅读
一篇了解爬虫技术方方面面
2018-10-23
3038阅读
抓取网易云音乐热歌榜里的热评的爬虫
2018-09-03
8325阅读
如何使用Scrapy爬取网站数据
2018-07-26
5678阅读
Python爬虫速成指南让你快速的学会写一个最简单的爬虫
2018-06-10
7539阅读
12行简单的Python代码,初窥爬虫的秘境
2018-06-07
6612阅读
如何让爬虫更简单的使用这些代理?
2018-06-04
5047阅读
Python学习爬虫掌握的库资料大全和框架的选择的分析
2018-05-19
5672阅读
上一页
4
/
5
下一页
相关推荐
更多 >
IOT
海思
STM32F103C8T6
数字隔离
硬件工程师
wifi模块
MPU6050
Protues
STC12C5A60S2
74ls74
UHD
×
20
完善资料,
赚取积分





 下载APP
下载APP
 搜索内容
搜索内容