
资料下载


基于AdderNet的深度学习推理加速器
李永每
分享资料个
描述
该项目介绍了我们对基于称为 AdderNet 的新型深度学习模型的硬件推理加速器设计和优化的研究。通过用绝对和 (SAD) 内核替换计算密集型卷积 (CONV) 操作,可以通过具有成本效益的加法器/减法器电路消除大量乘法器,这可以提高计算吞吐量,因为硬件限制。我们在 FPGA 设备上展示了基线 ResNet-20 实现 (CNN-ResNet-20) 和两个 AdderNet 设计变体 (ADD-ResNet-20) 之间的比较研究。我们利用自动 HLS(高级综合)和手动转换将 SAD 操作映射到 Xilinx Zynq MPSoC 的 FPGA DSP 块 (DSP48E2)。尤其是,当 DSP48 模块配置为 SIMD(单指令多数据)模式时,我们可以用一个 DSP 模块和最少的 LUT 逻辑资源支持至少两个 SAD 操作。在这个研究阶段,我们选择使用一个 DSP 来支持 2 个 SAD 操作,以增加 10% 的 LUT 和 5% 的推理时间开销为代价,总共可以减少 45.43% 的 DSP 利用率。这些结果鼓励我们探索新的深度学习加速器设计策略,以利用新兴的基于 SAD 内核的 AdderNet 模型以及每个 DSP ≥4 SAD 的积极 SIMD 配置来提高推理吞吐量。我们选择使用 1 个 DSP 支持 2 个 SAD 操作,以增加 10% 的 LUT 和 5% 的推理时间开销为代价,总共可以减少 45.43% 的 DSP 利用率。这些结果鼓励我们探索新的深度学习加速器设计策略,以利用新兴的基于 SAD 内核的 AdderNet 模型以及每个 DSP ≥4 SAD 的积极 SIMD 配置来提高推理吞吐量。我们选择使用 1 个 DSP 支持 2 个 SAD 操作,以增加 10% 的 LUT 和 5% 的推理时间开销为代价,总共可以减少 45.43% 的 DSP 利用率。这些结果鼓励我们探索新的深度学习加速器设计策略,以利用新兴的基于 SAD 内核的 AdderNet 模型以及每个 DSP ≥4 SAD 的积极 SIMD 配置来提高推理吞吐量。
卷积神经网络(CNN)已广泛应用于计算机视觉任务领域。例如工业检测、自主视觉和机器人检测。然而,由于其大量的乘法运算和参数,很难将这些标准神经网络部署到具有效率吞吐量和功耗的嵌入式设备中。作为一种解决方案,AdderNet 在深度神经网络,尤其是卷积神经网络 (CNN) 中使用这些大规模乘法,以获得更便宜的加法以降低计算成本。
Function.1 CNN
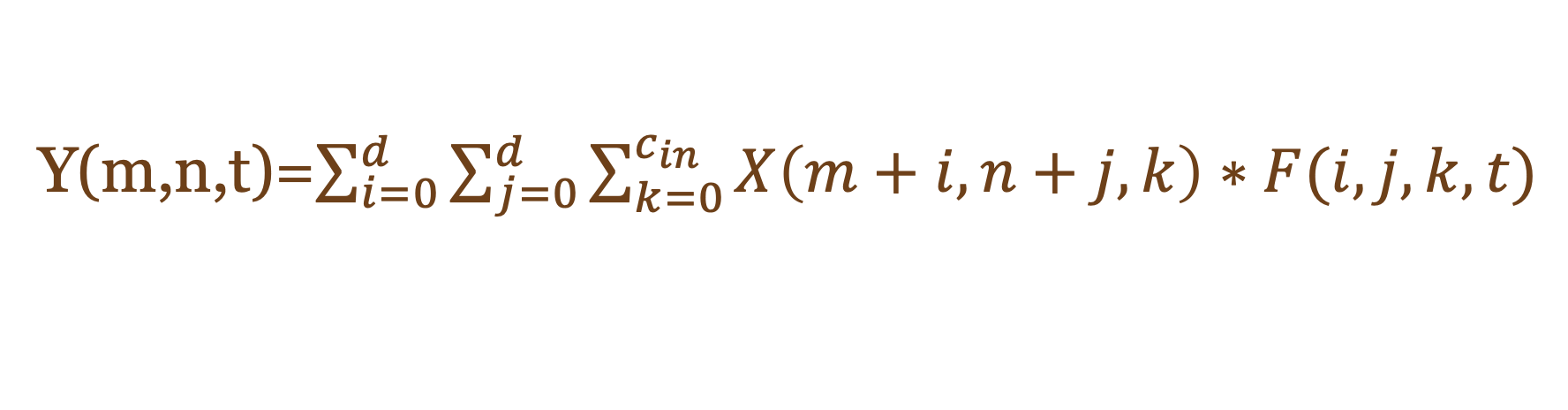
Function.2 人工神经网络
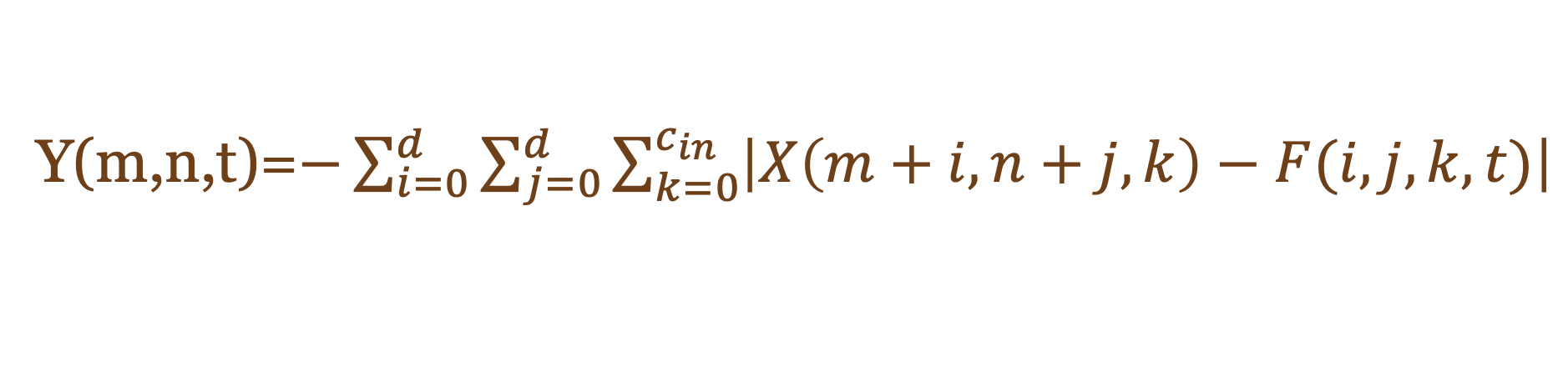
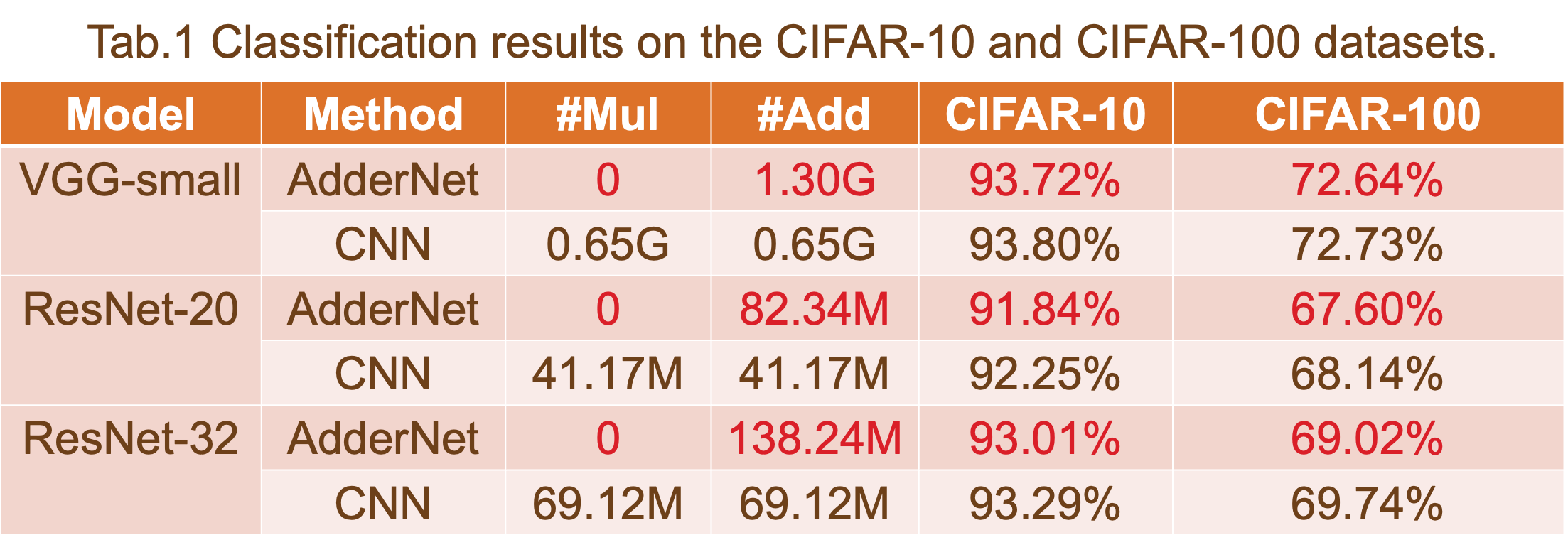
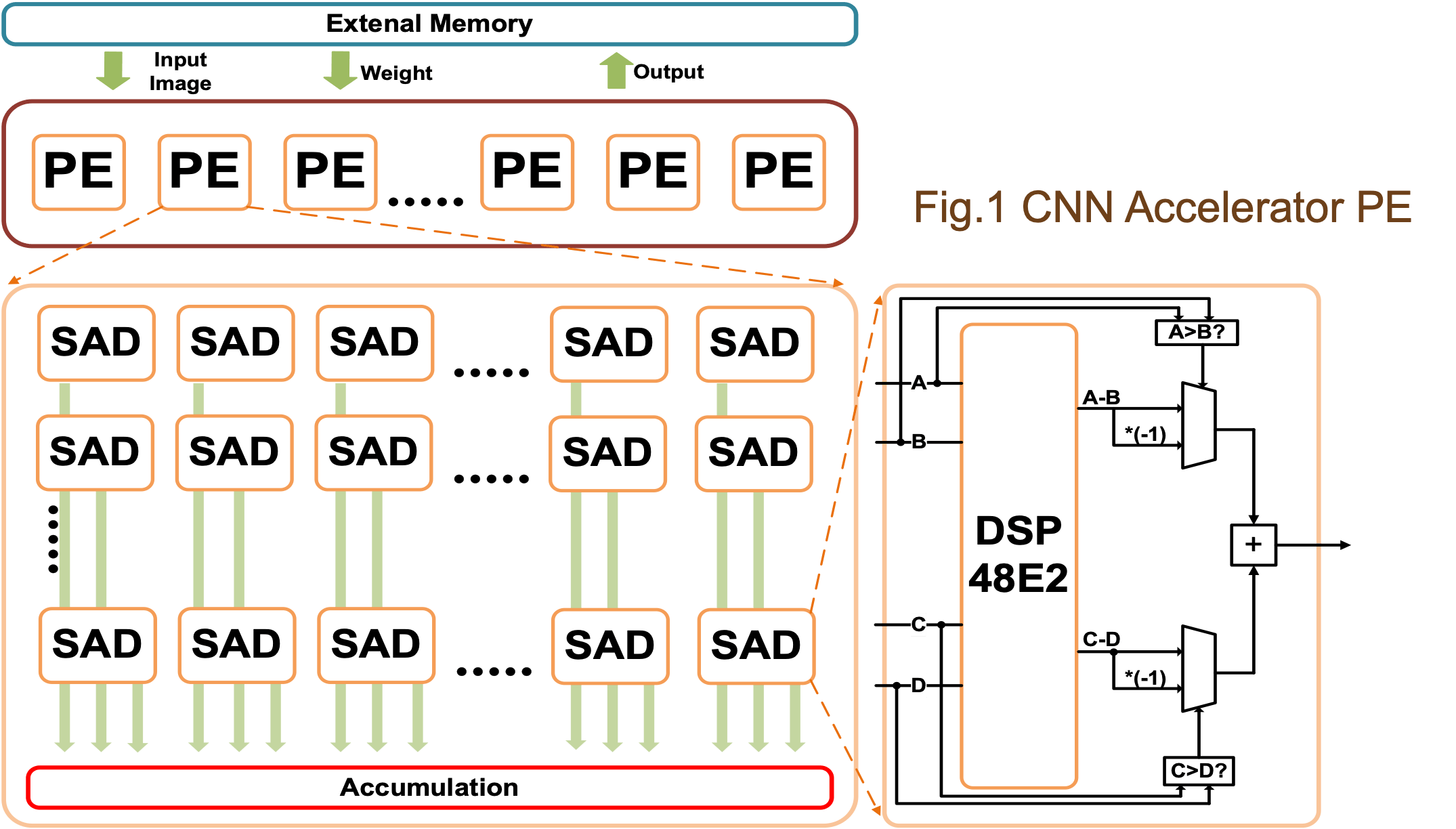
作为案例研究,我们选择 ResNet-20-CIFAR10 作为基线设计。ResNet-20-CIFAR10的处理引擎如图1所示。据我们所知,CNN 加速器有两种通用方法:单个 PE 和多个 PE。在这项工作中,我们在应用程序中使用了多个 PE 以获得更好的吞吐量。
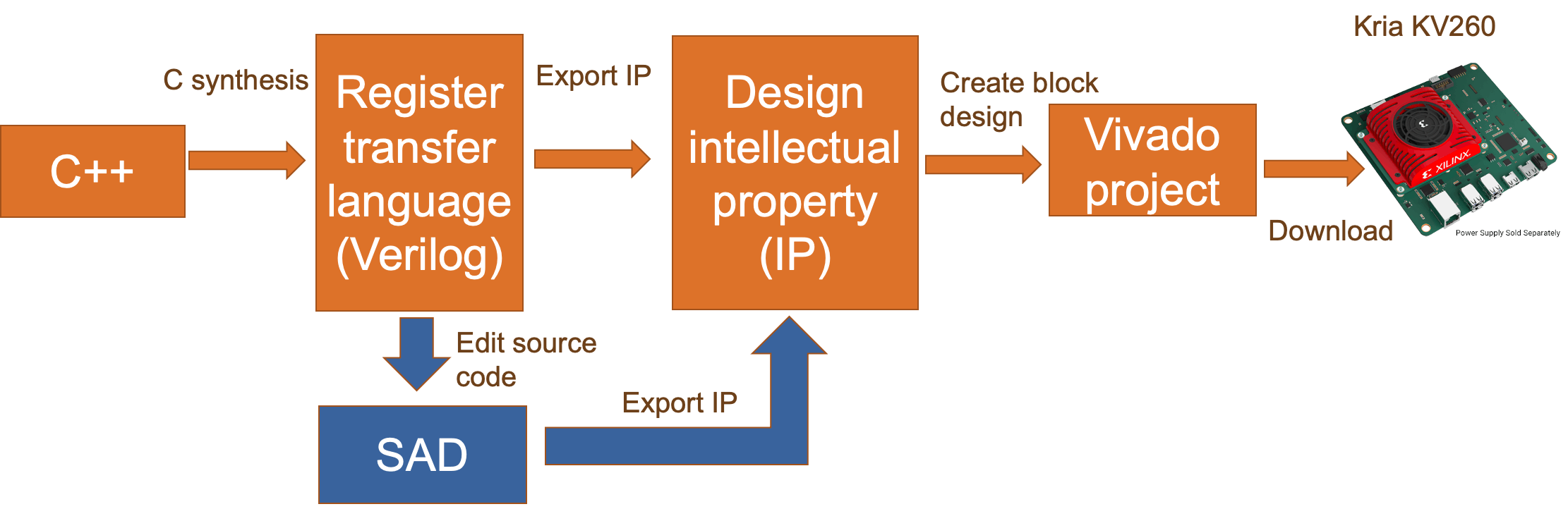
自动 HLS 和手动转换
Xilinx Vitis HLS 上的自动综合:
Xilinx Vitis HLS 可以从 C++ 代码自动生成 FPGA 项目。
对于 CNN-ResNet-20,综合报告显示该项目的硬件符合我们的目的。
对于 ADD-ResNet-20,合成报告并没有遵循我们之前的目的,因为 Vitis HLS 中的 C 合成不支持将 DSP48 配置为 SIMD 模式。
我们的解决方案:
将 SAD 操作设计为 C++ 中的独立函数。
替换 Xilinx Vitis HLS 生成的 Verilog 源文件中的 SAD 代码。
在 Xilinx Vivado 中重新综合该项目。
此外,通过编辑 SAD 代码,我们可以为 DSP48E2 配置更多选项。
Batch Normalization 融合可以减少计算量,并为模型量化提供更简洁的结构。
如 Function.3 和 4 所示,将细化权重应用于卷积层作为原始推理。但是考虑左边显示的加法器层的功能,作为卷积添加到函数中的细化权重不能用作卷积层。
由于乘法和加法的开销,这个函数不能提供 AdderNet 的硬件优势。
为了避免这种开销,我们使用额外的 for 循环来处理乘法和加法的开销,这将花费更多的时钟周期和硬件。

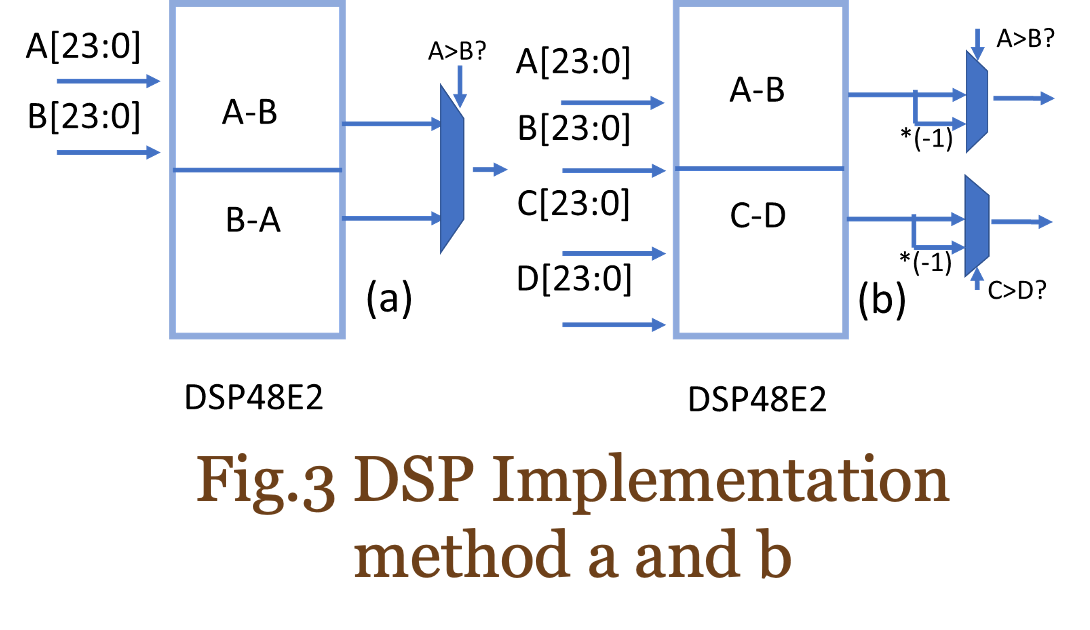
DSP配置方法
在本节中,将介绍两种 DSP48E2 配置方法:
方法 a:利用与 CONV 相同数量的 DSP,但与方法 b 相比,LUT 更少。
方法 b:利用一半的 DSP 作为 CONV,但与方法 a 相比,LUT 更多。
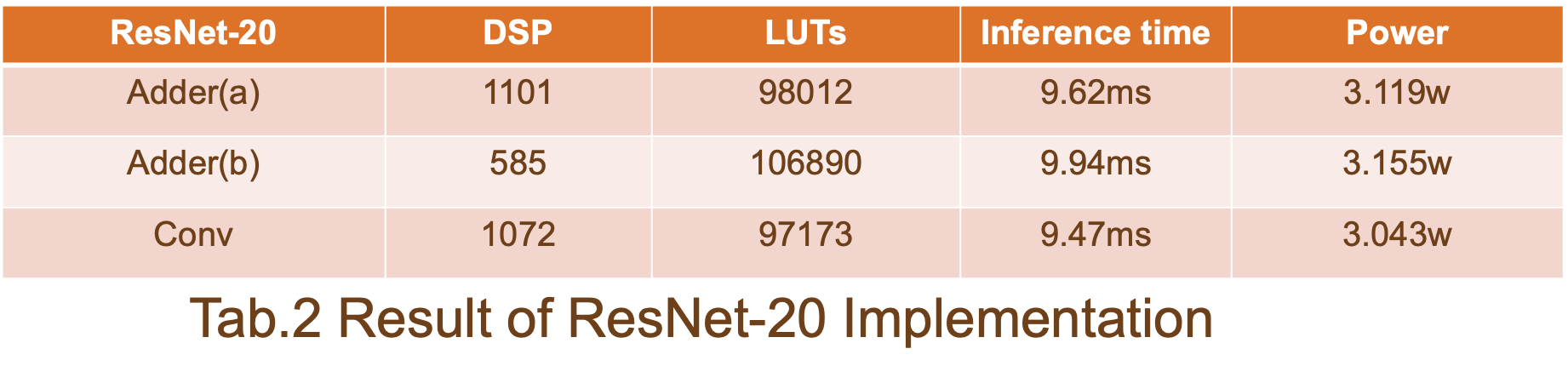
该报告显示,通过比较解决方案 a、解决方案 b 和 ResNet-20 基线的结果,我们的方法可以以增加 10% 的 LUT 和 5% 的推理时间开销为代价,减少大约 45% 的 DSP 利用率。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




