
资料下载


开源硬件边缘语音识别
李娓仑
分享资料个
描述
介绍
在这个项目中,我围绕一个训练识别单词left 、right 、up和down的模型构建了一个应用程序。它所做的只是捕获和处理音频,将其输入 TensorFlow Lite 模型,然后在 OLED 显示器上显示输出。我将介绍如何使用 i.MXR1010 评估套件在边缘设置和进行机器学习。
设置开发环境
任何机器学习和嵌入式电子项目都需要许多硬件和软件才能使用。我正在使用 MacOS 进行开发。由于 Nvidia GPU 不支持 MacOS,所以我使用 Linux 桌面进行训练和模型生成。
安装 MCUExpresso IDE
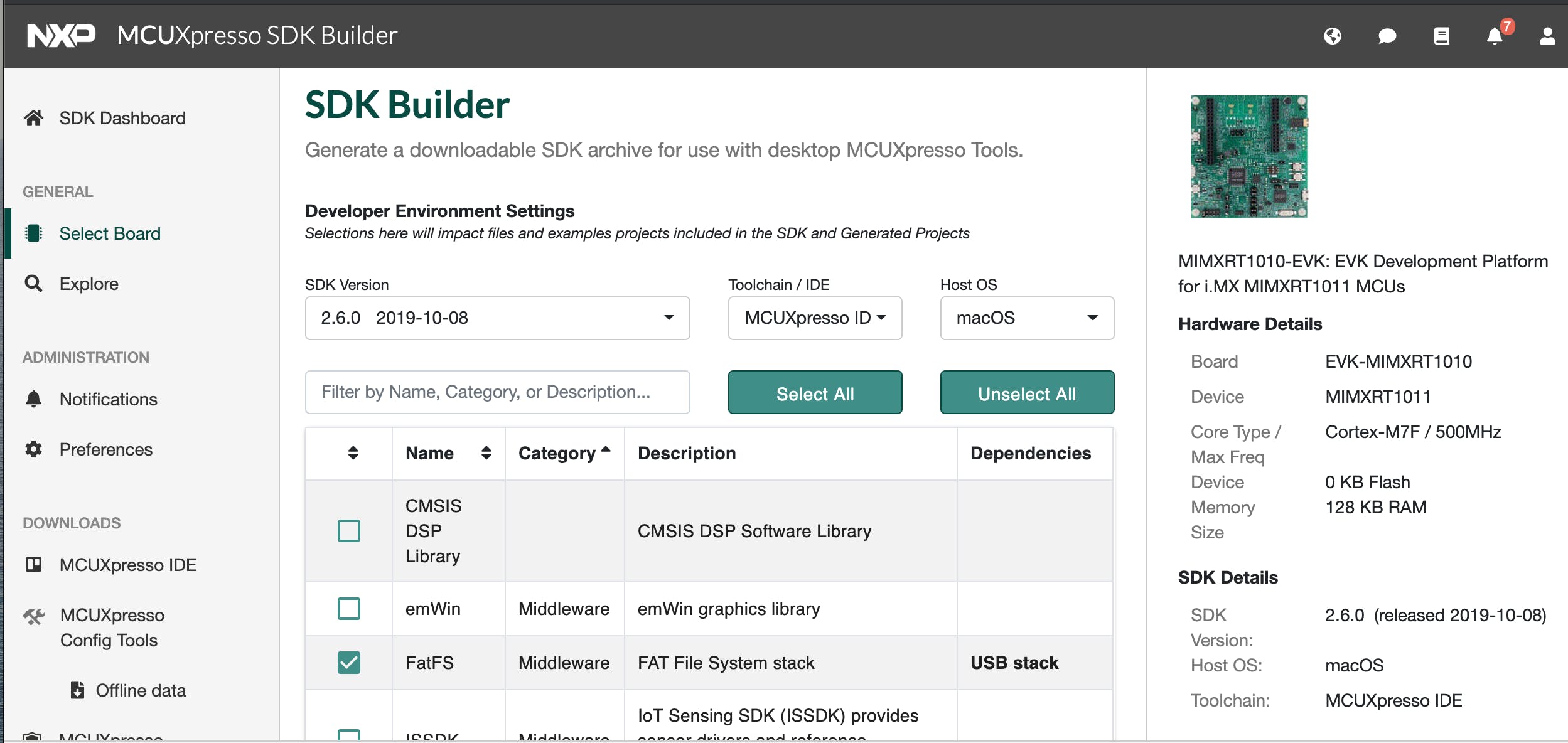
下载 SDK 后,我们需要将下载的包拖放到 MCUExpresso IDE Installed SDKs区域,如下所示(红色框)。
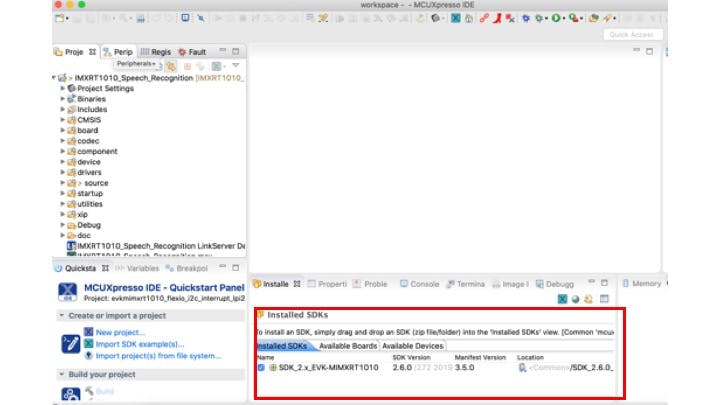
我们可以从 Quickstart Panel > New Project 创建一个新项目,它会显示一个向导,我们可以在其中选择 IMXRT1010 作为开发板。我们可以使用此向导配置所需的驱动程序/组件,如下所示。添加/删除驱动程序和其他组件可以在此期间完成。发展。由于我们将使用 TensorFlow C++ 库,所以我选择了C++ Project 。
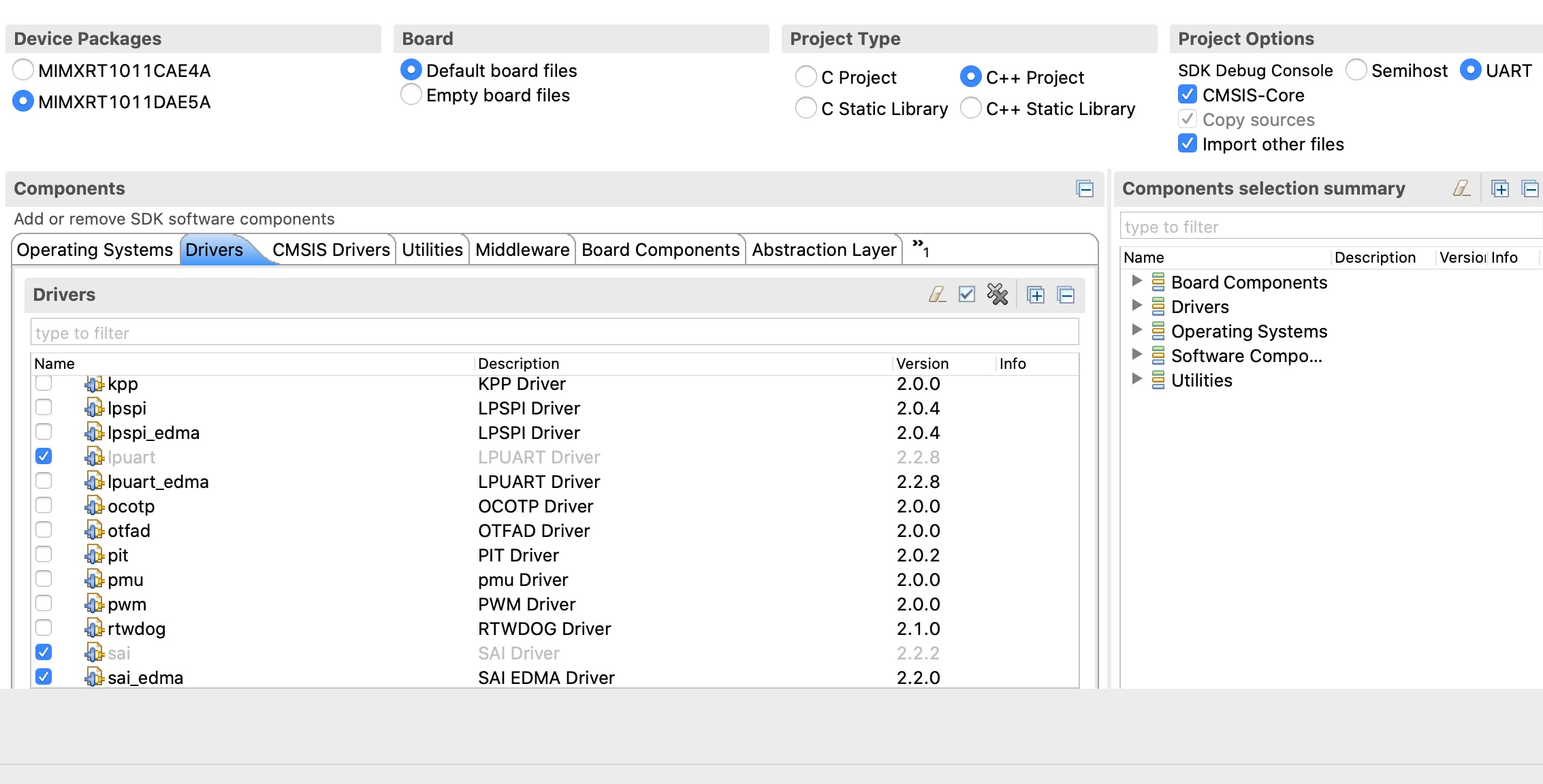
为微控制器安装 TensorFlow Lite
用于微控制器的 TensorFlow Lite 能够生成包含所有必要源文件的独立项目。我的 MCUXpresso IDE 工作区位于 ~/Documents/MCUXpressoIDE_11.1.0/workspace/。您可能需要根据您的目录结构更改路径。我们还需要制作3.82 或更高版本。MacOS Catalina 上捆绑的make版本为 3.81。我们可以使用安装所需的版本
brew install make
并且可以使用gmake命令运行它。
cd ~
git clone https://github.com/tensorflow/tensorflow.git
cd tensorflow
gmake -f tensorflow/lite/micro/tools/make/Makefile generate_projects
cp -r tensorflow/lite/micro/tools/make/gen/osx_x86_64/prj/micro_speech/make/* ~/Documents/MCUXpressoIDE_11.1.0/workspace/IMXRT1010_Speech_Recognition/source
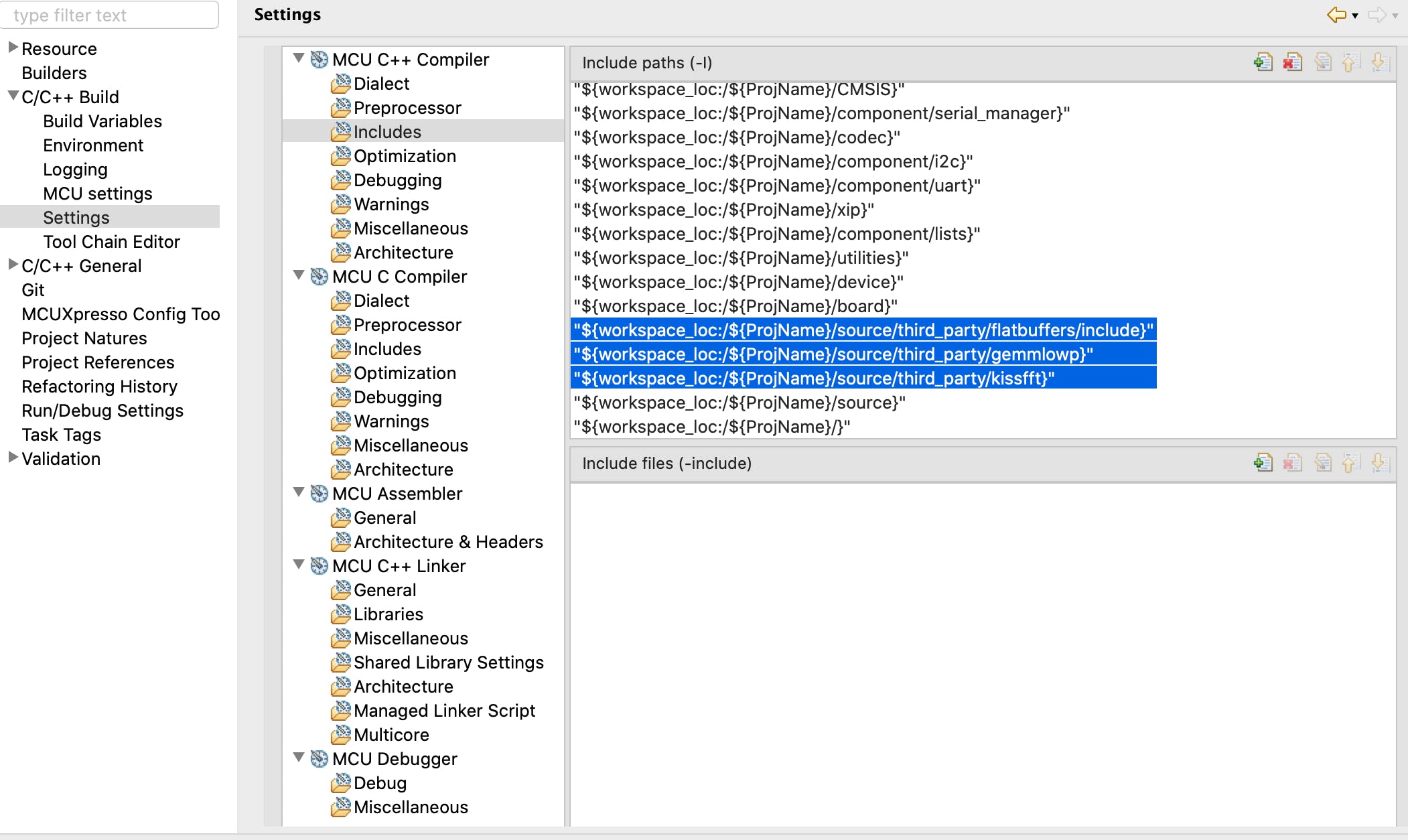
复制后,我们将拥有 TensorFlow C++ 库以及其他一些用于音频处理的第三方库。我们需要使用Quickstart Panel > Edit Project Settings > C/C++ build > Settings > MCU C++ Compiler > Includes为不属于 SDK 的库(在下面的屏幕截图中突出显示)设置包含路径。
应用程序将捕获的音频数据保存在运行时创建的缓冲区中,因此我们需要将默认堆大小(仅 2KB)调整为 14 KB。此外,一些缓冲区数据需要是不可缓存的。我们可以利用 i.MXRT1010 的FlexRAM功能。堆栈/堆大小和不可缓存数据可以使用Quickstart Panel > Edit Project Settings > C/C++ build > Settings > MCU C++ Linker > Managed Linker Script进行配置。
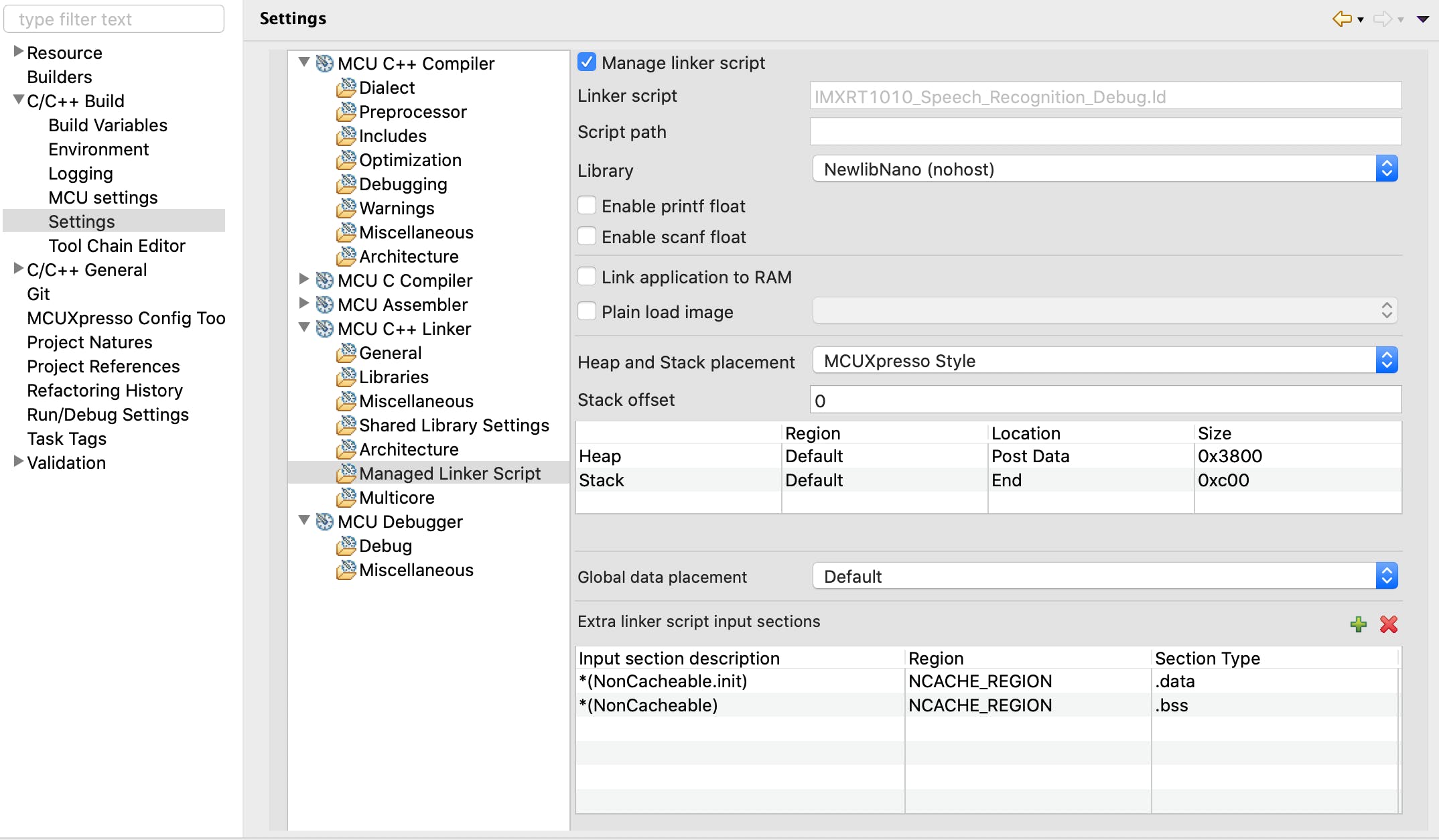
i.MXRT1010 具有有限的 128 KB 内存,分为 32 KB 库。由于内存溢出,编译失败。
section `.heap' will not fit in region `SRAM_DTC'
arm-none-eabi/bin/ld: region `SRAM_DTC' overflowed by 15920 bytes
Memory region Used Size Region Size %age Used
BOARD_FLASH: 215432 B 16 MB 1.28%
SRAM_DTC: 48688 B 32 KB 148.58%
SRAM_ITC: 0 GB 32 KB 0.00%
SRAM_OC: 0 GB 32 KB 0.00%
NCACHE_REGION: 4748 B 32 KB 14.49%
多亏了FlexRAM ,我们可以使用下面的代码配置变量声明以选择内存库。__DATA(RAM3)用于告诉编译器将大约 16 KB 的变量g_audio_capture_buffer保存到 FlexRAM 的 OCRAM 部分 (SRAM_OC) 中。
__DATA(RAM3) int16_t g_audio_capture_buffer[kAudioCaptureBufferSize];
编译后,我们可以在下面看到内存分配的编译器输出。
Memory region Used Size Region Size %age Used
BOARD_FLASH: 231432 B 16 MB 1.38%
SRAM_DTC: 32688 B 32 KB 99.76%
SRAM_ITC: 0 GB 32 KB 0.00%
SRAM_OC: 16000 B 32 KB 48.83%
NCACHE_REGION: 4748 B 32 KB 14.49%
训练数据集和模型生成
我们使用的模型是使用 TensorFlow Simple Audio Recognition 脚本训练的,这是一个示例脚本,旨在演示如何使用 TensorFlow 构建和训练音频识别模型。该模型在带有 eGPU(Nvidia 1080 Ti)的 Linux 桌面上进行了训练,其中包含“上”、“下”、“左”、“右”四个词。数据集中的其他词被用作“未知”。将创建的模型转换为 TensorFlow Lite 模型,并将转换后的模型转换为 C 数组文件,以便与推理代码一起部署。TensorFlow Lite Micro SDK 用于在设备上运行推理。卷积神经网络用于模型创建。
设备端推理
使用带有增强型直接内存访问 (eDMA) 控制器的同步音频接口 (SAI) 捕获音频。该过程首先为给定的时间片生成快速傅立叶变换 (FFT),在本例中为 30 ms 的捕获音频数据。TensorFlow Lite 模型不接收原始音频样本数据。相反,它适用于频谱图,频谱图是由频率信息切片组成的二维数组,每个切片取自不同的时间窗口。我们可以将频谱图视为输入模型进行推理的图像数据。OLED 显示器通过 I2C 连接到 i.MXRT1010 EVK。The预测的单词显示在 OLED 显示屏上。
构建和调试
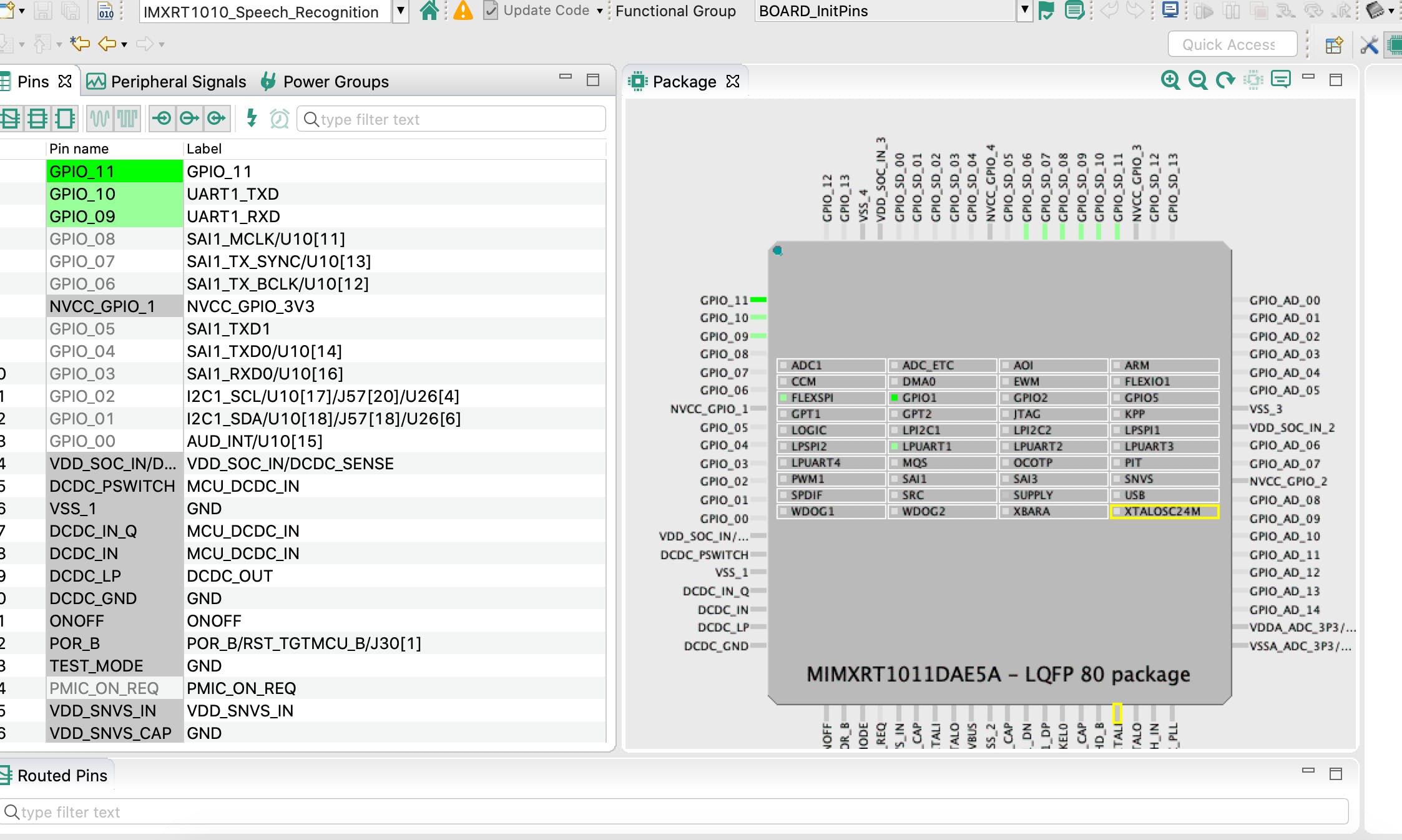
可以分别使用 MCUExpresso IDE Quickstart Panel > Build和Quickstart Panel > Debug来构建和调试项目。使用菜单ConfigTools > Pins将 UART 引脚配置为在调试期间重定向打印。
在 MacOS 上可以使用以下命令查看调试打印:
screen /dev/cu.usbmodem14202 115200
板载 LED 也配置为在推理时闪烁。
演示视频
现场演示如下。它并不完美,但有效。
改进范围
如果使用 8 位量化模型,可以提高推理率。目前,TensorFlow Lite Micro SDK 中缺少一些操作,这些操作不允许将 Conv 2D 转换为量化版本。目前,由于音频数据中的口音或噪音,有时会漏掉一些单词。如果使用迁移学习使用更多自己的语音数据进行训练,则可以提高模型的准确性。此外,板载麦克风数据有一些噪音,可以使用某些设置进行修复,或者可以使用外部数字麦克风以获得更好的性能。
此应用程序的 MCUExpresso 项目可以在代码部分提到的 Github 存储库中找到。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





