
资料下载


视障人士和盲人的图像说明
分享资料个
描述
盲人和视障人士经常遇到各种社会经济挑战,这些挑战可能会阻碍他们独立生活和充分参与社会的能力。然而,机器学习的出现为辅助技术的发展开辟了新的可能性。在这项研究中,我们利用图像字幕和文本转语音技术创建了一种设备,可以帮助视力受损或失明的人。图像字幕与文字转语音技术相结合,可以为视障人士和盲人提供帮助。
此外,我想分享我使用TensorRT优化深度学习模型以缩短其推理时间的经验。有关详细信息,请参阅 TechRxiv 上的预印本,标题为:适用于视障人士和盲人的图像字幕:低资源语言的秘诀。
为简单起见,我们假设一切都已安装。
随着单板计算机 (SBC) 越来越流行用于运行 AI 和深度学习项目,有些甚至专门设计用于运行 AI 和深度学习项目。我们使用来自SeeedStudio (@seeedstudio)的 reComputer NVIDIA Jetson Xavier NX作为我们系统的大脑。reComputer J20 配备 Jetson Xavier NX,可提供高达 21 TOPS 的性能,使其成为嵌入式和边缘系统中高性能计算和 AI 的理想选择。

NVIDIA Jetson 设备紧凑且节能,能够实时执行机器学习算法。然而,在这些内存有限的设备上部署复杂的深度学习模型可能很困难。为了克服这个问题,我们使用了TensorRT等推理优化工具,它使我们能够通过减少内存占用来在边缘设备上执行深度学习模型。
图像描述模型部署管道
我们使用流行的 Microsoft COCO 2014 (COCO) 基准数据集来训练ExpansionNet v2图像描述模型。该数据集由 123, 287 张图像组成,每张图像都有五个人工注释的说明,总共有超过 600, 000 个图像-文本对。我们将数据集拆分为训练(113、287 张图像)、验证(5、000 张图像)和测试(5、000 张图像)集,使用Karpathy拆分策略进行离线评估。为了生成哈萨克语的字幕,我们使用免费提供的谷歌翻译服务翻译了原始的英文字幕。
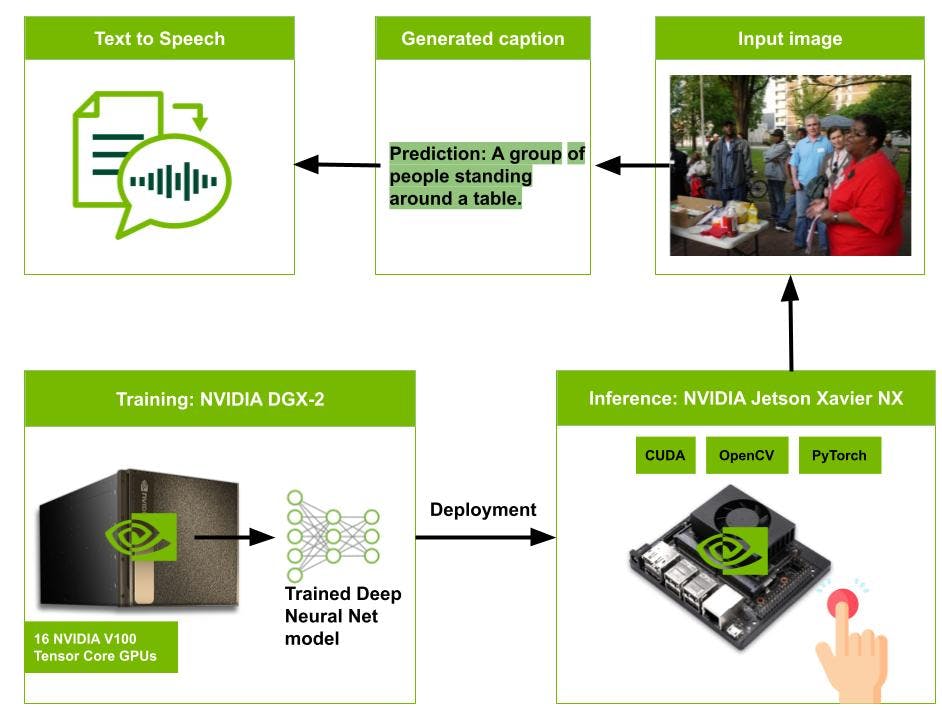
为了训练哈萨克语字幕的模型,我们遵循了ExpansioNet v2的原始工作中定义的模型架构。预训练的 Swin Transformer 被用作骨干网络,从输入图像生成视觉特征。该模型在Nvidia DGX-2 服务器的四个 V100 图形处理单元 (GPU) 上进行训练。
最后,图像字幕模型 ExpansionNet v2 部署在 Nvidia Jetson Xavier NX 板上。按下按钮触发相机捕捉分辨率为 640 × 480 像素的 RGB 图像。然后,将捕获的图像调整为 384 × 384 并传递给 ExpansionNet v2 模型以生成说明。接下来,使用文本到语音模型将生成的字幕文本转换为音频。在我们的研究中,我们利用KazakhTTS模型将哈萨克文本转换为语音。最后,生成的音频通过用户的耳机播放,使盲人或视障人士能够理解他们面前的内容。
ONNX 概述

ONNX 是一种用于机器学习和深度学习模型的开放格式。它允许您将来自不同框架(例如 TensorFlow、PyTorch、MATLAB、Caffe 和 Keras)的深度学习和机器学习模型转换为单一格式。
该工作流程包括以下步骤:
- 将常规 PyTorch 模型文件转换为 ONNX 格式。ONNX 转换脚本可在此处获得。
- 使用 trtexec 实用程序创建 TensorRT 引擎
trtexec --onnx=./model.onnx --saveEngine=./model_fp32.engine --workspace=200
- 从 TensorRT 引擎运行推理。
使用 TensorRT 进行推理优化
TensorRT 是 NVIDIA 开发的高性能深度学习推理引擎。它优化神经网络模型并生成可在 NVIDIA GPU 上运行的高度优化的推理引擎。TensorRT 使用静态和动态优化的组合来实现高性能,包括层融合、内核自动调整和精度校准。
另一方面,PyTorch 是一种流行的深度学习框架,广泛用于研究和开发。PyTorch 提供了一个动态计算图,允许用户动态定义和修改他们的模型,这使得尝试不同的架构和训练方法变得容易。
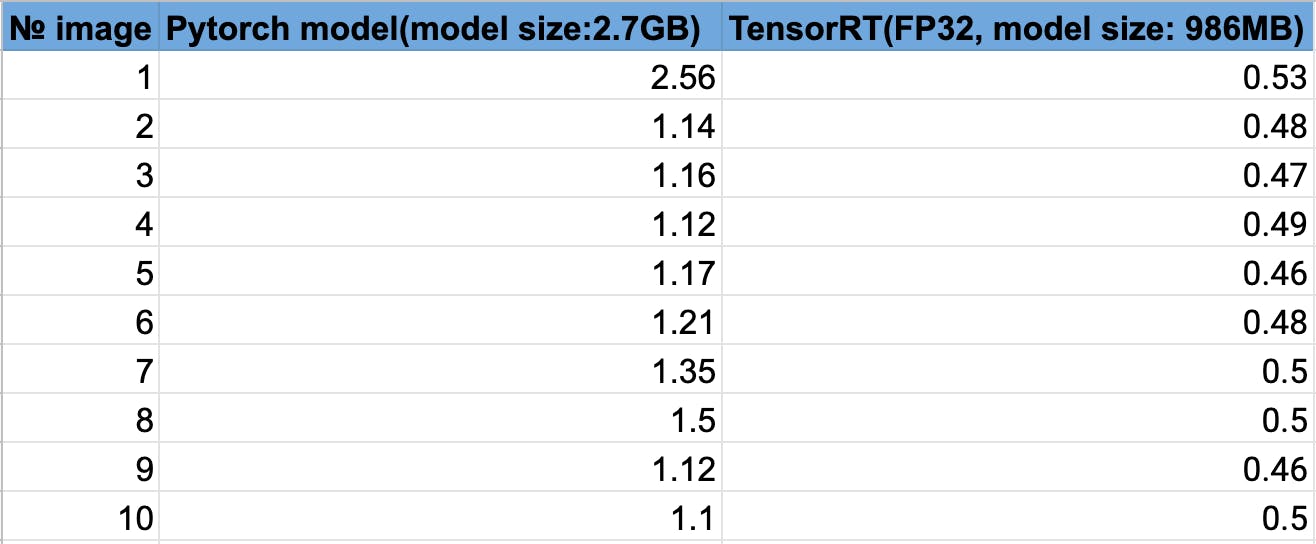
与 PyTorch 模型相比,TensorRT 模型似乎提供了更快的推理结果。与 PyTorch 模型相比,TensorRT 模型处理图像的时间减少了大约 50%,尽管它的文件大小更小。
简而言之,如果速度和效率是您的首要关注点,那么 TensorRT 可能是更好的选择。这对于大多数实时对象检测应用来说已经足够快了。
在推理过程中,您可以使用jetson-stats实用程序检查 Nvidia Jetson 板的当前性能。您可以实时监控模型正在使用的资源,并最大限度地利用硬件。
以佩戴图像字幕辅助设备的人类为对象的真实世界实验
该图说明了我们的图像字幕辅助系统的真实世界实验,该系统包括一个摄像头、一个单板深度学习计算机(Nvidia Jetson Xavier NX)、一个按钮和耳机。

摄像头通过通用串行总线(USB)连接到单板机,按钮和耳机分别连接到单板机的通用输入/输出(GPIO)引脚和音频端口. 摄像头使用可调节的带子固定在用户的额头上,而用户则将单板计算机(和移动电源)放在背包中,并在操作过程中佩戴耳机。
结论和进一步改进
视障人士和盲人在日常生活中面临着独特的挑战,包括无法独立获取视觉信息。图像字幕技术已显示出为该社区提供帮助的希望。
除了现有的图像字幕和文本转语音技术外,我们的目标是将视觉问答 (VQA) 功能整合到我们为视障人士和盲人提供的辅助设备中。这将使用户能够提出有关图像的问题并获得口头答复。
为了进一步优化我们的深度学习模型并提高其性能,我们将执行从 FP32 到 FP16 或 INT8 的量化。这将减少推理所需的内存占用和计算时间,使我们的辅助设备更加高效。
如果您对我们的项目感兴趣,请考虑为我们在github上的存储库加星。多谢!
我希望您发现这项研究有用,并感谢您阅读它。如果您有任何问题或反馈,请在下方发表评论。敬请关注!
致谢
- 该项目得到了智能系统与人工智能研究所工作人员的支持、指导和协助,得以顺利完成。
- Image captioning 模型的实现依赖于ExpansioNet v2。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




