
资料下载


使用流量计和TinyML检测管道堵塞
张桂兰
分享资料个
描述
管道堵塞会对工业运营产生严重的破坏性影响。堵塞的发生可能有多种原因,例如碎屑堆积、腐蚀和其他类型的损坏。当管道堵塞时,它会扰乱材料的流动并导致昂贵的维修、停机和其他问题。在本文中,我们将探讨堵塞对工业管道的破坏性影响,并讨论一些预防和缓解这些问题的方法。
管道堵塞的主要影响之一是降低效率和生产力。当管道堵塞时,材料的流动会中断,这可能导致生产过程中的延迟和瓶颈。这可能会导致错过最后期限、减少产量和减少利润。此外,堵塞会导致设备更快磨损,从而导致更高的维护和维修成本。
管道堵塞的另一个破坏性影响是环境破坏。当管道堵塞时,可能会导致溢出和泄漏,从而对环境造成严重后果。例如,如果输送有害物质的管道堵塞,物质可能会泄漏并污染周围区域。这会对野生动物、生态系统和人类健康产生严重影响。
除了这些影响之外,管道堵塞还会对工人造成安全风险。如果输送高压流体或气体的管道发生堵塞,可能会导致爆炸或其他危险。这可能会使工人面临受伤或死亡的风险,并导致设备和设施损坏。
作为工业运营中管道堵塞问题的建议解决方案,我们正在引入人工智能 (AI) 和机器学习的使用。我们的人工智能系统使用流量传感器数据,通过分析可能表明堵塞的流量变化来检测管道中的堵塞情况。这种方法有可能防止中断和昂贵的维修,并降低环境破坏和安全事故的风险。
为实施该解决方案,将沿管道长度安装流量传感器。这些传感器将持续测量通过管道的物料流速,并将数据传回人工智能系统。然后,人工智能系统将使用机器学习算法来分析数据并检测可能表明堵塞的任何变化。如果检测到堵塞,系统会提醒维护人员,然后他们可以采取措施解决问题。
硬件要求
软件要求
硬件设置
在这个项目中,我们使用了Seeed Wio Terminal开发板。选择这个特定的板是因为它作为一个完整的系统具有全面的功能,包括屏幕、开发板、输入/输出接口和外壳。从本质上讲,Seeed Wio Terminal在一个单一的集成包中提供了成功项目所需的一切。此外,该开发板以其可靠性和易用性着称,是我们项目的理想选择。

我们使用了 DFRobot水流传感器来检测水流状态。

该传感器的目的是测量液体通过时的流速。它通过使用磁性转子和霍尔效应传感器来完成这项任务。当液体流过传感器时,液体的运动会引起磁转子旋转。转子转动的速度与液体的流速成正比。位于转子附近的霍尔效应传感器检测到这种旋转并输出脉冲宽度信号。然后可以使用该脉冲宽度信号来计算液体的流速。这样,磁性转子和霍尔效应传感器的组合可以精确测量液体的流量。
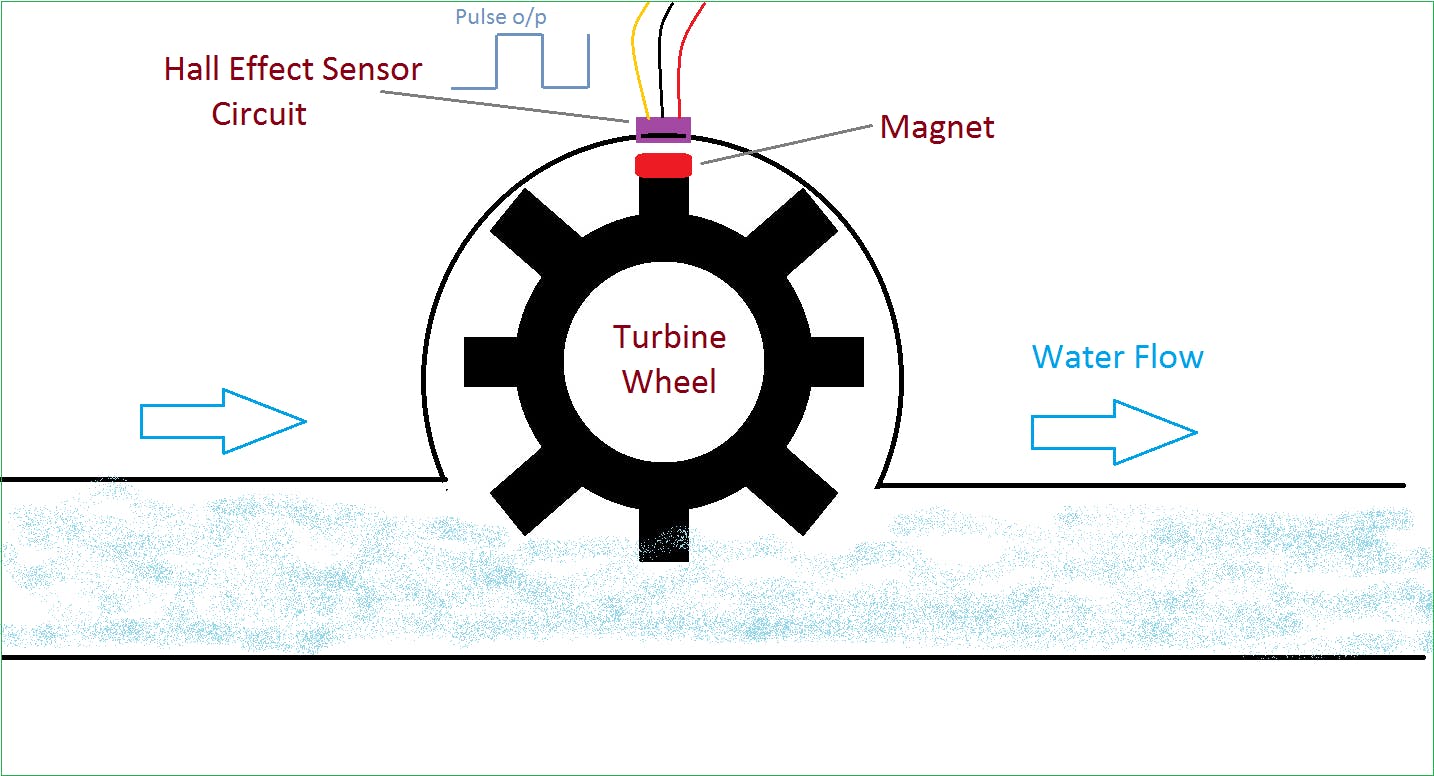
该系统的流程设置非常简单。本质上,它涉及将两根管道连接到流量传感器的入口和出口。进水管用于将被测液体导入流量传感器,而出水管用于将被测液体引出流量传感器。这种简单的配置允许在液体通过流量传感器时准确测量液体的流速。
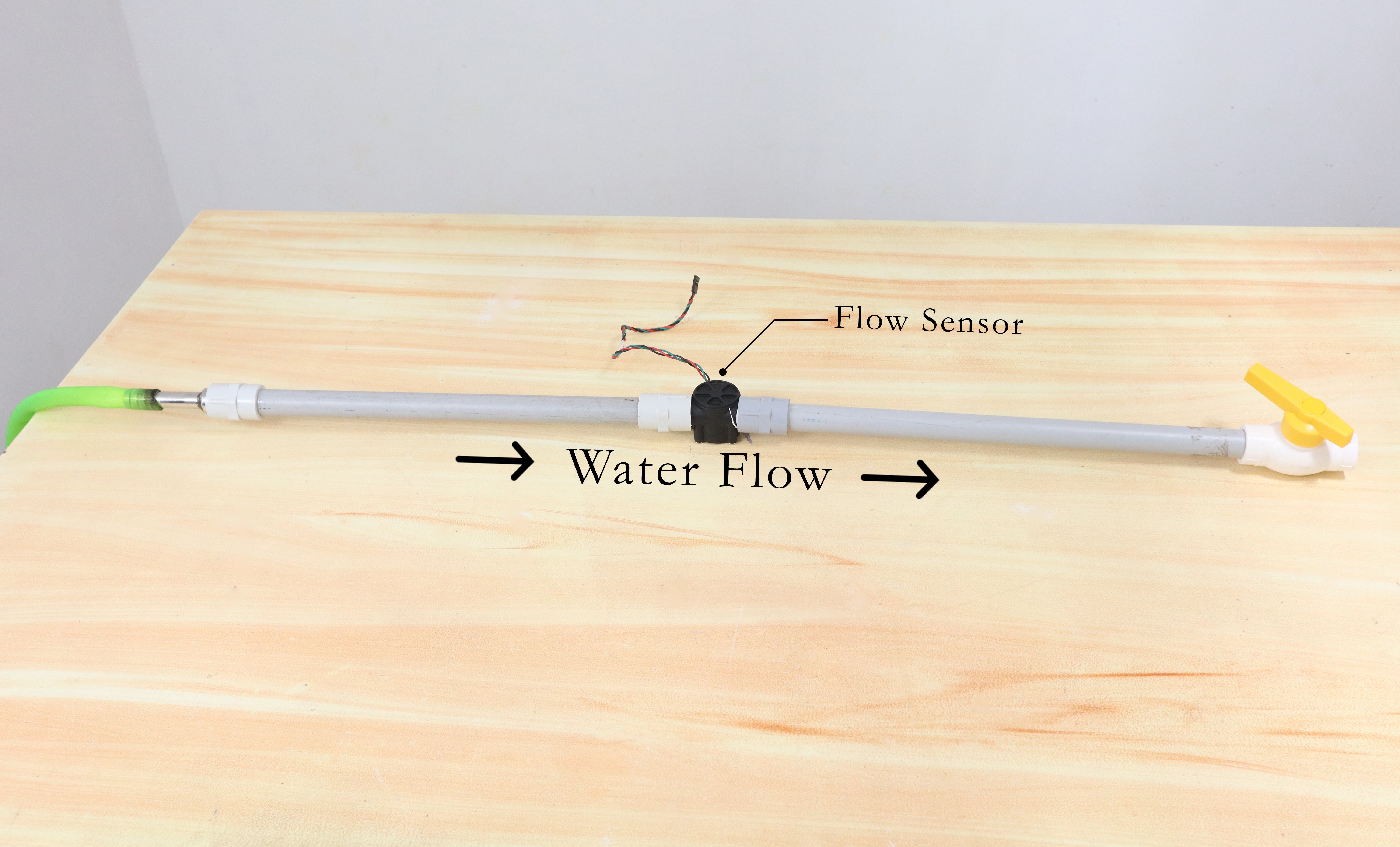
我们将收集数据:
- 没有流量的时候
- 有流量的时候
- 有堵塞时
软件设置
要准备与 Edge Impulse 一起使用的 Seeed Wio 终端,您可以按照官方指南中提供的说明进行操作。但是,我们选择采用另一种方法来收集我们项目中的数据。具体来说,我们使用 CSV 文件收集数据,然后将其上传到 Edge Impulse。从那里,我们遵循使用以这种方式收集的数据生成 TinyML 模型的通常过程。我们的方法使我们能够以灵活、便携的格式收集数据,这些数据可以轻松传输到 Edge Impulse 以进行进一步分析和模型创建。
1. 数据收集
在我们的项目中,我们使用了一个水流传感器,它可以产生脉宽调制 (PWM) 信号作为输出。我们没有直接从传感器收集模拟值,而是选择使用基于 PWM 信号的方程式来计算流量。然后将该流量数据收集为时间序列数据,使我们能够跟踪流量随时间的变化。我们还收集了三种不同场景的流量数据:无流量、正常流量和堵塞。通过我们的分析,我们确定这三种情况会在我们的模型可以检测到的流量数据中产生可区分的模式。
要为您的项目收集数据,请执行以下步骤:
- 将DataCollection.ino上传到 Wio 终端。
- 将 Wio 终端插入计算机。
- 在计算机中运行SerialDataCollection.py 。
- 按下按钮C开始录音。
- 当您有足够的数据时,再次按下按钮C停止记录。
- 停止录制后,它会在您的计算机上生成一个 CSV 文件。根据流态命名。
- 使用“数据采集”选项卡将 CSV 文件上传到 EdgeImpulse 。
将包含流速数据的 CSV 文件上传到 Edge Impulse 后,我们将整个数据集分成 6 秒长的较小样本。这个过程称为拆分数据,使我们能够分析和操作数据以创建模型。
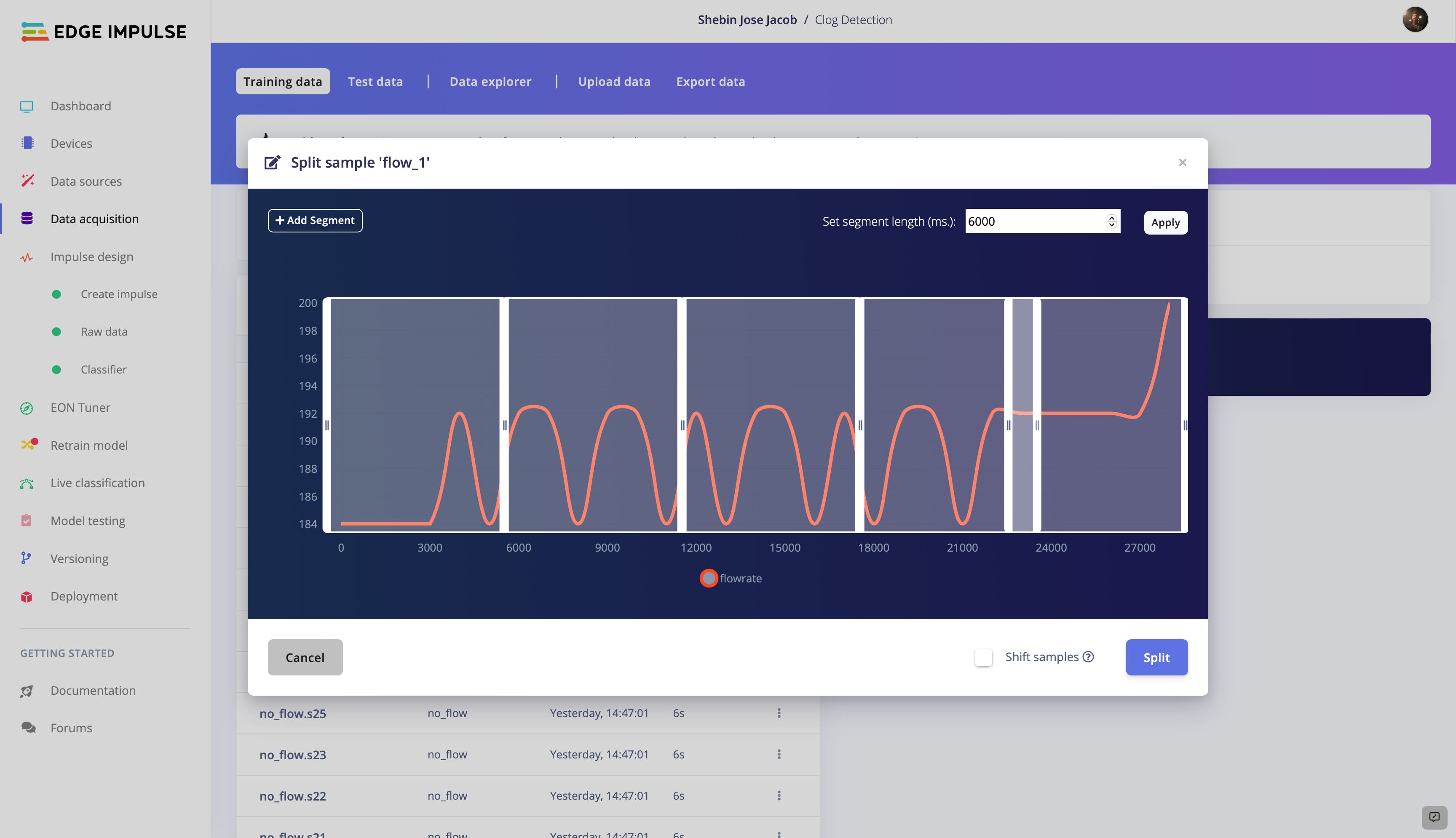
通过将数据分解成更小的块,我们可以更轻松地识别可能与我们的模型相关的趋势和模式。此外,这种方法使我们能够有效地使用数据进行训练和测试,因为我们可以更轻松地控制每个样本的输入和输出。每个班级收集的样本之一如下图所示。
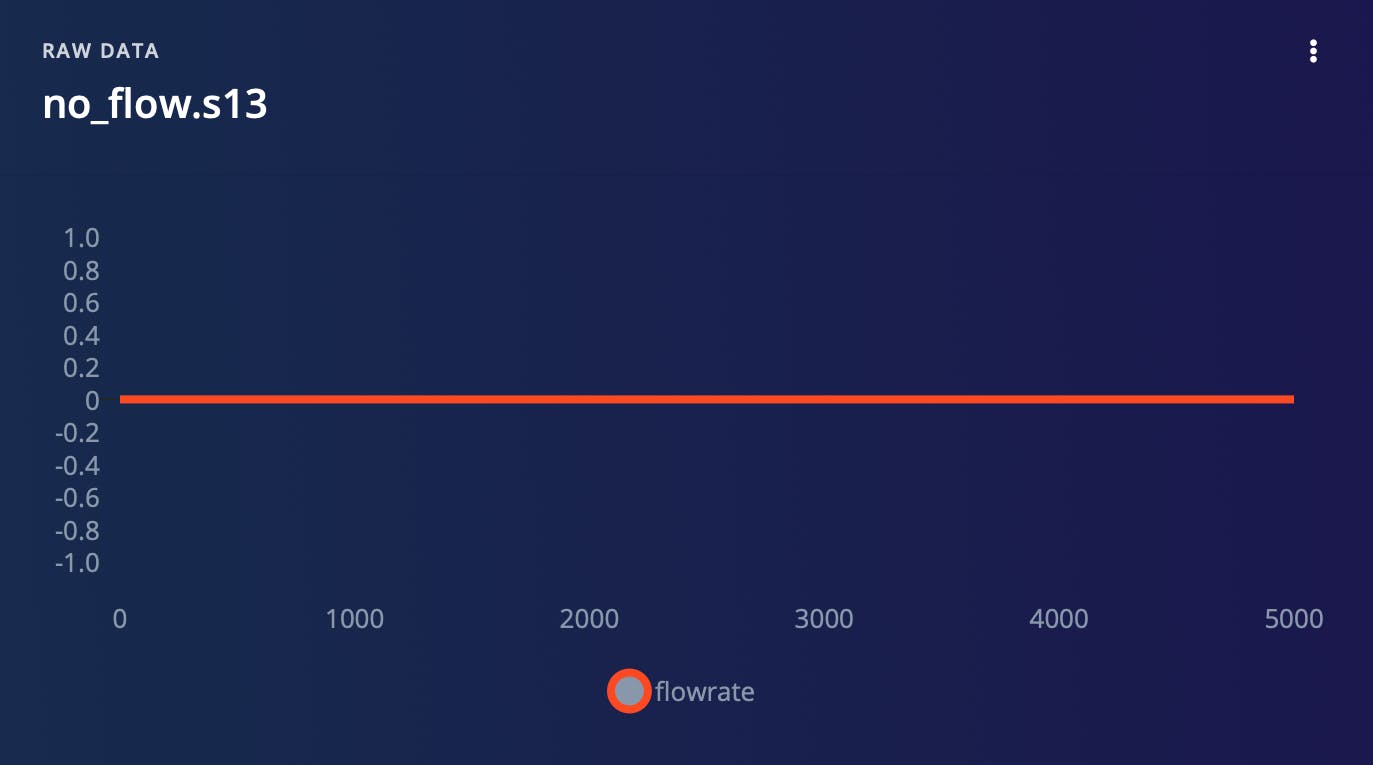
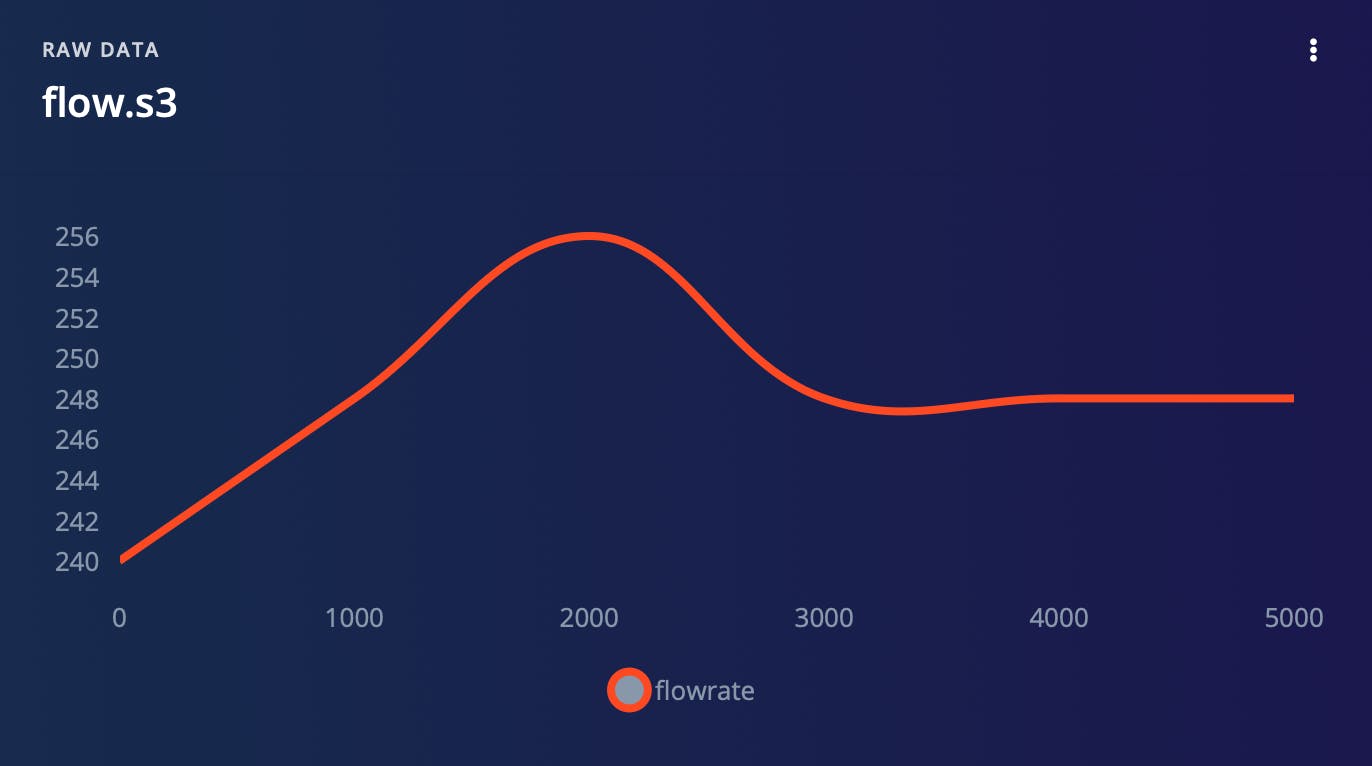
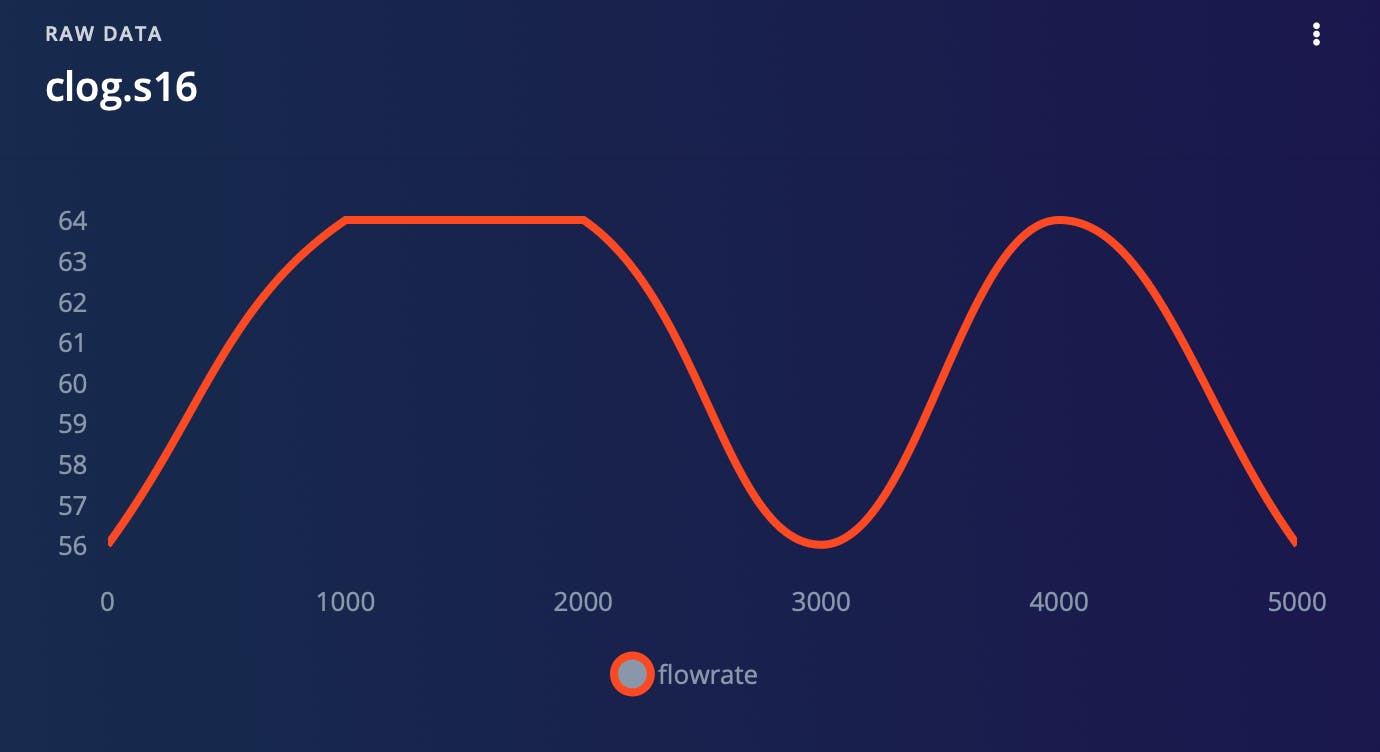
如上所述将我们的流量数据分成更小的样本后,我们进一步将数据集分成两个不同的子集:训练数据集和测试数据集。此过程称为数据分区,是模型创建过程中必不可少的步骤。
通过将数据分成这两个子集,我们可以使用训练数据集来教我们的模型识别模式并进行预测,而测试数据集则用于评估模型的准确性和有效性。通过使用干净、组织良好的数据集,我们可以确信我们的模型正在从高质量数据中学习,并且更有可能产生准确可靠的结果。
2. 冲动设计
脉冲是一种专门的机器学习管道,旨在从原始数据中提取有用的信息,并使用它来进行预测或对新数据进行分类。创建脉冲的过程通常涉及三个主要阶段:信号处理、特征提取和学习。
在信号处理阶段,以更适合分析的格式清理和组织原始数据。这可能涉及去除噪音或其他无关信息,还可能涉及以某种方式预处理数据,使其对流程的下一阶段更有用。
接下来,特征提取阶段涉及从处理过的数据中识别和提取重要特征或模式。这些特征是学习块将用于分类或预测新数据的关键信息。
最后,学习块负责根据前一阶段提取的特征对新数据进行分类或预测。这可能涉及在提取的特征上训练机器学习模型,或者可能涉及应用一些其他类型的分类或预测算法。
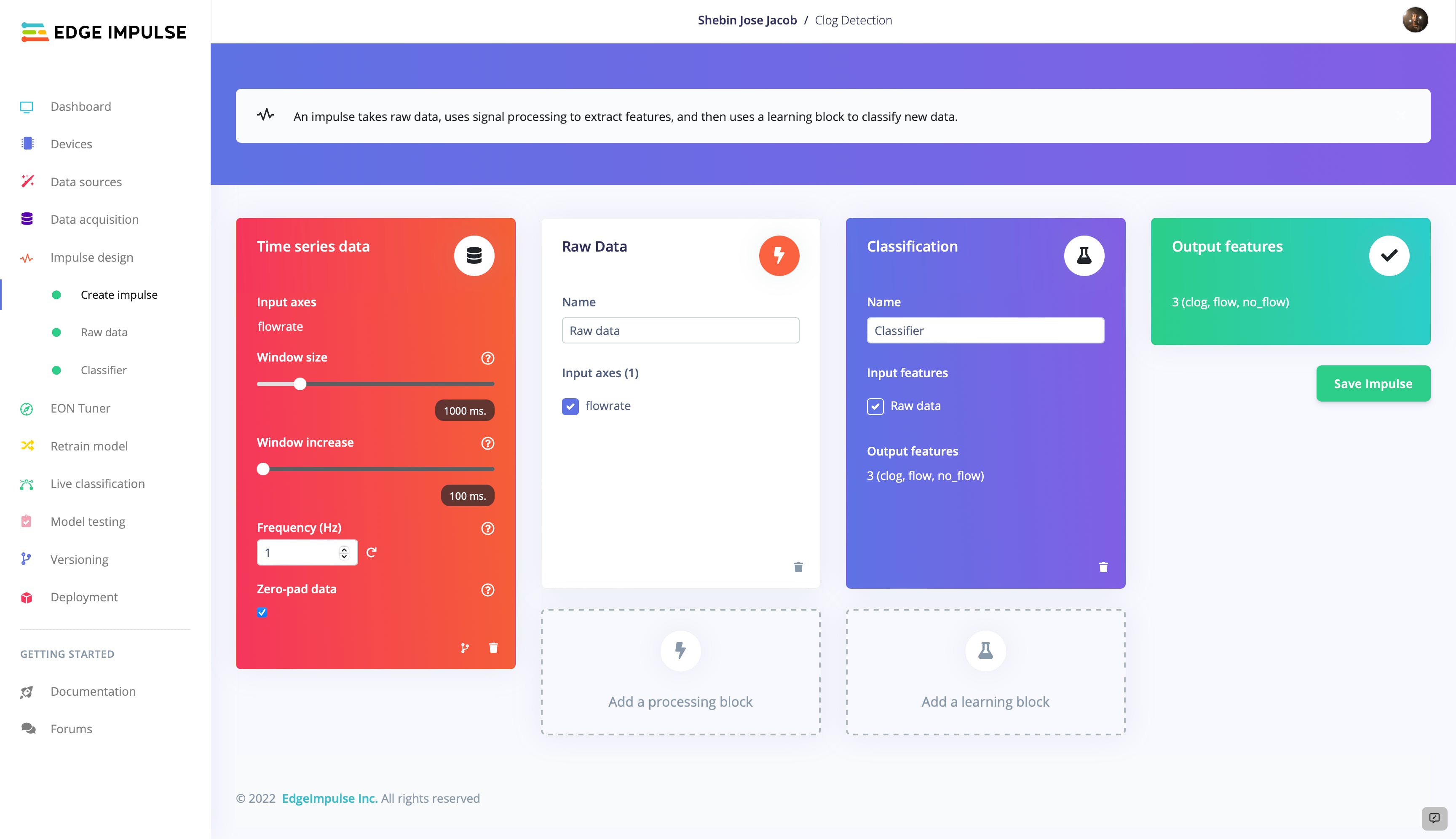
在这个项目中,我们利用机器学习将液体的流速分为三个不同类别之一。为此,我们使用时间序列数据作为脉冲的输入块。这种类型的数据包括在一段时间内定期进行的一系列测量,非常适合分析流量数据的趋势和模式。
对于处理块,我们使用原始数据,这是直接从流量传感器收集的未处理数据。然后,此数据通过处理块传递,在那里以更适合分析的方式对其进行清理和组织。
最后,对于学习块,我们使用分类器块。这种类型的算法旨在将数据分配给几个预定义类别之一,并且非常适合将流量数据分类为三个类别之一的任务。通过使用分类作为学习块,我们可以将流量数据分为三类之一:无流量、正常流量或堵塞。
在此过程中的这一点上,我们已准备好移至“原始数据”选项卡并开始生成特征。原始数据选项卡提供了许多用于操作数据的选项,例如更改轴的比例或应用各种过滤器。在我们的例子中,我们选择保留默认设置并直接继续生成特征。
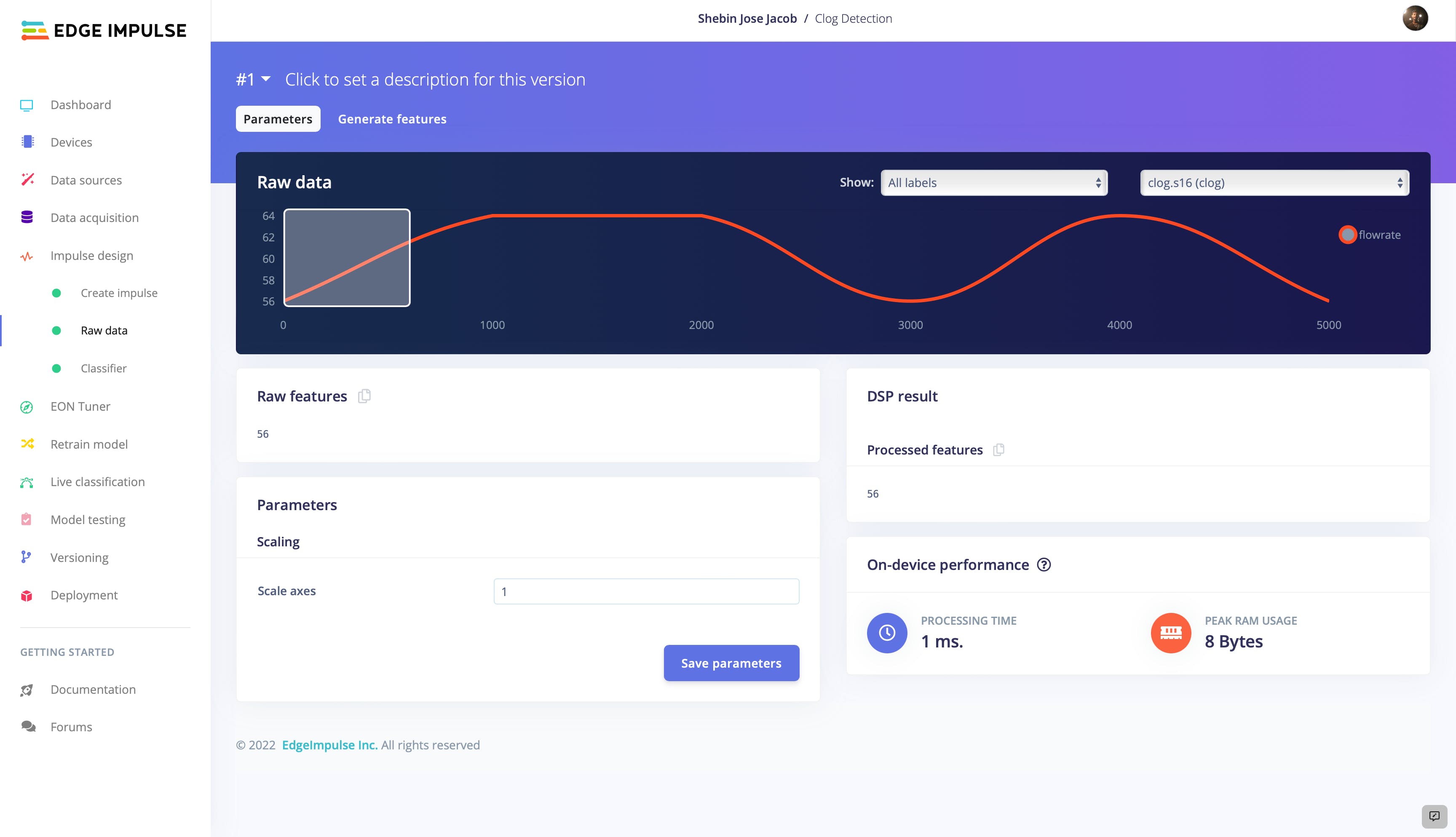
为了生成特征,我们将应用各种算法和技术来识别数据中的重要模式和特征。我们冲动的学习模块将使用这些特征将流量数据分类为三类之一。通过仔细选择和提取相关特征,我们可以创建更准确、更可靠的流量数据分类模型。
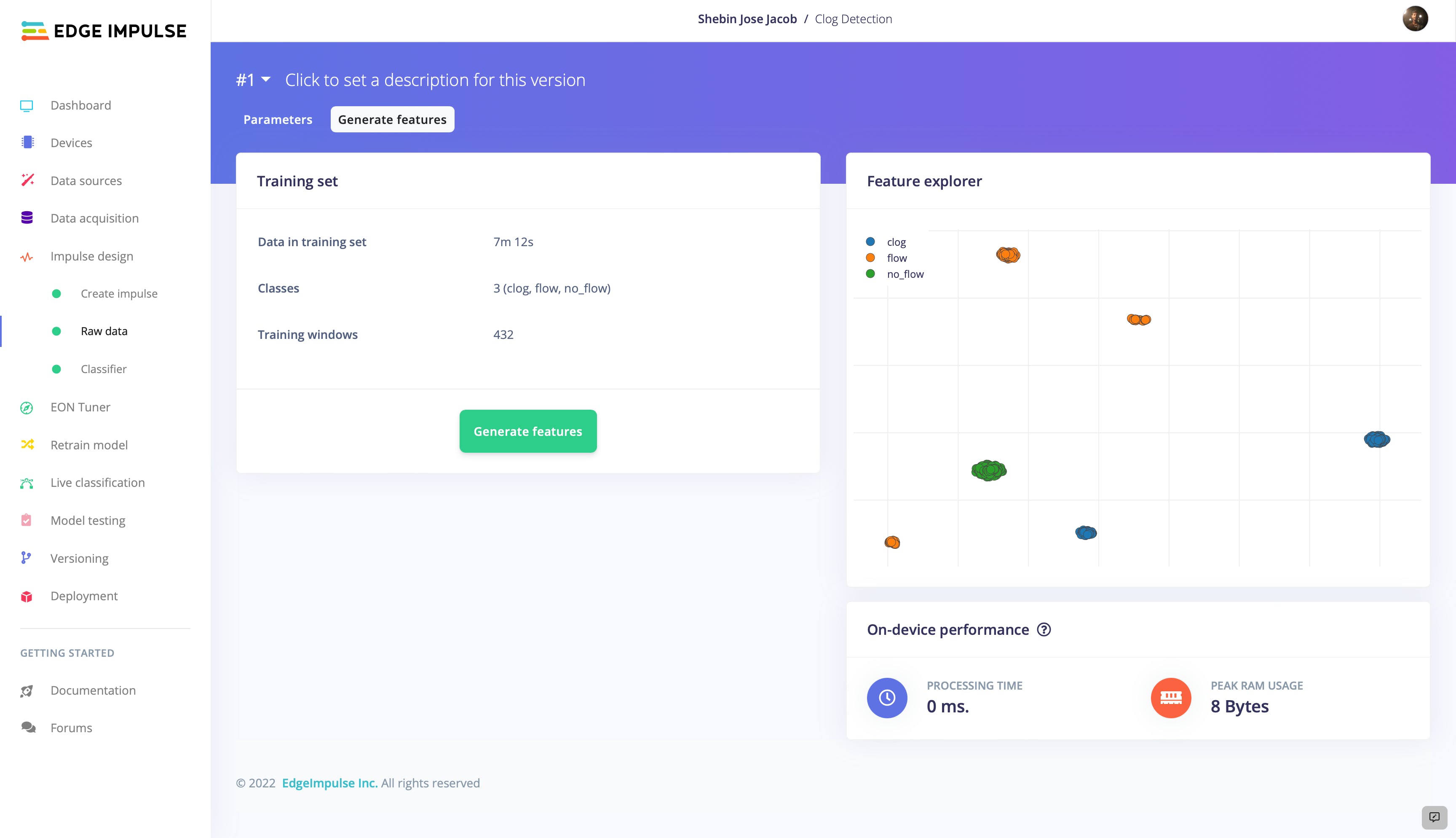
分析特征后,我们确定它们分离良好,类之间没有重叠。这是一个令人鼓舞的迹象,因为它表明我们拥有非常适合模型生成的高质量数据集。
3.模型训练
现在我们已经提取并准备了我们的特征,我们准备好进入分类器选项卡来训练我们的模型。Classifier选项卡提供了几个选项来修改我们模型的行为,包括隐藏层中的神经元数量、学习率和 epoch 数量。
通过反复试验的过程,我们尝试了不同的参数组合,直到我们能够达到符合我们标准的训练精度。这个过程涉及调整隐藏层中的神经元数量、学习率和 epoch 数量等。最终,我们能够找到一组参数,从而生成具有所需训练精度的模型,如图所示。
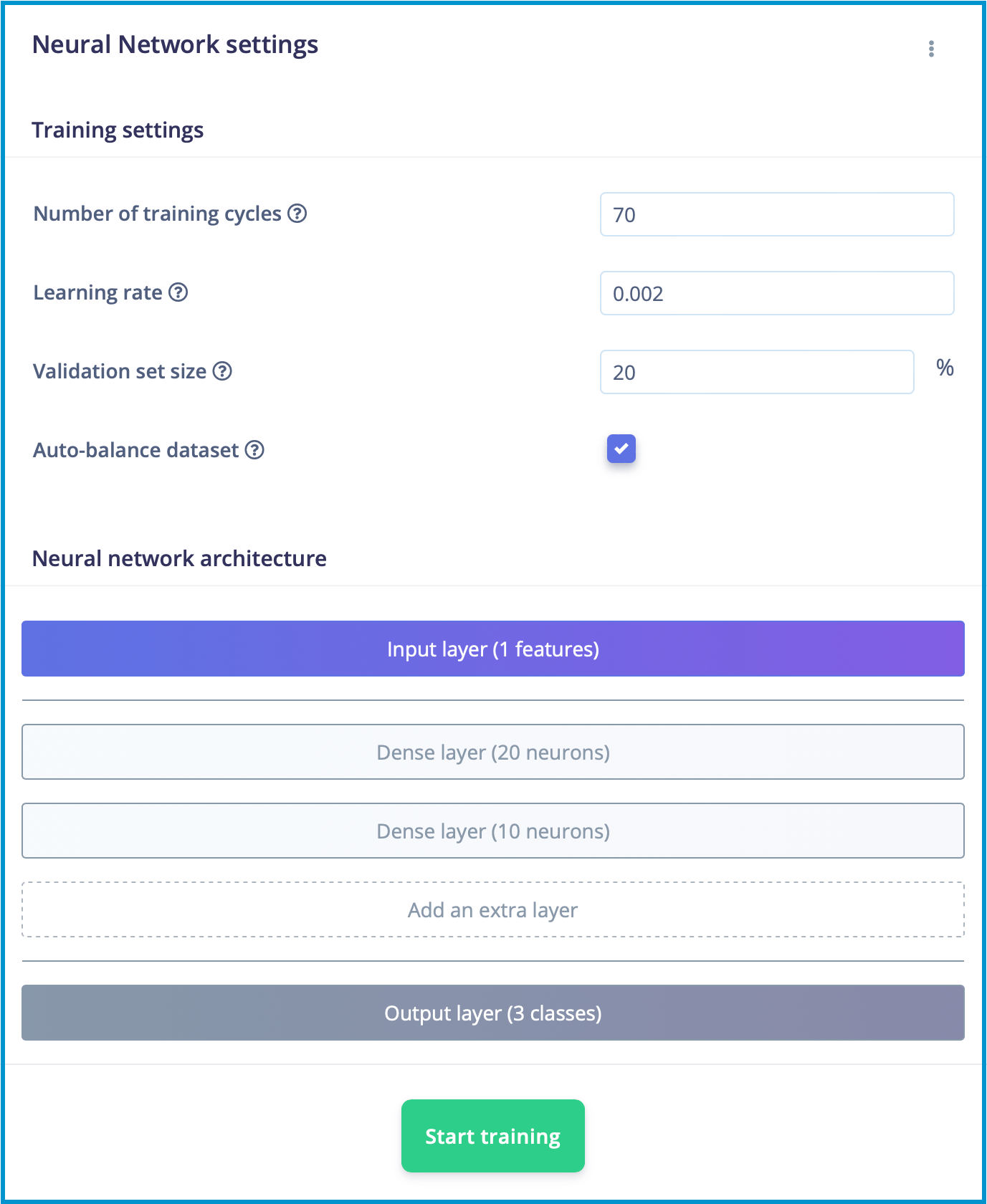
在以 0.002 的学习率对模型进行总共 70 个周期的训练后,我们能够生成具有 100% 训练准确率和 0.03 损失的输出模型。
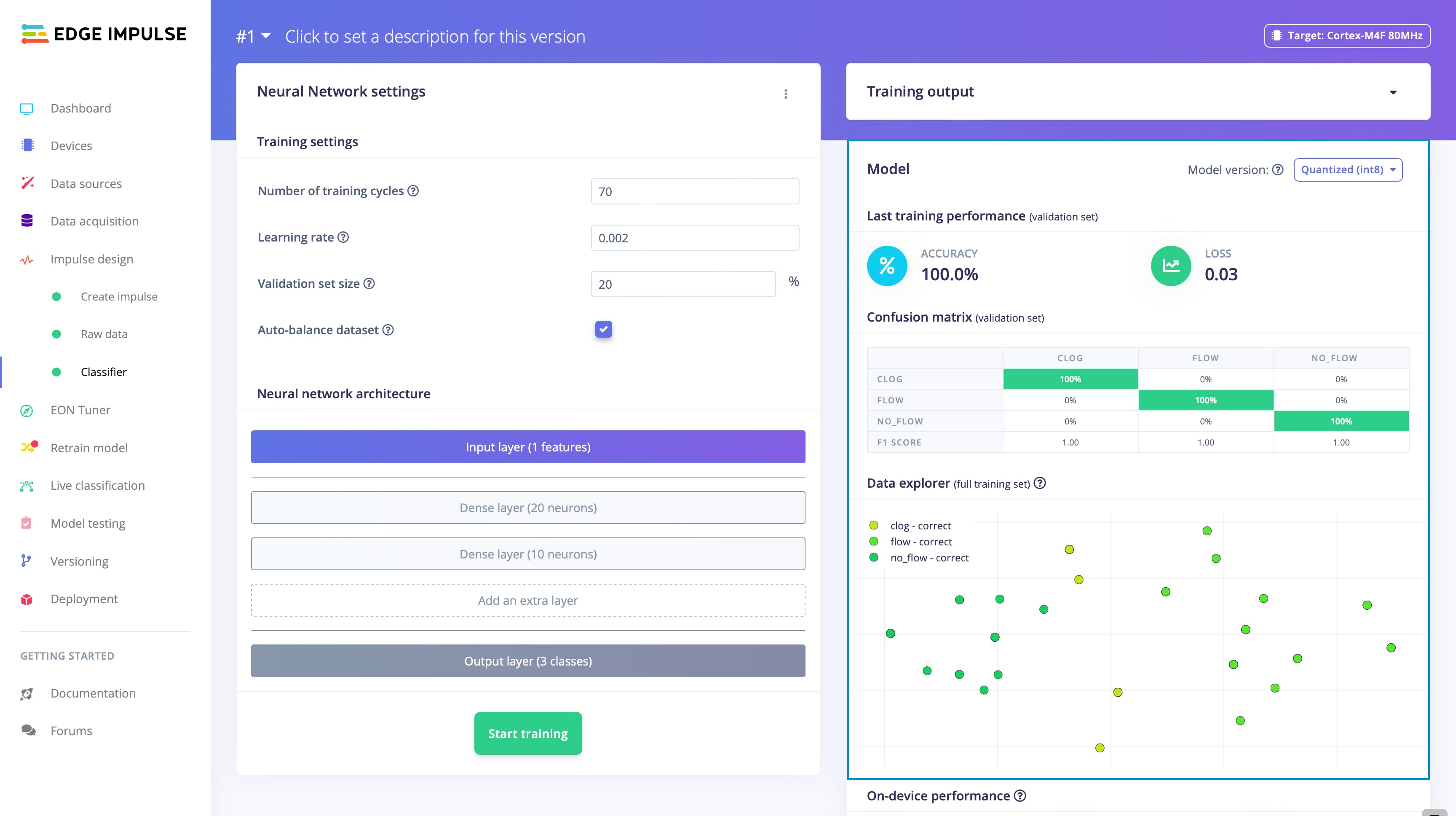
这种准确度非常高,表明我们的模型能够准确地将流量数据分类为三类之一。此外,低损失值表明我们的模型能够以高置信度进行预测,进一步提高了结果的可靠性。
4.模型测试
在训练和微调我们的模型以达到高水平的准确性之后,我们现在准备测试它在一些以前看不见的数据上的性能。为此,我们将导航到“模型测试”选项卡并使用“全部分类”功能来评估模型的性能。
通过将该模型应用于一组新数据,我们可以确定它是否能够准确预测流量模式并将数据分为三类之一。如果该模型在此测试数据上表现良好,我们可以确信它将能够在应用于现实情况时提供有用且可靠的见解。
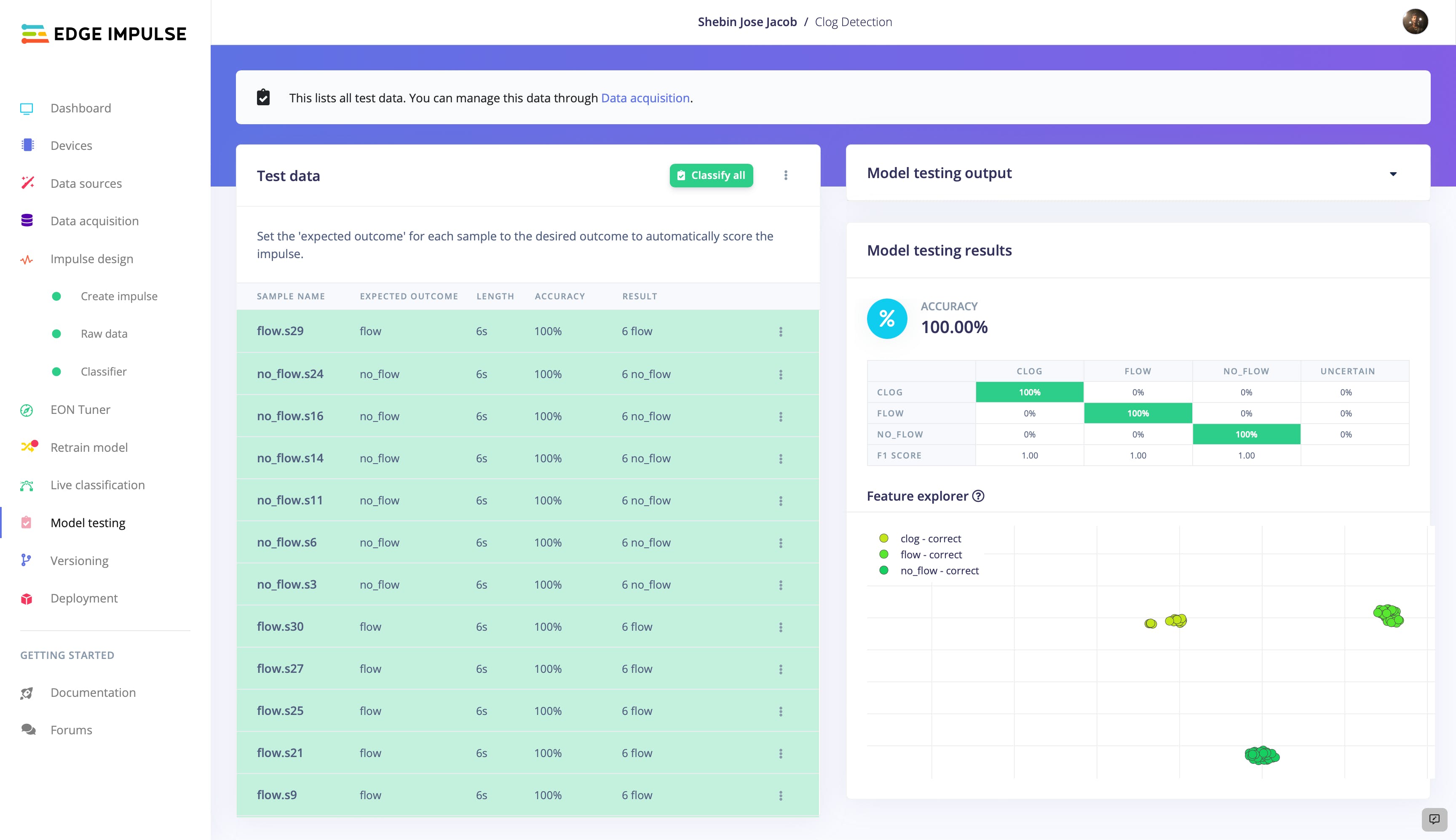
运行测试后,我们很高兴地看到该模型表现异常出色,准确地将流量数据分类为三个类别之一,准确性很高。这些结果有力地表明我们的模型运行良好,能够为工业管道管理提供有价值的见解。
5.部署
现在我们已经创建并测试了一个用于预测和分类工业管道中流速模式的运行良好的模型,我们准备将其部署为Arduino 库。

为此,我们将导航至“部署”选项卡并按照此处提供的说明为我们的模型构建Arduino 库。
在构建库的过程中,我们可以选择使用EON 编译器启用优化。此功能使我们能够通过优化代码以在设备上高效执行来进一步提高模型的性能。虽然这是一个可选步骤,但它对于提高模型的速度和效率很有用,特别是如果我们计划在资源受限的环境中使用它。
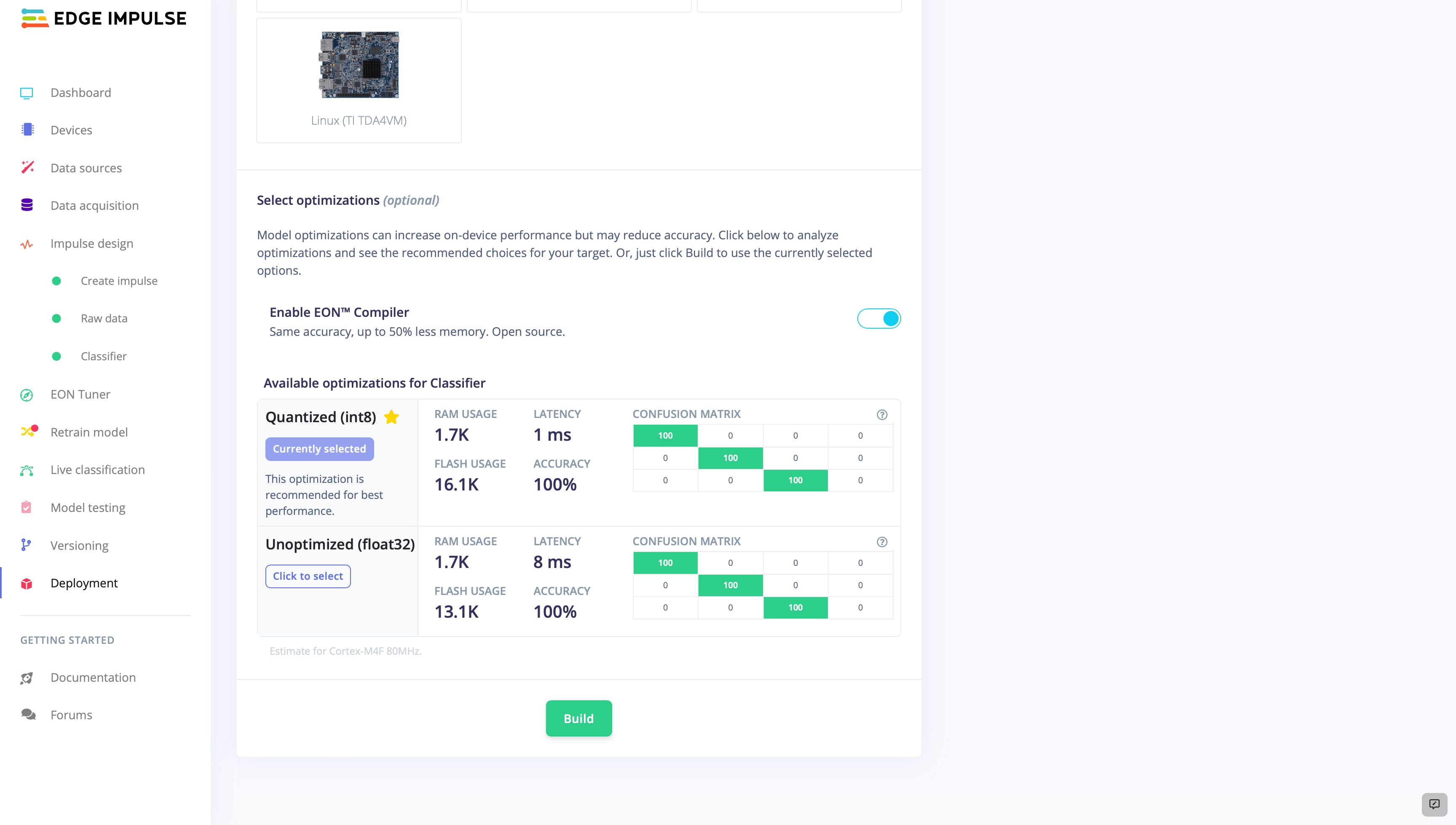
在完成为我们的模型构建 Arduino 库的过程后,我们将看到一个包含模型本身的 .zip 文件,以及一些演示如何在各种环境中使用该模型的示例。要将库添加到 Arduino 集成开发环境 (IDE),我们只需在 IDE 中导航至Sketch > Include Library > Add.ZIP Library ,然后选择构建过程生成的 .zip 文件。这将安装库并使其可用于我们的 Arduino 项目。
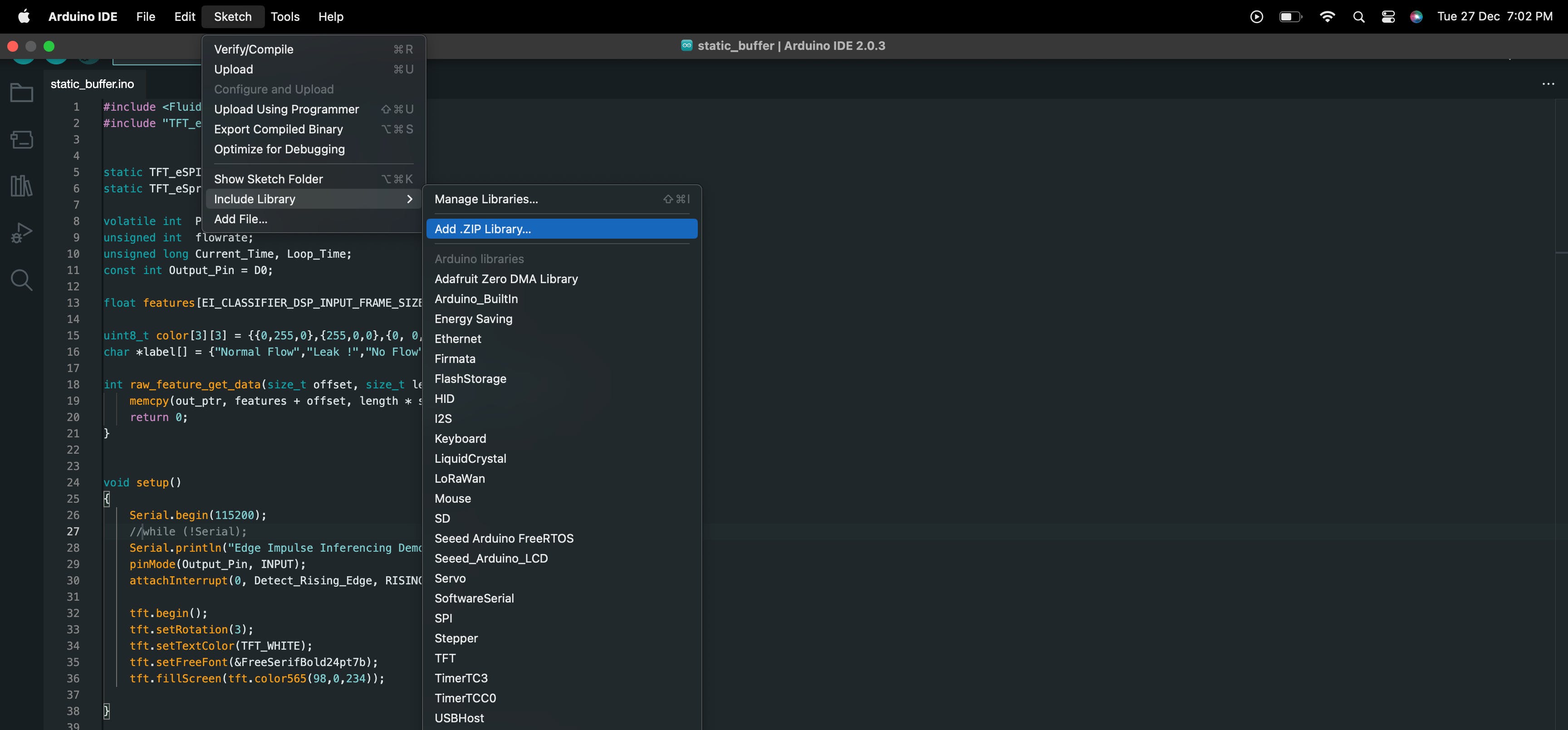
static_buffer.ino为了启用动态推理,我们需要修改位于 Arduino 集成开发环境 (IDE) 中的文件。我们可以首先打开 Arduino IDE 并导航到文件 > 示例 > 您的项目名称 > static_buffer > static_buffer.ino 。
这将static_buffer.ino在编辑器窗口中打开文件,允许我们根据需要更改代码。
动态推理涉及在收到新数据时实时进行预测或分类,因此我们需要修改代码以允许实时数据处理和预测。这可能涉及添加代码来处理传入的数据流,将机器学习算法应用于数据,并根据结果进行预测或分类。我们可能还需要对代码进行其他修改以支持动态推理,具体取决于我们应用程序的具体要求。一旦我们对代码进行了必要的更改,我们就可以保存修改后的文件并使用它对我们的模型进行推理,为工业管道管理提供有价值的见解。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






