
资料下载


根据气候变化声音识别自然灾害的设备
陈文博
分享资料个
描述
介绍
随着气候的变化,与气候变化相关的自然灾害呈上升趋势。气候变化与自然灾害形成正反馈循环。气温上升正在引发野火,这将释放大量的二氧化碳,这将导致更多的温室效应,使环境温度升高,未来更多的野火。
要追踪气候变化,必须关注自然灾害的频率。这些自然灾害中的大多数都有与每场灾难相关的独特声音。大雨、雷暴、冰雹、海啸、野火、飓风、地震、火山爆发——这些灾难中的每一个都会在这些灾难性事件中产生独特/特定的声音。这些声音是气候变化的声音。
我正在尝试构建一个具有快速逻辑快速羽毛板和 sensiML AI 的设备来识别这些声音。最终目标是建立一个自然灾害检测设备网络,可以根据气候变化的声音/声音识别自然灾害。
现在的问题是,人工智能可以根据声音检测这些事件吗?
让我们来了解一下!
硬件
这些是用于该项目的硬件:

- LiPo Power Rig:在 QORC 贴纸下方有一个 4000 mAh LiPo 电池,它粘在普通的 veroboard 上以构建电源装置。该装备为所有硬件部件提供即插即用连接和机械支持
- Quick Feather Dev Board:Quick Logic AI 板,本项目的大脑
- Adafruit Tripler:Adafruit Tripler 扩展有助于快速羽毛和 HC-05 蓝牙模块之间的连接
- HC-05 蓝牙 UART 模块:通过蓝牙与计算机或智能手机提供无线 UART 连接以发送结果
- 模块化太阳能锂聚合物充电器:这部分由一个降压转换器模块组成,该模块可以将 6-30 伏之间的任何直流电压降压至 5 伏,TP4056 模块将 5 伏转换为 4.2 伏以进行锂聚合物充电。
- 5 瓦太阳能电池板:为户外/远程操作的锂聚合物电池充电提供电源。
安装 SDK 和工具链
在下载 SDK 之前,我已经在计算机上安装了最新的 Ubuntu 20.04。这部分非常棘手,预计会有一些流失,因为官方设置指南并没有完全按预期工作。在自动安装过程中缺少一些依赖项,我必须手动安装。
Installing SDK
登录 Ubuntu 20.04,打开终端,一次输入以下 4 个命令:-
sudo apt install git
git clone https://github.com/QuickLogic-Corp/qorc-sdk.git
cd qorc-sdk
source envsetup.sh
这些将安装 git(如果您没有安装它),克隆快速逻辑 sdk,创建一个名为 qorc-sdk 的文件夹并假设安装所有内容!
从现在开始,所有东西都必须安装在 qorc-sdk 文件夹/目录中。
接下来,重新启动您的 Ubuntu 机器/计算机。
如果 ARM 工具链和 TinyFPGA Programmer 没有正确安装,请按照以下步骤安装:-
Installing ARM Toolchain
重新启动计算机后,再次打开终端并键入以下 3 个命令:-
cd qorc-sdk
mkdir arm_toolchain_install
wget -O gcc-arm-none-eabi-9-2020-q2-update-x86_64-linux.tar.bz2 -q --show-progress --progress=bar:force 2>&1 "https://developer.arm.com/-/media/Files/downloads/gnu-rm/9-2020q2/gcc-arm-none-eabi-9-2020-q2-update-x86_64-linux.tar.bz2?revision=05382cca-1721-44e1-ae19-1e7c3dc96118"
tar xvjf gcc-arm-none-eabi-9-2020-q2-update-x86_64-linux.tar.bz2 -C ${PWD}/arm_toolchain_install
Installing Python 3 and TinyFPGA programmer
在命令终端上键入以下命令:-
cd
cd qorc-sdk
sudo apt install python3-pip
git clone --recursive https://github.com/QuickLogic-Corp/TinyFPGA-Programmer-Application.git
pip3 install tinyfpgab
理想情况下,这一步不应该是必要的,但不知何故,这些是我所说的缺失或不起作用的依赖项
修改源代码
我检查了分支 ssi-audio-sensor 并构建了一个新的 qf_ssi_ai_app.bin。我也使用 dcl_import.ssf 作为插件。音频传感器在那里,但 DCL 仍然捕获加速度计数据。
为了解决这个问题,我在编译代码qf_apps/qf_ssi_ai_app/inc/Fw_global_config.h之前修改了 Fw_global_config.h文件
/* Settings for selecting either Audio or an I2C sensor, Enable only one of these mode */
#define SSI_SENSOR_SELECT_AUDIO (1)
// 1 => Select Audio data for live-streaming or recognition modes
#define SSI_SENSOR_SELECT_SSSS (0)
// 0 => Disable SSSS sensor data for live-streaming of recognition modes
闪烁的音频采集固件(数据采集模式)
Compile/Build an Example code
从 Ubuntu 终端转到 qorc-sdk 目录,将工具链添加到路径,将目录更改为 qf_ssi_ai_app 项目并使用以下命令使用源代码构建一个 bin 文件:-
cd qorc-sdk
export PATH=${PWD}/arm_toolchain_install/gcc-arm-none-eabi-9-2020-q2-update/bin:$PATH
cd
cd qorc-sdk/qf_apps/qf_ssi_ai_app/GCC_Project
make
Flash/Upload code to QuickLogic board
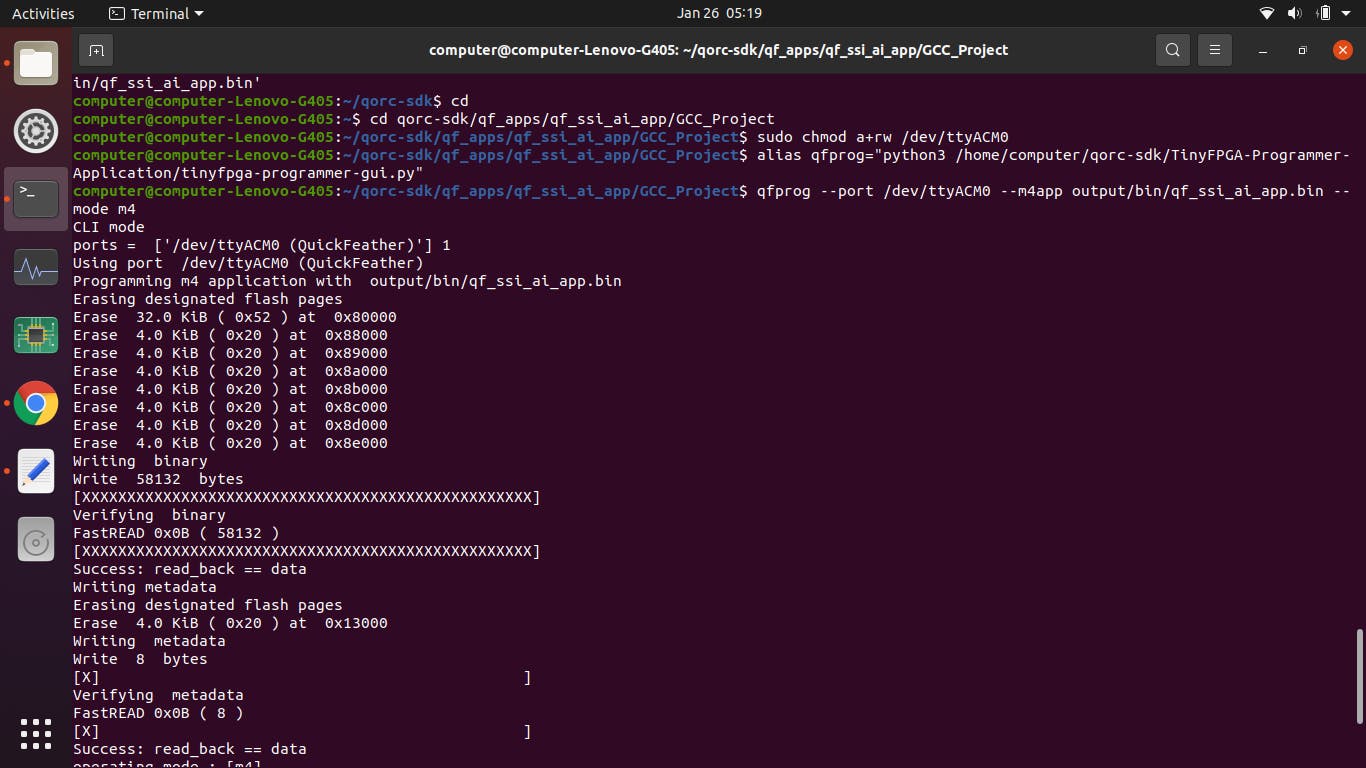
使用 USB 数据线将 Quick Feather 板连接到计算机,按下板上的重启按钮。当 Bule LED 闪烁时,按下用户按钮。一个闪烁的绿色 LED 应该开始闪烁,这意味着该板处于上传模式
在 Ubuntu 上打开终端并输入以下命令以刷新固件:-
cd
cd qorc-sdk/qf_apps/qf_ssi_ai_app/GCC_Project
sudo chmod a+rw /dev/ttyACM0
alias qfprog="python3 /home/computer/qorc-sdk/TinyFPGA-Programmer-Application/tinyfpga-programmer-gui.py"
qfprog --port /dev/ttyACM0 --m4app output/bin/qf_ssi_ai_app.bin --mode m4
闪烁应该像这样发生:-
SensiML 数据采集实验室
下一部分使用 SensiML Data Capture Lab 软件在单独的 Windows 10 计算机上完成。
这部分由Arduino “have11” Guy在他的 QuickFeather 开发工具包和 SensiML 入门项目中进行了彻底的解释。因此,我不会重复相同的内容进行详细说明。一切几乎完全相同,除了我将使用麦克风而不是加速度计来捕获声音数据。
以下是所有步骤的简要说明:
第 1 步:用于从麦克风捕获音频的 SSF 文件
ssf文件附在下面,使用此 ssf 文件将启用从 Quick Logic 开发套件的麦克风获取数据。此配置加载到 SensiML 数据捕获实验室。(详见本项目)
{
"name": "QuickFeather SimpleStream",
"uuid": "10b1db20-48a5-4442-a40e-fc530b456c89",
"collection_methods": [
{
"name": "live",
"display_name": "Live Stream Capture",
"storage_path": null,
"is_default": true
}
],
"device_connections": [
{
"name": "serial_simple_stream",
"display_name": "Data Stream Serial Port",
"value": 1,
"is_default": true,
"serial_port_configuration": {
"com_port": null,
"baud": 460800,
"stop_bits": 1,
"parity": 0,
"handshake": 0,
"max_live_sample_rate": 3301
}
},
{
"name": "wifi_simple",
"display_name": "Simple Stream over WiFi",
"value": 2,
"is_default": true,
"wifi_configuration": {
"use_mqttsn": false,
"use_external_broker": false,
"external_broker_address":"",
"broker_port":1885,
"device_ip_address": null,
"device_port": 0,
"max_live_sample_rate": 1000000
}
}
],
"capture_sources": [
{
"max_throughput": 0,
"name": "Motion",
"part": "MC3635",
"sample_rates": [
333, 250, 200, 100, 50
],
"is_default": true,
"sensors": [
{
"column_count": 3,
"is_default": true,
"column_suffixes": [
"X",
"Y",
"Z"
],
"type": "Accelerometer",
"parameters": [],
"sensor_id": 1229804865,
"can_live_stream": true
}
]
},
{
"max_throughput": 0,
"name": "Audio",
"part": "IM69D130",
"sample_rates": [
16000
],
"is_default": true,
"sensors": [
{
"column_count": 1,
"is_default": true,
"column_suffixes": [""],
"type": "Microphone",
"parameters": [],
"sensor_id": 1096107087,
"can_live_stream": true
}
]
},
{
"max_throughput": 0,
"name": "Qwiic Scale",
"part": "NAU7802",
"sample_rates": [
333, 250, 200, 100, 50
],
"is_default": false,
"sensors": [
{
"column_count": 1,
"is_default": true,
"column_suffixes": [
""
],
"type": "Weight",
"parameters": [],
"units": null
}
],
"sensor_id": 1334804865,
"can_live_stream": true
},
{
"max_throughput": 0,
"name": "ADC",
"part": "ADS1015",
"sample_rates": [
100,
250,
500,
1000,
1600,
2400,
3300
],
"is_default": false,
"sensors": [
{
"column_count": 1,
"is_default": true,
"column_suffixes": [
""
],
"type": "Analog Channel"
}
],
"sensor_id": 1184532964,
"can_live_stream": true
},
],
"is_little_endian": true
}
第 2 步:使用 Sensi ML 构建 AI 模型
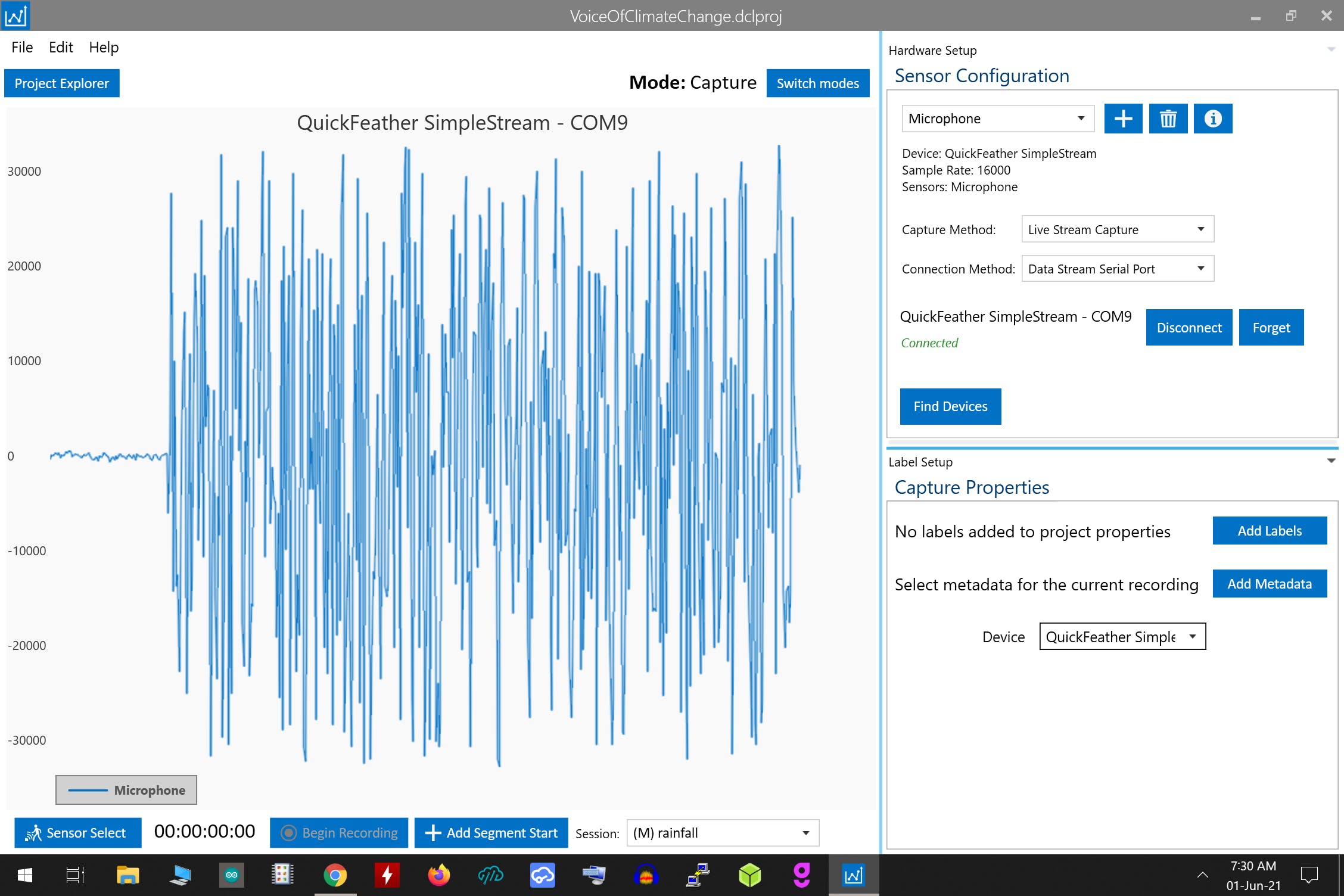
这是我在早上 7 点左右为构建 AI 模型录制的降雨和雷声示例,因此来自其他来源的环境噪声很低:
首先在 Sensi ML DCL 的 Capture Mode 中,记录暴雨和雷声
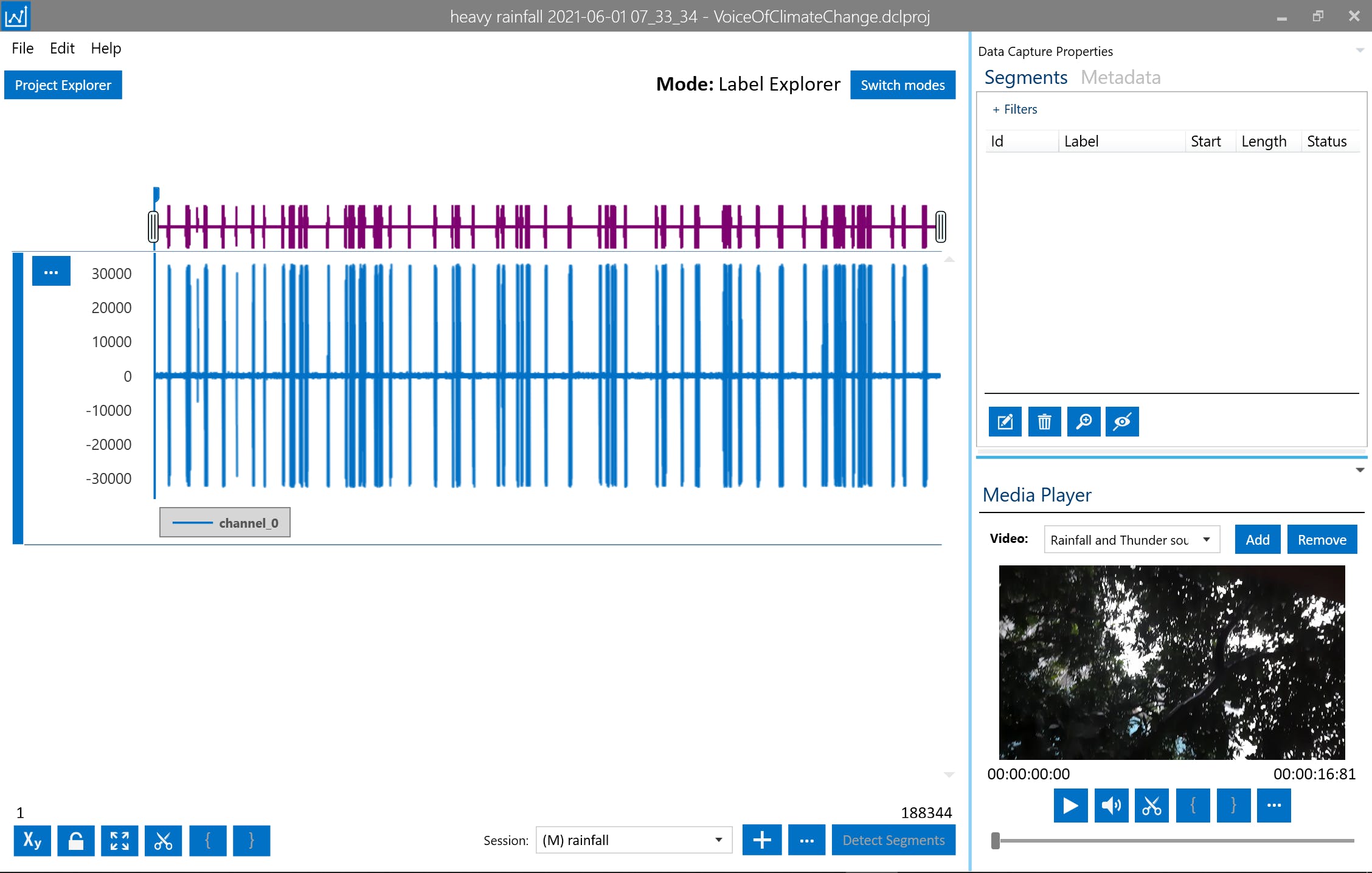
然后在标签浏览器模式下,手动识别声音并将其标记为降雨或雷声
第 3 步:训练模型
这一步在https://app.sensiml.cloud/网页界面上完成,构建训练模型
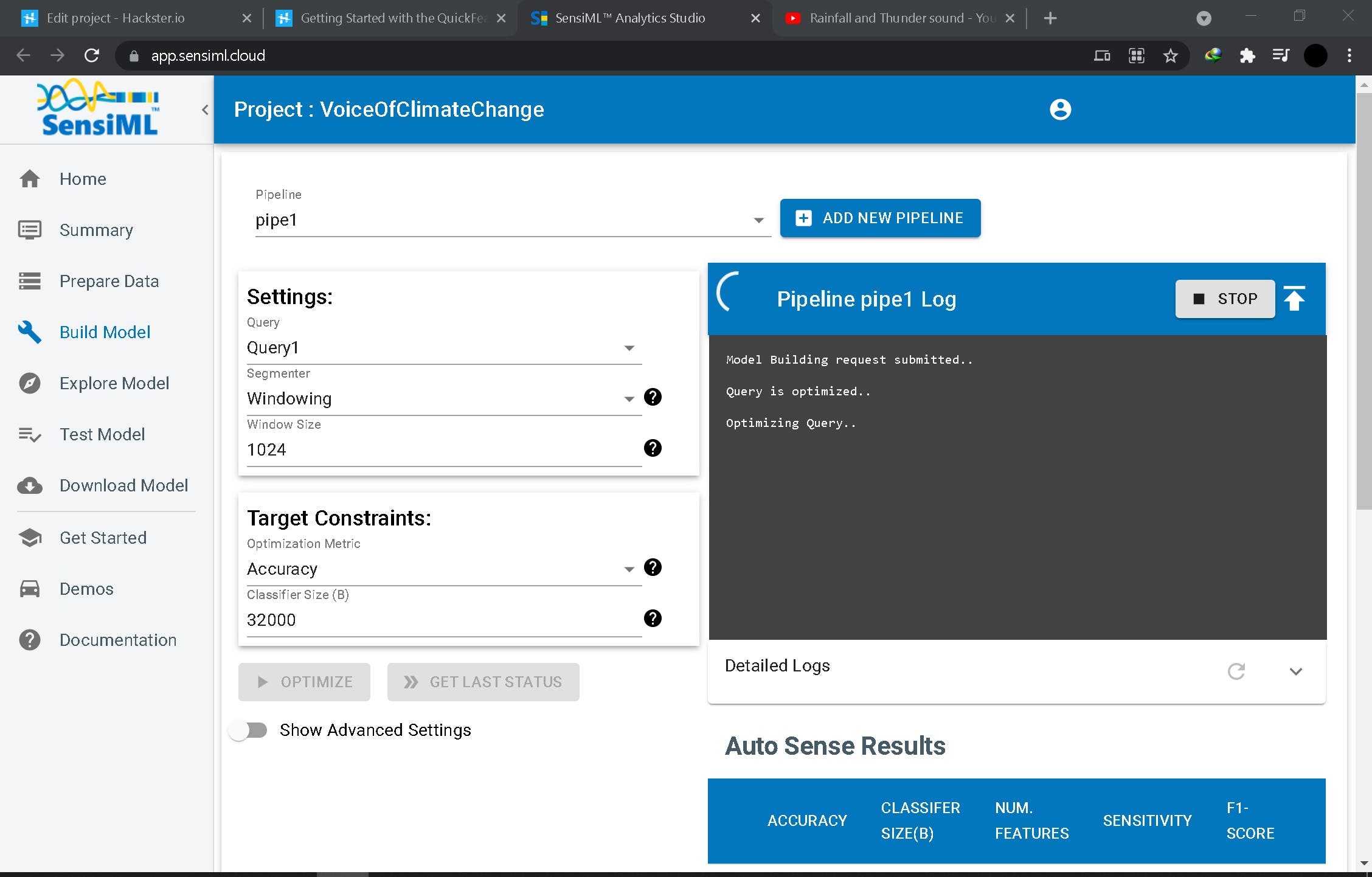
之后,可以测试和探索模型以提高性能。
然后下载模型(文件附在下面)并刷入快速羽毛板
部署
好吧,刷完bin文件后,我通过电脑的蓝牙和另一端的HC-05将设备连接到Putty,进行无线UART连接。
降雨和雷声的检测不是很准确。我敢肯定,我在 AI 模型构建和测试阶段错过了很多优化。我必须再试一次,从头开始重建一切以获得更好的模型!
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






