
资料下载


硬件即代码第四部分:嵌入式RAM
杨秀英
分享资料个
描述
正如我在本系列中已经多次提到的那样,消除中央内存瓶颈是构建定制硬件与 CPU 方法相比的性能优势之一。这并不意味着 FPGA 设计从不包含内存;它们通常与外部存储器一起使用。但是,本期的主题是另一种对性能至关重要的内存:嵌入式内存。让我们从一些示例代码开始,然后更多地讨论嵌入式存储器。
如果您是本系列的新手,您可能想回到硬件即代码第 I 部分。
软件更新
在我们进入它之前的最后一件事; 在构建以下示例之前,您需要将 Upduino HLS 工具链更新到最新版本。要进行更新,只需输入以下pio命令(如果您使用的是 Visual Studio Code,请单击左侧的 PlatformIO 图标 (ant) 打开命令提示符,然后选择 Miscellaneous 下的 Platform Core CLI):
> pio platform update upduino_hls
这应该安装最新版本(撰写本文时为 0.2.1)。
简单的感知器
上次,我说过第三部分的例子涉及与神经网络相同类型的计算。下面的示例实现了一个单层神经网络,称为感知器,如您所见,代码非常相似。
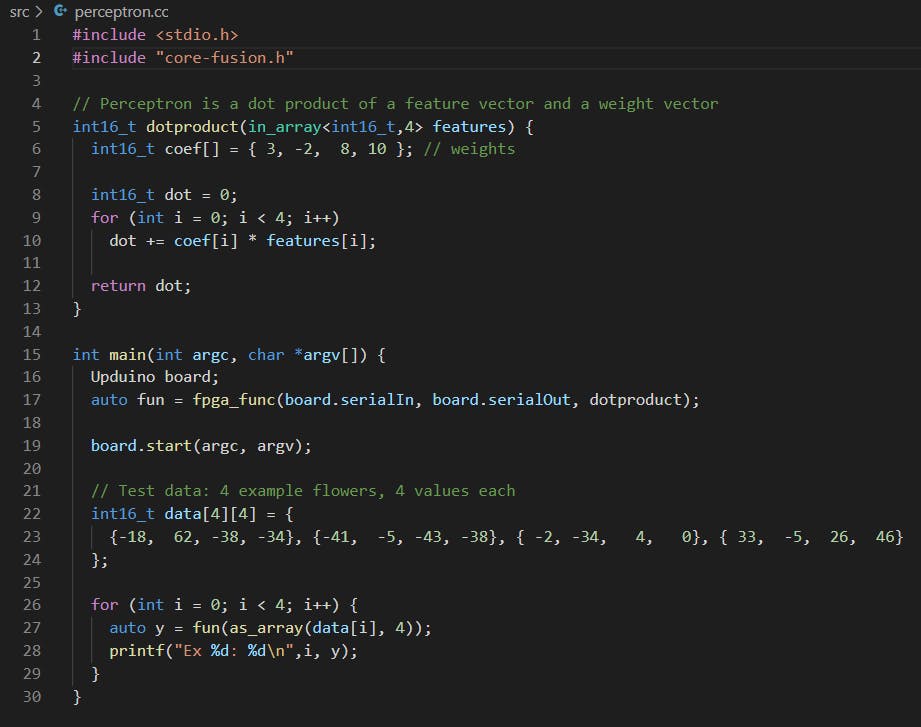
与往常一样,此代码也可从 git 存储库 ( https://github.com/sathibault/hac-examples ) 获得。
这个例子就像 poly-classify第三部分的例子一样进行分类。然而,这次我们从流行的鸢尾花数据集中对花朵进行分类。每朵花都有四个数据值:萼片长度、萼片宽度、花瓣长度和花瓣宽度。在这种情况下,我们对花类型(setosa 或不)进行分类。
运行示例时,您应该得到以下输出:
Ex 0: -822
Ex 1: -837
Ex 2: 94
Ex 3: 777
这显示了四个示例花的感知器输出。输出值小于 0 被预测为 setosa 类型,大于 0 则不是 setosa。四个示例的实际花型是 1) setosa、2) setosa、3) versicolour 和 4) virginica。因此,这与上面的感知器预测完全一致。
阵列和嵌入式存储器
上次的例子和这里的函数的主要区别在于dotproduct数组的使用。Upduino HLS 工具支持我们在这里使用的数组,但您可能想知道in_array,4>第 5 行的类型和第as_array27 行的函数。有时,为 CPU 编写的完全正常的 C/C++ 根本无法提供足够的信息来生成等效的硬件。数组就是这种情况。数组通常作为一个简单的指针在 C/C++ 程序中传递,指向数组所在的中央内存中的某个空间。
在硬件综合的情况下,阵列实际上被映射到嵌入在硬件中的单独的专用存储器。是的,你没看错!FPGA 包含许多称为嵌入式存储器或块 RAM 的小型存储器块。每个数组变量都有专用的内存块来保存该变量的数据。
为了为数组变量生成内存,我们需要知道它的大小,这就是in_array,4>类型的重点。此类型表示参数为输入数组,元素类型为int16_t,数组中的最大数据量为 4。这使得硬件生成器能够分配正确数量的内存块来接收features参数的数据。
在第 27 行,该as_array函数用于构造正确的类型以匹配in_array参数,还用于指示数组中实际有多少数据(与我们从参数类型中知道的最大值相反)。由于此调用在 CPU 上执行,而函数在 FPGA 上执行,因此数据必须从 CPU 发送到 FPGA。因此,我们需要确切地知道要发送多少数据。
这是我们必须遵循某些设计模式才能针对硬件生成的示例之一。不幸的是,确切的机制可能因工具链而异。好消息是这样的情况并不多,而且主体始终相同,即使语法不同。对于数组,原则是我们需要提供一些关于数组的大小信息,我们使用我们正在使用的框架提供的某些类型或函数来做到这一点。
多类感知器
iris 数据集实际上包含三种不同类型的花:setosa、versicolour 和 virginica。percetron 模型可以扩展到多个类,只需每个类使用一个感知器。输出最高的是预测类。下面是一个多类感知器预测鸢尾花类型的实现。
以下示例实现了用于识别三种不同鸢尾花类型的多类感知器。
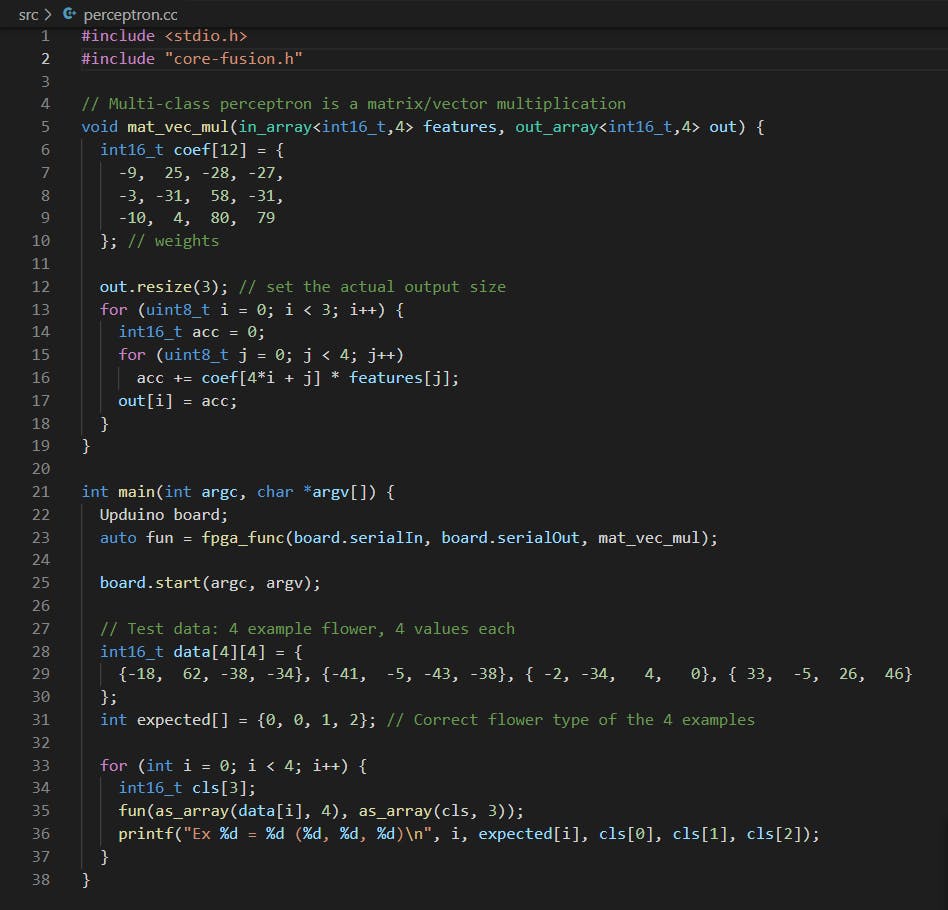
输出应如下所示:
>.\program
Ex 0 = 0 (3694, -3018, -5298)
Ex 1 = 0 (2474, -1038, -6052)
Ex 2 = 1 (-944, 1292, 204)
Ex 3 = 2 (-2392, 138, 5364)
如您所见,每行的最大值与该示例的预期类匹配。
这个例子介绍了另一种数组参数类型out_array(第 5 行)和相应的resize 方法(第 12 行)。此类型的用途与 相同in_array,但表示输出数组参数。因此,它再次向编译器指示要为该数组保留多少空间,即它将拥有的最大元素数。
除了最大数组大小,由于out数据需要从 FPGA 返回到 CPU,系统必须知道数组中实际有多少数据。该resize方法用于指示实际使用了多少元素并需要将其发送回调用者。这些示例都没有使用输入和输出数组,但也可以以inout_array 相同的方式使用模板类型。
您可能想知道的另一件事是为什么不是coef二维数组?那只是因为 Upduino HLS 工具链只支持一维数组。大多数 HLS 工具链都支持多维数组,但我不觉得这个限制特别烦人。指数计算简单;它只是行索引 * 行长度 + 列索引。必须将其写出来有助于您了解所需的算术资源,并且大多数情况下,如果您考虑一下,它可以更有效地完成(提示:使用索引变量,只需 2 次加法,没有乘法)。
表现
关于这些例子,我想说明两个要点。首先是嵌入式内存如何打破内存瓶颈。由于每个数组都有自己的内存,它们是完全独立的,可以同时并行访问!此外,许多 FPGA 的嵌入式存储器有两个端口,这意味着您实际上可以在每个阵列的每个周期访问两个值。这是很多并行性。那么有什么问题呢?再次,我们受到空间的限制。
每个芯片只有固定数量的内存块。内存块由它们可以存储的位数来描述。UPduino 板上的 FPGA 有 30 个块 RAM,每个 RAM 有 4096 位存储。要计算数组的块数,只需将元素数乘以每个元素的位数,然后四舍五入到最接近的块 RAM 大小的倍数。
在 UPduino 上,总比特数为 30 x 4096 = 120Kb = 15KB。这确实是有限的,但这个 FPGA 是可用的最小的之一。大型 FPGA 可以有许多 Mb 的块 RAM。旁注:大多数硬件文档将以位为单位给出内存编号,用小写 b (例如 Kb)编写,而不是通常用大写 B (例如 KB)编写的字节。
第二点是循环帮助我们在空间和速度之间进行权衡。在上一部分中,一切都是并行的,并占用了多个加法器和乘法器。在这一部分中,我们使用了循环,这将花费更多的执行时间,但只使用一个乘法器和一个加法器。这不是全部,不是全部或全部。一个中间选项是部分展开循环以平衡速度与空间的权衡。
这是对你的挑战。上面的多类感知器示例需要按顺序执行的 3 x 4 次迭代(可以并行执行迭代,但这是一个高级主题,稍后才会介绍)。您如何重写此示例以利用嵌入式存储器的并行性并并行计算 3 个输出?
下一步
到目前为止,我们只在相当高的水平上讨论了空间。下一次,我将更深入地介绍 FPGA 内部的内容、如何测量空间、有多少可用空间以及如何准确了解特定功能正在使用多少。
连接
在我发布新的分期付款时,请关注我以保持最新状态。还有一个 Discord 服务器(公共聊天平台),用于您在https://discord.gg/3sA7FHayGH上可能有的任何评论、问题或讨论
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






